Kодирование текстовой информации. Полные уроки — Гипермаркет знаний
Тема
- Kодирование текстовой информации.
Цель
- Познакомить с методами кодирования текстов в памяти компьютера.
Ход урока
В компьютерной области текстом называют последовательность любых символов. На сегодня, машины пользуются набором таких символов, содержащих до 256 знаков.
Причем, каждому соответствует свой восьмиразрядный двоичный код . Таким образом, в памяти компьютера любой символ текста занимает 8 бит или 1 байт.
Имея это ввиду, представляется возможным измерять объем памяти, необходимый для хранения любого текстового документа.
1 бит (двоичная цифра) имеет два значения, добавление каждого разряда в код удваивает количество получаемых комбинаций: 2 бита - четыре варианта, 3 бита - восемь, 4 бита - шестнадцать и т. д.
К примеру, машинописная страница формата А4 содержит приблизительно 55 строк. На каждой из них помещается где-то 60 символов.
Имея такую информацию, мы можем подсчитать количество текстовой информации на данной странице.
Каждый символ - 1 байт информации, а всего символов - 3300 (60 умножаем на 55). Выходит, что на странице объем информации в районе 3 Кбайт.
Двоичные коды и соответствующие им символы связаны таблицей кодировки. Все используемые на ПК таблицы основаны на американском стандарте ASCII4. Он определяет первые 128 кодов (латинские буквы, цифры, знаки). Остальные же 128 используются для спецсимволов и букв национальных алфавитов (русский, китайский, арабский). А, поскольку, общих стандартов для этого не было, возникло много кодировок, в том числе и для кириллицы.
Именно поэтому, иногда можно увидеть чей-то текст в виде набора «закорючек».
Для того, чтобы такие тексты можно было прочитать существуют программы-конверторы . Они заменяют двоичный код каждого символа на код другой кодировки. И, зачастую, пользователь должен указать, из какой в какую кодировки идет преобразование.
Однако уже существуют программы, умеющие автоматически определять кодировку исходного текста.
Итак, таблица, в которой всем символам машинного алфавита поставлены соответственные порядковые номера называется таблица кодировки .
Таблица кодов ASCII
Как уже было сказано, международным стандартом для ПК стала таблица ASCII (Американский стандартный код для информационного обмена).
Также можно встретить и другую таблицу - КОИ-8 (Код обмена информацией), использующаяся в компьютерных сетях.
Таблица кодов ASCII делится на две части .
В международной практике стандартом является лишь первая часть таблицы , то есть, символы с номерами от 0 (00000000), до 127 (01111111). Это строчные и прописные буквы латинского алфавита, цифры, знаки препинания, разного вида скобки, коммерческие и другие символы.
Нумерацию символов от 0 до 31 принято называть управляющими. Они управляют процессом вывода текста на экран или печать, подачей звукового сигнала на акустические колонки, разметкой текста.
Символ 32 – это пробел или пустая позиция в тексте.
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита .
Вторая половина
таблицы ASCII называемая кодовой страницей. Это остальные 128 кодов от 10000000 и до 11111111, имеющие различные варианты, и каждый (!) вариант имеет свой номер.
В первую очередь, кодовая страница используется для размещения национальных алфавитов, отличительных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. Итак для каждого языка отдельно.
Кодировка Unicode
Это 16-разрядная кодировка - в ней на каждый символ отводится по 2 байта памяти.
Соответственно, увеличивается объем занимаемой памяти в 2 раза. Но зато такая кодовая таблица вмещает до 65536 символов.
Полная версия Unicode включает в себя все существующие и вымершие алфавиты мира и множество математических, музыкальных, химических символов.
Программы для работы с текстом
Стремление упростить работу с текстом привело к созданию множества программ, специально созданных для этого - текстовых редакторов.
Текстовый процессор не просто заменитель пишущей машинки, а универсальное средство для работы с текстами.
Они предоставляет очень широкие возможности манипулирования текстовыми документами.
В таких программах можно работать не только с отдельными символами, но и со словами, строками, абзацами, графическими фрагментами
. Кроме таких операций как набор текста, копирование, сохранение, перемещение и удаление фрагментов, изменение шрифта, цвета и размера, отправление текста на диск и печать.
Обрабатываемый текст представляется как бы в виде листков бумаги заданного формата, прокручивающихся на экране.
Преимущества файлового хранения текстов:
1) экономия бумаги
2) компактное размещение
3) возможность мгновенного копирования на другие носители
4) возможность передачи текста по линиям сети или Интернета
Вопросы
1. Что такое таблица кодировки?
2. Какая кодировка стала международным стандартом?
3. Что называется текстовым редактором?
Список использованных источников
1. Урок на тему: «Процесс кодирования текста», Павлов М. С., г. Черкассы
2. Еремин Е.А. Как работает буфер клавиатуры / Информатика № 45, 2004 г.
3. Семакин И.Г.
П ервые 128 символов стандартизированы. Они одинаковы абсолютно во всех кодировках по всему миру. Если говорить о символах, то это весь английский алфавит, цифры и основные знаки. Оставшиеся 128 позиций отданы "на откуп" национальным алфавитам и дополнительным символам. В подавляющем большинстве стран именно так все и есть. Однако в России существует не одна и даже не две национальные кодировки. Их ровно пять. Таким образом, если текст написан по-русски в одной кодировке, то в другой он будет выглядеть абсолютно беспорядочным набором разных знаков.
М ногие читатели данной Вики-статьи наверняка спросят: "Но почему в России так много разных кодировок?". Для ответа на этот вопрос придется совершить небольшой экскурс в историю. Все началось в 70-х годах прошлого века. Именно тогда на наших компьютерах (не персональных - их тогда еще не было) появилась операционная система UNIX. Естественно, ее адаптировали к русскому языку. Именно тогда и возникла первая кодировка, получившая название KOI-8. С тех пор она стала стандартом "де-факто" для всех UNIX-подобных операционных систем - например для Linux.
Н емного позже началось победное шествие персональных компьютеров. А вместе с ними огромное распространение получила операционная система MS-DOS. Ее разработчик, компания Microsoft, во время русификации не воспользовалась KOI-8, а придумала свою кодировку, получившую название DOS (кодовая страница 866). В этой таблице среди дополнительных символов появились элементы рамок, которые значительно облегчали рисование таблиц в различных текстовых редакторах. Это тоже способствовало распространению кодировки DOS. Кстати, примерно в то же время или немного позже на российский рынок вышли компьютеры Macintosh. Естественно, при русификации установленной на них операционной системы была создана еще одна таблица символов - MAC. Правда, нужно отметить, что она практически никогда не использовалась вследствие малого распространения самих "Макинтошей".
В 1990 году компания Microsoft выпустила новую операционную версию Windows 3.0. В ней поддержка национальных языков была встроена. Но вот что интересно - по каким-то причинам специалисты Microsoft не воспользовались уже существующей русской кодировкой DOS, а снова изобрели новую - Win (кодовая страница 1251). Скорее всего, это было сделано из-за введения в таблицу других дополнительных символов вместо рамок и тому подобных символов. Но достоверно о причинах появления кодировки Win мы, скорее всего, уже не узнаем. Еще позже на проблему наличия нескольких национальных кодировок в России и некоторых других странах обратила внимание международная организация International Organization for Standardization, занимающаяся вопросами стандартизации. И опять же, вместо того чтобы за основу взять наиболее распространенную кодировку (на тот момент это была таблица Win), представители ISO выдумали свою (ISO 8859-5). Но практического применения она не получила. И хотя поддержка кодировки ISO есть во всех браузерах, наверное, не существует ни одного сайта, ее использующего.
К роме того, уже достаточно долгое время наблюдаются попытки "проталкивания" универсальной кодировки Unicode. Ее создатели предложили использовать на каждый символ не один, а два байта. Это позволяет увеличивать число возможных значений до 65535 и вместить в таблицу все символы существующих алфавитов. Правда, все эти попытки остаются абсолютно бесплодными.
Следовательно выделим несколько общих черт различия кодировок:
1) Всего существует 256 символов.
2) Первые 128 символов стандартизированы, они одинаковы по всему миру, и состоят из английского алфавита, цифр и знаков.
3) Остальные 128 отданы "на откуп" национальным алфавитам и дополнительным символам.
4) В России 5 различных кодировок!
5) Текст, написанный в одной кодировке на русском языке, в другой кодировке будет выглядеть различными беспорядочными знаками, следовательно, каждая кодировка индивидуальна, и не поддерживает тесного "сотрудничества" с другой кодировкой.
6) Каждая кодировка задается своей собственной кодовой таблицей. Одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
7) Общая черта в основном большинстве кодировки используют на 1 символ ровно 1 байт. Существует кодировка Unicode, где Ее создатели предложили использовать на каждый символ не один, а два байта. Это позволяет увеличивать число возможных значений до 65535 и вместить в таблицу все символы существующих алфавитов. Правда, все эти попытки остаются абсолютно бесплодными.
Различие текстовых файлов, созданных в различных кодировках
К огда текстовый файл закодирован, он сохраняется в соответствии со стандартом кодировки - определенным набором правил, в соответствии с которыми каждому текстовому знаку присваивается числовое значение. Существует множество различных стандартов кодировки, представляющих наборы знаков, используемые в различных языках, причем некоторые из этих стандартов поддерживают только знаки одного языка. Так, для текста на китайском языке может быть использован стандарт кодировки GB2312-80 в случае упрощенного письма и стандарт кодировки Big5 в случае традиционного письма.
П оскольку в Microsoft Word используется стандарт кодировки Юникод (Юникод. Стандарт кодировки знаков, разработанный консорциумом Unicode. Используя для представления каждого знака более одного байта, Юникод позволяет представить в одном наборе знаков почти все языки мира.), то в Microsoft Word можно открывать и сохранять файлы с использованием стандартов кодирования для различных языков. Например, работая с операционной системой, использующей интерфейс на английском языке, в Microsoft Word можно открыть текстовый файл, созданный с использованием стандарта кодировки для греческого или японского языка.
Сожержание
I. История кодирования информации………………………………..3
II. Кодирование информации…………………………………………4
III. Кодирование текстовой информации…………………………….4
IV. Виды таблиц кодировок…………………………………………...6
V. Расчет количества текстовой информации………………………14
Список используемой литературы…………………………………..16
I
.
История кодирования информации
Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были изобретены на различных этапах развития человеческой мысли:
Криптография – это тайнопись, система изменения письма с целью сделать текст непонятным для непосвященных лиц;
Азбука Морзе или неравномерный телеграфный код, в котором каждая буква или знак представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);
Сурдожесты – язык жестов, используемый людьми с нарушениями слуха.
Один из самых первых известных методов шифрования носит имя римского императора Юлия Цезаря (I век до н.э.) . Этот метод основан на замене каждой буквы шифруемого текста, на другую, путем смещения в алфавите от исходной буквы на фиксированное количество символов, причем алфавит читается по кругу, то есть после буквы я рассматривается а. Так слово «байт» при смещении на два символа вправо кодируется словом «гвлф». Обратный процесс расшифровки данного слова – необходимо заменять каждую зашифрованную букву, на вторую слева от неё.
II.
Кодирование информации
Код – это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Обычно каждый образ при кодировании (иногда говорят – шифровке) представлении отдельным знаком.
Знак - это элемент конечного множества отличных друг от друга элементов.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
На компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
III.
Кодирование текстовой информации
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1).
Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы (заглавные или строчные, латинские или русские), но и цифры, знаки препинания, спецсимволы типа "=", "(", "&" и т.п. и даже (обратите особое внимание!) пробелы между словами.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном коде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события): К = 2 I
= 2 8
= 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной символьной информации.
В процессе вывода символа на экран компьютера производится обратный процесс - декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
IV
. Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 (коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
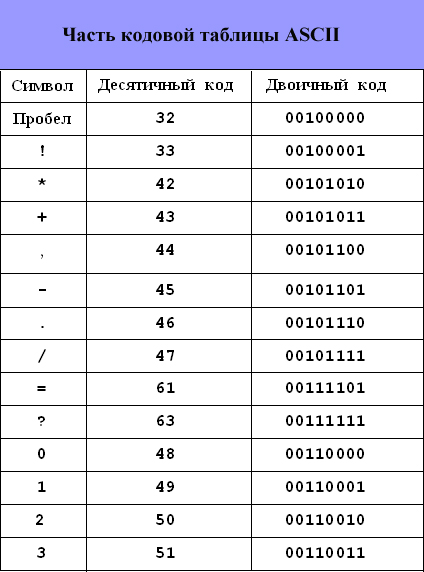
Структура таблицы кодировки ASCII
| Порядковый номер
| Код
| Символ
|
| 0 - 31 | 00000000 - 00011111 | Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
| 32 - 127 | 0100000 - 01111111 | Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 - пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
| 128 - 255 | 10000000 - 11111111 | Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |
Первая половина таблицы кодов ASCII
Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
Вторая половина таблицы кодов ASCII
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 ("Код обмена информацией, 8-битный"). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
От начала 90-х годов, времени господства операционной системы MS DOS, остается кодировка CP866 ("CP" означает "Code Page", "кодовая страница").
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
Кроме того, Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251. Введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение.
С конца 90-х годов проблема стандартизации символьного кодирования решается введением нового международного стандарта, который называется Unicode.
Это 16-разрядная кодировка, т.е. в ней на каждый символ отводится 2 байта памяти. Конечно, при этом объем занимаемой памяти увеличивается в 2 раза. Но зато такая кодовая таблица допускает включение до 65536 символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
Иногда бывает так, что текст, состоящий из букв русского алфавита, полученный с другого компьютера, невозможно прочитать - на экране монитора видна какая-то "абракадабра". Это происходит оттого, что на компьютерах применяется разная кодировка символов русского языка.
Таким образом, каждая кодировка задается своей собственной кодовой таблицей. Как видно из таблицы, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы.
Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ», тогда как в других кодировках это будет бессмысленный набор символов.
К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения.
V
. Расчет количества текстовой информации
Задача 1:
Закодируйте слово “Рим” с помощью таблиц кодировок КОИ8-Р и CP1251.
Решение:
Задача 2:
Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения:
“Мой дядя самых честных правил,
Когда не в шутку занемог,
Он уважать себя заставил
И лучше выдумать не мог.”
Решение:
В данной фразе 108 символов, учитывая знаки препинания, кавычки и пробелы. Умножаем это количество на 8 бит. Получаем 108*8=864 бита.
Задача 3:
Два текста содержат одинаковое количество символов. Первый текст записан на русском языке, а второй на языке племени нагури, алфавит которого состоит из 16 символов. Чей текст несет большее количество информации?
Решение:
1) I = К * а (информационный объем текста равен произведению числа символов на информационный вес одного символа).
2) Т.к. оба текста имеют одинаковое число символов (К), то разница зависит от информативности одного символа алфавита (а).
3) 2 а1
= 32, т.е. а 1
= 5 бит, 2 а2
= 16, т.е. а 2
= 4 бит.
4) I 1
= К * 5 бит, I 2
= К * 4 бит.
5) Значит, текст, записанный на русском языке в 5/4 раза несет больше информации.
Задача 4:
Объем сообщения, содержащего 2048 символов, составил 1/512 часть Мбайта. Определить мощность алфавита.
Решение:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 бит – перевели в биты информационный объем сообщения.
2) а = I / К = 16384 /1024 =16 бит – приходится на один символ алфавита.
3) 2*16*2048 = 65536 символов – мощность использованного алфавита.
Задача 5:
Лазерный принтер Canon LBP печатает со скоростью в среднем 6,3 Кбит в секунду. Сколько времени понадобится для распечатки 8-ми страничного документа, если известно, что на одной странице в среднем по 45 строк, в строке 70 символов (1 символ – 1 байт)?
Решение:
1) Находим количество информации, содержащейся на 1 странице: 45 * 70 * 8 бит = 25200 бит
2) Находим количество информации на 8 страницах: 25200 * 8 = 201600 бит
3) Приводим к единым единицам измерения. Для этого Мбиты переводим в биты: 6,3*1024=6451,2 бит/сек.
4) Находим время печати: 201600: 6451,2 =31 секунда.
Список используемой литературы
1. Агеев В.М. Теория информации и кодирования: дискретизация и кодирование измерительной информации. - М.: МАИ, 1977.
2. Кузьмин И.В., Кедрус В.А. Основы теории информации и кодирования. - Киев, Вища школа, 1986.
3. Простейшие методы шифрования текста/ Д.М. Златопольский. – М.: Чистые пруды, 2007 – 32 с.
4. Угринович Н.Д. Информатика и информационные технологии. Учебник для 10-11 классов / Н.Д.Угринович. – М.: БИНОМ. Лаборатория знаний, 2003. – 512 с.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n