Kódování textových informací. Kompletní lekce – znalostní hypermarket
Předmět
- Kódování textové informace.
cílová
- Seznámit se s metodami kódování textů v paměti počítače.
Během vyučování
V poli počítač je text posloupností libovolných znaků. Dnes stroje používají sadu takových znaků, která obsahuje až 256 znaků.
Navíc má každý svůj vlastní osmibitový binární kód. V paměti počítače tedy jakýkoli znak textu zabírá 8 bitů nebo 1 bajt.
S ohledem na tuto skutečnost se zdá být možné změřit množství paměti potřebné k uložení jakéhokoli textového dokumentu.
1 bit (binární číslice) má dva významy, přidání každého bitu do kódu zdvojnásobí počet získaných kombinací: 2 bity - čtyři možnosti, 3 bity - osm, 4 bity - šestnáct atd.
Například strojopisná stránka formátu A4 obsahuje přibližně 55 řádků. Každý z nich obsahuje asi 60 znaků.
Pomocí těchto informací můžeme spočítat množství textových informací na dané stránce.
Každý znak je 1 bajt informací a celkový počet znaků je 3300 (60 krát 55). Ukazuje se, že množství informací na stránce je kolem 3 KB.
Binární kódy a jejich odpovídající znaky jsou propojeny kódovací tabulkou. Všechny tabulky používané na PC jsou založeny na americkém standardu ASCII4. Definuje prvních 128 kódů ( písmena, čísla, znaky). Zbývajících 128 se používá pro speciální znaky a písmena národních abeced (ruská, čínská, arabská). A protože pro to neexistovaly žádné společné standardy, vzniklo mnoho kódování, včetně azbuky.
To je důvod, proč někdy můžete vidět něčí text ve formě sady "squiggles".
Aby bylo možné takové texty číst, existují převodní programy. Nahrazují binární kód každého znaku kódem jiného kódování. A často musí uživatel specifikovat, ze kterého kódování se konverze provádí.
Existují však již programy, které umí automaticky určit kódování zdrojového textu.
Zavolá se tedy tabulka, ve které jsou všem symbolům strojové abecedy přiřazena odpovídající sériová čísla kódovací tabulka.
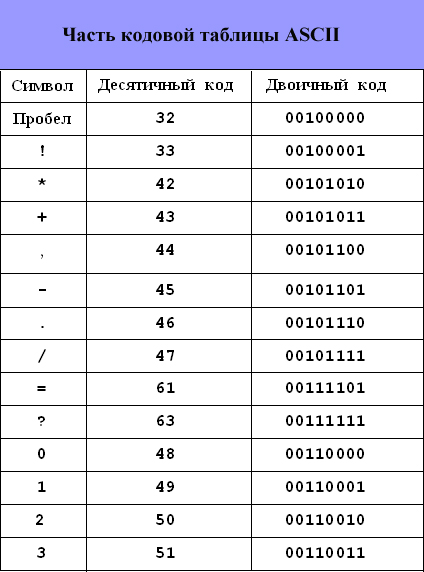
Tabulka ASCII kódů
Jak již bylo zmíněno, ASCII tabulka (American Standard Code for Information Interchange) se stala mezinárodním standardem pro PC.
Najdete zde i další tabulku - KOI-8 (Information Exchange Code), používanou v počítačových sítích.
Tabulka ASCII kódů je rozdělena na dvě části.
V mezinárodní praxi je standard pouze první část tabulky, tedy znaky s čísly od 0 (00000000) do 127 (01111111). Jedná se o malá a velká písmena latinské abecedy, čísla, interpunkční znaménka, jiný druh závorky, obchodní a jiné symboly.
Číslování znaků od 0 do 31 se obvykle nazývá řídicí znaky. Řídí proces zobrazení textu na obrazovce nebo tisku, zvukový signál do reproduktorů a označení textu.
Znak 32 je mezera nebo prázdná pozice v textu.
Upozorňuji na skutečnost, že v tabulce kódování jsou písmena (velká a malá) uspořádána v abecedním pořadí a čísla jsou seřazeny vzestupně podle hodnot. Toto dodržování lexikografického řádu v uspořádání znaků se nazývá princip sekvenčního abecedního kódování.
Druhá polovina ASCII tabulky nazývaná kódová stránka. Jedná se o zbývajících 128 kódů od 10000000 do 11111111, které mají různé možnosti a každá (!) možnost má své číslo.
Nejprve se kódová stránka používá k přizpůsobení národních abeced, které se liší od latinky. V ruském národním kódování jsou v této části tabulky umístěny znaky ruské abecedy. Tedy pro každý jazyk zvlášť.
Unicode kódování
Jedná se o 16bitové kódování – pro každý znak má 2 bajty paměti.
V souladu s tím se množství obsazené paměti zvýší dvakrát. Ale taková kódová tabulka může obsahovat až 65536 znaků.
Plná verze Unicode obsahuje všechny existující a zaniklé abecedy světa a mnoho matematických, hudebních a chemických symbolů.
Programy pro práci s textem
Touha zjednodušit práci s textem vedla k vytvoření mnoha programů speciálně k tomu určených – textových editorů.
Textový procesor není jen náhradou psacího stroje, ale univerzálním nástrojem pro práci s texty.
Poskytují velmi široké možnosti pro manipulaci s textovými dokumenty.
V takových programech můžete pracovat nejen s jednotlivými postavami, ale i s slova, řádky, odstavce, grafika. Kromě takových operací, jako je psaní, kopírování, ukládání, přesouvání a mazání fragmentů, změna písma, barvy a velikosti, odesílání textu na disk a tisk.
Zpracovaný text je prezentován jakoby ve formě listů papíru daného formátu, rolujících na obrazovce.
Výhody ukládání textů do souborů:
1) šetřete papírem
2) kompaktní umístění
3) možnost okamžitého kopírování na jiná média
4) schopnost přenášet text přes linky sítě nebo internetu
Otázky
1. Co je kódovací tabulka?
2. Jaké kódování se stalo mezinárodním standardem?
3. Co se nazývá textový editor?
Seznam použitých zdrojů
1. Lekce na téma: „Proces kódování textu“, Pavlov M. S., Cherkasy
2. Eremin E.A. Jak funguje vyrovnávací paměť klávesnice / Informatika #45, 2004
3. Semakin I.G.
P Prvních 128 znaků je standardizovaných. Jsou stejné absolutně ve všech kódováních po celém světě. Pokud mluvíme o symbolech, pak je to celá anglická abeceda, čísla a základní znaky. Zbývajících 128 pozic bylo dáno „na milost a nemilost“ národním abecedám a dalším znakům. Tak je to v drtivé většině zemí. V Rusku však neexistuje jedno nebo dokonce dvě národní kódování. Je jich přesně pět. Pokud je tedy text napsán v ruštině v jednom kódování, pak v jiném bude vypadat jako naprosto náhodná sada různých znaků.
M Mnoho čtenářů tohoto článku na Wiki se pravděpodobně zeptá: "Ale proč je v Rusku tolik různých kódování?". Chcete-li odpovědět na tuto otázku, budete muset udělat krátkou odbočku do historie. Vše začalo v 70. letech minulého století. Tehdy se na našich počítačích objevil operační systém UNIX (ne osobních – tehdy ještě neexistovaly). Přirozeně byl přizpůsoben ruskému jazyku. Tehdy se objevilo první kódování nazvané KOI-8. Od té doby se stal „de facto“ standardem pro všechny UNIXové operační systémy- například pro Linux.
H o něco později začalo vítězné tažení osobních počítačů. A spolu s nimi se velmi rozšířil operační systém MS-DOS. Jeho vývojář, Microsoft, při rusifikaci nepoužil KOI-8, ale přišel s vlastním kódováním, nazvaným DOS (kódová stránka 866). V této tabulce se mezi doplňkovými znaky objevily rámové prvky, které značně usnadnily kreslení tabulek v různých textových editorech. To také přispělo k rozšíření kódování DOS. Mimochodem, přibližně ve stejnou dobu nebo o něco později ruský trh Vyšly počítače Macintosh. Přirozeně, během rusifikace operačního systému na nich nainstalovaného, byla vytvořena další tabulka symbolů - MAC. Pravda, nutno podotknout, že se kvůli malé distribuci samotných Maců téměř nepoužíval.
V V roce 1990 společnost Microsoft vydala nový operační systém Verze Windows 3.0. Byla do něj zabudována podpora národních jazyků. Ale tady je to zajímavé - specialisté Microsoftu z nějakého důvodu nepoužili již existující ruské kódování DOS, ale opět vymysleli nové - Win (kódová stránka 1251). S největší pravděpodobností k tomu došlo kvůli zavedení dalších doplňkových znaků do tabulky namísto rámců a podobných znaků. S největší pravděpodobností se ale s jistotou nedozvíme o důvodech vzhledu kódování Win. Ještě později mezinárodní organizace International Organization for Standardization, zabývající se problematikou standardizace, upozornila na problém přítomnosti několika národních kódování v Rusku a některých dalších zemích. A opět, místo aby si za základ vzali nejběžnější kódování (tehdy to byla tabulka Win), zástupci ISO vymysleli vlastní (ISO 8859-5). Ale praktická aplikace neobdržela. A přestože kódování ISO je podporováno ve všech prohlížečích, pravděpodobně neexistuje jediný web, který by jej používal.
NA Poměrně dlouhou dobu jsou navíc pozorovány pokusy o „protlačení“ univerzálního kódování Unicode. Jeho tvůrci navrhli použít ne jeden, ale dva bajty pro každou postavu. To vám umožní zvýšit počet možných hodnot až na 65535 a vejít do tabulky všechny znaky existujících abeced. Je pravda, že všechny tyto pokusy zůstávají naprosto bezvýsledné.
Proto zdůrazňujeme několik společných rysů rozdílů v kódování:
1) Celkem je 256 znaků.
2) Prvních 128 znaků je standardizovaných, jsou stejné na celém světě a sestávají z anglické abecedy, čísel a znaků.
3) Zbývajících 128 je dáno „na milost a nemilost“ národním abecedám a dalším znakům.
4) V Rusku existuje 5 různých kódování!
5) Text napsaný v jednom kódování v ruštině, v jiném kódování, bude vypadat jako různé náhodné znaky, proto je každé kódování individuální a nepodporuje úzkou „spolupráci“ s jiným kódováním.
6) Každé kódování je specifikováno vlastní tabulkou kódů. Ke stejnému binární kód PROTI různá kódování jsou přiřazeny různé symboly.
7) Společný rys ve většině kódování je použit pro 1 znak přesně 1 bajt. Existuje kódování Unicode, kde Jeho tvůrci navrhli použít ne jeden, ale dva bajty pro každý znak. To vám umožní zvýšit počet možných hodnot až na 65535 a vejít do tabulky všechny znaky existujících abeced. Je pravda, že všechny tyto pokusy zůstávají naprosto bezvýsledné.
Rozdíl mezi textovými soubory vytvořenými v různých kódováních
NA Když je textový soubor zakódován, uloží se podle standardu kódování, specifické sady pravidel, která každému textovému znaku přiřadí číselnou hodnotu. Existuje mnoho různých standardů kódování, které představují znakové sady používané v různých jazycích, a některé z těchto standardů podporují pouze znaky z jednoho jazyka. Takže pro čínský text lze použít standard kódování GB2312-80 v případě zjednodušeného psaní a standard kódování Big5 v případě tradičního psaní.
P Protože Microsoft Word používá standard kódování Unicode (Unicode. Standard kódování znaků vyvinutý konsorciem Unicode. Díky použití více než jednoho bajtu k reprezentaci každého znaku vám Unicode umožňuje reprezentovat téměř všechny světové jazyky v jedné znakové sadě.) , můžete otevírat a ukládat soubory Microsoft Word pomocí standardů kódování pro různé jazyky. Například při práci s operačním systémem, který používá rozhraní zap anglický jazyk, můžete otevřít textový soubor v aplikaci Microsoft Word, který byl vytvořen pomocí standardu kódování pro řečtinu nebo japonštinu.
Obsah
I. Historie kódování informací………………………………..3
II. Kódovací informace ……………………………………………… 4
III. Kódování textových informací………………………………….4
IV. Typy kódovacích tabulek………………………………………………....6
V. Výpočet množství textových informací………………………14
Seznam použité literatury………………………………………..16
já
.
Historie kódování informací
Lidstvo používá textové šifrování (kódování) od okamžiku, kdy se objevily první tajné informace. Zde je několik technik kódování textu, které byly vynalezeny v různých fázích vývoje lidského myšlení:
Kryptografie je kryptografie, systém měnícího se písma, aby byl text pro nezasvěcené osoby nesrozumitelný;
Morseova abeceda nebo nejednotný telegrafní kód, ve kterém je každé písmeno nebo znak reprezentován vlastní kombinací krátkých základních balíčků elektrický proud(tečky) a elementární parcely trojnásobného trvání (čárky);
Znakový jazyk je znakový jazyk používaný lidmi se sluchovým postižením.
Jedna z nejstarších známých šifrovacích metod nese jméno římského císaře Julia Caesara (1. století před naším letopočtem). Tato metoda je založena na nahrazení každého písmene zašifrovaného textu jiným tak, že se abeceda od původního písmene posune o pevný počet znaků a abeceda se čte v kruhu, tedy za písmenem i se uvažuje a. Takže slovo "byte" při posunutí o dva znaky doprava je zakódováno slovem "gvlf". Opačným procesem dešifrování daného slova je nahrazení každého zašifrovaného písmene druhým nalevo od něj.
II.
Kódování informací
Kód je soubor konvencí (nebo signálů) pro záznam (nebo přenos) některých předem definovaných konceptů.
Kódování informací je proces vytváření určité reprezentace informace. V užším slova smyslu je pojem „kódování“ často chápán jako přechod od jedné formy prezentace informace k jiné, vhodnější pro ukládání, přenos nebo zpracování.
Obvykle je každý obrázek, když je zakódován (někdy se říká - zašifrovaný), reprezentován samostatným znakem.
Znak je prvkem konečného souboru odlišných prvků.
V užším slova smyslu je pojem „kódování“ často chápán jako přechod od jedné formy prezentace informace k jiné, vhodnější pro ukládání, přenos nebo zpracování.
Počítač umí zpracovávat textové informace. Při zadávání do počítače je každé písmeno zakódováno určitým číslem a při výstupu na externí zařízení (obrazovka nebo tisk) se pro lidské vnímání vytvářejí obrázky písmen pomocí těchto čísel. Korespondence mezi sadou písmen a čísel se nazývá kódování znaků.
Všechna čísla v počítači jsou zpravidla reprezentována nulami a jedničkami (a nikoli deseti číslicemi, jak je u lidí zvykem). Jinými slovy, počítače obvykle pracují v binárním systému, protože zařízení pro jejich zpracování jsou mnohem jednodušší. Zadávání čísel do počítače a jejich výstup pro čtení člověkem lze provádět v obvyklém desítkovém tvaru a všechny potřebné převody provádějí programy běžící na počítači.
III.
Kódování textových informací
Stejné informace mohou být prezentovány (zakódovány) v několika formách. S příchodem počítačů bylo nutné zakódovat všechny typy informací, kterými se jednotlivec i lidstvo jako celek zabývá. Ale lidstvo začalo řešit problém kódování informací dávno před příchodem počítačů. Velkolepé úspěchy lidstva – psaní a aritmetika – nejsou nic jiného než systém kódování řeči a číselné informace. Informace se nikdy neobjeví čistá forma, je vždy nějak reprezentován, nějak zakódován.
Binární kódování je jedním z nejběžnějších způsobů reprezentace informací. V počítačích, robotech a obráběcích strojích s numerickým řízením jsou zpravidla všechny informace, se kterými zařízení pracuje, zakódovány ve formě slov binární abecedy.
Od konce 60. let 20. století se počítače stále častěji používají pro zpracování textu a nyní se většina světových osobních počítačů (a většina zčas) je zaneprázdněn zpracováním textových informací. Všechny tyto typy informací jsou v počítači reprezentovány binárním kódem, tj. používá se abeceda s mocninou dvě (pouze dva znaky 0 a 1). To je způsobeno skutečností, že je vhodné reprezentovat informace ve formě sekvence elektrických impulsů: neexistuje impuls (0), existuje impuls (1).
Takové kódování se obvykle nazývá binární a samotné logické sekvence nul a jedniček se nazývají strojový jazyk.
Z pohledu počítače se text skládá z jednotlivých znaků. Znaky zahrnují nejen písmena (velká nebo malá písmena, latinka nebo ruština), ale také číslice, interpunkční znaménka, speciální znaky jako "=", "(", "&" atd.) a dokonce (věnujte zvláštní pozornost!) mezery mezi slovy .
Texty se zadávají do paměti počítače pomocí klávesnice. Klávesy jsou psány nám známými písmeny, číslicemi, interpunkčními znaménky a dalšími symboly. Zadávají RAM v binárním kódu. To znamená, že každý znak je reprezentován 8bitovým binárním kódem.
Tradičně se pro zakódování jednoho znaku používá množství informací rovné 1 bajtu, tj. I \u003d 1 byte \u003d 8 bitů. Pomocí vzorce, který dává do souvislosti počet možných událostí K a množství informací I, můžete vypočítat, kolik různých znaků lze zakódovat (za předpokladu, že znaky jsou možné události): K \u003d 2 I
= 2 8
= 256, tj. k reprezentaci textových informací lze použít abecedu s kapacitou 256 znaků.
Tento počet znaků je dostatečný pro reprezentaci textových informací, včetně velkých a malých písmen ruské a latinské abecedy, čísel, znaků, grafických symbolů atd.
Kódování spočívá v tom, že každému znaku je přiřazen jedinečný desetinný kód od 0 do 255 nebo odpovídající binární kód od 00000000 do 11111111. Člověk tedy rozlišuje znaky podle jejich stylu a počítač podle jejich kódu.
Pohodlí bajtového kódování znaků je zřejmé, protože bajt je nejmenší adresovatelná část paměti, a proto může procesor při zpracování textu přistupovat ke každému znaku zvlášť. Na druhou stranu je 256 znaků dostačující pro reprezentaci široké škály informací o znacích.
V procesu zobrazení znaku na obrazovce počítače se provádí opačný proces - dekódování, tedy převod znakového kódu na jeho obraz. Je důležité, aby přiřazení konkrétního kódu k symbolu bylo věcí dohody, která je pevně stanovena v tabulce kódů.
Nyní vyvstává otázka, který osmibitový binární kód vložit do korespondence s každým znakem. Je jasné, že jde o podmíněnou záležitost, můžete přijít na mnoho způsobů kódování.
Všechny znaky počítačové abecedy jsou číslovány od 0 do 255. Každému číslu odpovídá osmibitový binární kód od 00000000 do 11111111. Tento kód je jednoduše pořadové číslo znaku v binární číselné soustavě.
IV
. Typy kódovacích tabulek
Tabulka, ve které jsou všem znakům počítačové abecedy přiřazena pořadová čísla, se nazývá kódovací tabulka.
Pro odlišné typy Počítač používá různé kódovací tabulky.
Jako mezinárodní standard je přijata kódová tabulka ASCII (American Standard Code for Information Interchange), která kóduje první polovinu znaků číselnými kódy od 0 do 127 (kódy od 0 do 32 nejsou přiřazeny znakům, ale funkčním klávesám).
Tabulka ASCII kódů je rozdělena na dvě části.
Mezinárodním standardem je pouze první polovina tabulky, tzn. znaky s čísly od 0 (00000000) do 127 (01111111).
Struktura kódovací tabulky ASCII
| Sériové číslo | Kód | Symbol |
| 0 - 31 | 00000000 - 00011111 | Znaky s čísly od 0 do 31 se nazývají řídicí znaky. Jejich funkcí je řídit proces zobrazování textu na obrazovce nebo tisku, vydávání zvukového signálu, označování textu atd. |
| 32 - 127 | 0100000 - 01111111 | Standardní část tabulky (anglicky). To zahrnuje malá a velká písmena latinské abecedy, desetinné číslice, interpunkční znaménka, všechny druhy hranatých závorek, obchodní a další symboly. Znak 32 je mezera, tzn. prázdné místo v textu. Vše ostatní se odráží v určitých znameních. |
| 128 - 255 | 10000000 - 11111111 | Alternativní část tabulky (ruština). Druhá polovina tabulky kódů ASCII, nazývaná kódová stránka (128 kódů počínaje 10000000 a končící 11111111), může mít různé možnosti, každá možnost má své vlastní číslo. Kódová stránka se primárně používá k umístění jiných národních písem než latinky. V ruském národním kódování jsou v této části tabulky umístěny znaky ruské abecedy. |
První polovina tabulky kódů ASCII
Je třeba věnovat pozornost skutečnosti, že v tabulce kódování jsou písmena (velká a malá písmena) uspořádána v abecedním pořadí a čísla jsou seřazeny vzestupně. Toto dodržování lexikografického řádu v uspořádání znaků se nazývá princip sekvenčního kódování abecedy.
U písmen ruské abecedy je také dodržován princip sekvenčního kódování.
Druhá polovina tabulky kódů ASCII
Bohužel v současné době existuje pět různých kódování azbuky (KOI8-R, Windows, MS-DOS, Macintosh a ISO). Z tohoto důvodu často vznikají problémy s přenosem ruského textu z jednoho počítače do druhého, z jednoho softwarového systému do druhého.
Chronologicky byl jedním z prvních standardů pro kódování ruských písmen na počítačích KOI8 ("Information Exchange Code, 8-bit"). Toto kódování se používalo již v 70. letech na počítačích řady počítačů EC a od poloviny 80. let se začalo používat v prvních rusifikovaných verzích operačního systému UNIX.
Od počátku 90. let, doby dominance operačního systému MS DOS, zůstává kódování CP866 ("CP" znamená "Code Page", "code page").
Počítače Apple s operačním systémem Mac OS používají vlastní kódování Mac.
Kromě toho Mezinárodní organizace pro normalizaci (International Standards Organization, ISO) schválila další kódování nazvané ISO 8859-5 jako standard pro ruský jazyk.
Nejběžnějším aktuálně používaným kódováním je Microsoft Windows, zkráceně CP1251. Představený společností Microsoft; s přihlédnutím rozšířený operační systémy (OS) a další softwarové produkty této společnosti v Ruská Federace se to rozšířilo.
Od konce 90. let byl problém standardizace kódování znaků řešen zavedením nového mezinárodního standardu nazvaného Unicode.
Jedná se o 16bitové kódování, tzn. má 2 bajty paměti na znak. V tomto případě se samozřejmě množství obsazené paměti zvýší dvakrát. Ale taková kódová tabulka umožňuje zahrnutí až 65536 znaků. Kompletní specifikace standardu Unicode zahrnuje všechny existující, zaniklé a uměle vytvořené abecedy světa a také mnoho matematických, hudebních, chemických a dalších symbolů.
Vnitřní reprezentace slov v paměti počítače
pomocí ASCII tabulky
Někdy se stává, že text, který se skládá z písmen ruské abecedy, přijatý z jiného počítače, nelze přečíst - na obrazovce monitoru je vidět nějaký druh "abracadabra". To je způsobeno skutečností, že počítače používají různá kódování znaků ruského jazyka.
Každé kódování je tedy specifikováno vlastní kódovou tabulkou. Jak je vidět z tabulky, stejnému binárnímu kódu jsou přiřazeny různé znaky v různých kódováních.
Například sekvence číselných kódů 221, 194, 204 v kódování CP1251 tvoří slovo „počítač“, zatímco v jiných kódováních se bude jednat o nicneříkající sadu znaků.
Naštěstí se ve většině případů uživatel nemusí starat o překódování textových dokumentů, protože to zajišťují speciální převodní programy zabudované v aplikacích.
PROTI
. Výpočet množství textových informací
Úkol 1:
Kódujte slovo „Řím“ pomocí kódovacích tabulek KOI8-R a CP1251.
Řešení:
Úkol 2:
Za předpokladu, že každý znak je zakódován jedním bajtem, odhadněte objem informací následující věty:
"Můj strýc nejčestnějších pravidel,
Když jsem vážně onemocněl,
Přinutil se respektovat
A lepší mě nenapadl."
Řešení:
Tato fráze má 108 znaků, včetně interpunkčních znamének, uvozovek a mezer. Toto číslo vynásobíme 8 bity. Dostaneme 108*8=864 bitů.
Úkol 3:
Oba texty obsahují stejný počet znaků. První text je napsán v ruštině a druhý v jazyce kmene Naguri, jehož abeceda se skládá ze 16 znaků. Čí text obsahuje více informací?
Řešení:
1) I \u003d K * a (informační objem textu se rovná součinu počtu znaků a informační váhy jednoho znaku).
2) Protože oba texty mají stejný počet znaků (K), pak rozdíl závisí na informačním obsahu jednoho znaku abecedy (a).
3) 2 a1
= 32, tzn. 1
= 5 bitů, 2 a2
= 16, tzn. a 2
= 4 bity.
4) Já 1
= K * 5 bitů, I 2
= K * 4 bity.
5) Znamená to, že text psaný v ruštině nese 5/4krát více informací.
Úkol 4:
Objem zprávy obsahující 2048 znaků byl 1/512 MB. Určete sílu abecedy.
Řešení:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bitů - informační objem zprávy byl převeden na bity.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 bitů - připadá na jeden znak abecedy.
3) 2*16*2048 = 65536 znaků - síla použité abecedy.
Úkol 5:
Laserová tiskárna Canon LBP tiskne průměrnou rychlostí 6,3 Kbps. Jak dlouho bude trvat tisk 8stránkového dokumentu, pokud je známo, že na jedné stránce je průměrně 45 řádků, 70 znaků na řádek (1 znak - 1 bajt)?
Řešení:
1) Najděte množství informací obsažených na 1 stránce: 45 * 70 * 8 bitů = 25200 bitů
2) Najděte množství informací na 8 stránkách: 25200 * 8 = 201600 bitů
3) Dovedeme k jednotným měrným jednotkám. Za tímto účelem převedeme Mbps na bity: 6,3 * 1024 = 6451,2 bps.
4) Najděte čas tisku: 201600: 6451,2 = 31 sekund.
Bibliografie
1. Ageev V.M. Teorie informace a kódování: diskretizace a kódování měřené informace. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Základy teorie informace a kódování. - Kyjev, škola Vishcha, 1986.
3. Nejjednodušší metody šifrování textu / D.M. Zlatopolský. - M.: Chistye Prudy, 2007 - 32 s.
4. Ugrinovič N.D. Informatika a informační technologie. Učebnice pro ročníky 10-11 / N.D. Ugrinovich. – M.: BINOM. Vědomostní laboratoř, 2003. - 512 s.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n