Kolik informací kóduje dva možné stavy. Co je kódování a dekódování? Příklady. Metody kódování a dekódování informací číselných, textových a grafických
V informatice se velké množství informačních procesů odehrává pomocí kódování dat. Proto je pochopení tohoto procesu velmi důležité pro pochopení základů této vědy. Pod kódováním informací se rozumí proces převodu znaků napsaných v různých přirozených jazycích (ruština, anglický jazyk atd.) do číselného označení.

To znamená, že při kódování textu je každému znaku přiřazena specifická hodnota ve formě nul a jedniček - .
Proč kódovat informace?
Nejprve je třeba odpovědět na otázku proč kódovat informace? Faktem je, že počítač je schopen zpracovat a uložit pouze jeden typ reprezentace dat - digitální. Veškeré informace v něm obsažené proto musí být přeloženy do digitální pohled.
Standardy kódování textu
Aby všechny počítače jednoznačně porozuměly konkrétnímu textu, je nutné použít obecně uznávané standardy kódování textu. V ostatních případech bude vyžadováno další překódování nebo nekompatibilita dat.
ASCII
Vůbec prvním standardem kódování počítačových znaků byl ASCII (celý název - American Standard Code for Information Interchange). Ke kódování jakéhokoli znaku v něm bylo použito pouze 7 bitů. Jak si pamatujete, pomocí 7 bitů lze zakódovat pouze 27 znaků nebo 128 znaků. To stačí ke kódování velkých a malých písmen latinské abecedy, arabských číslic, interpunkčních znamének a také určité sady speciálních znaků, například znak dolaru - "$". Aby však bylo možné zakódovat symboly abeced jiných národů (včetně symbolů ruské abecedy), musel být kód doplněn na 8 bitů (28=256 symbolů). Zároveň bylo pro každý jazyk použito samostatné kódování.
UNICODE
Bylo potřeba zachránit situaci z hlediska kompatibility kódovací tabulky. Proto byly postupem času vyvinuty nové aktualizované standardy. V současnosti je nejpopulárnější kódování tzv UNICODE. V něm je každý znak zakódován pomocí 2 bajtů, což odpovídá 216=62536 různým kódům.
Standardy kódování grafiky
Kódování obrázku vyžaduje mnohem více bajtů než kódování znaků. Většina vytvořených a zpracovaných snímků uložených v paměti počítače se dělí do dvou hlavních skupin:
- rastrové grafické obrázky;
- vektorové grafické obrázky.
Rastrová grafika
V rastrové grafice je obrázek reprezentován sadou barevných bodů. Takové body se nazývají pixely. Při zvětšení obrázku se takové body změní na čtverce.
Pro zakódování černobílého obrázku je každý pixel zakódován jedním bitem. Například černá je 0 a bílá je 1)
Náš minulý obrázek lze zakódovat takto:
Při kódování nebarevných obrázků se nejčastěji používá paleta 256 odstínů šedi, od bílé po černou. Pro zakódování takové gradace tedy stačí jeden bajt (28=256).
V kódování barevných obrázků se používá několik barevných schémat.
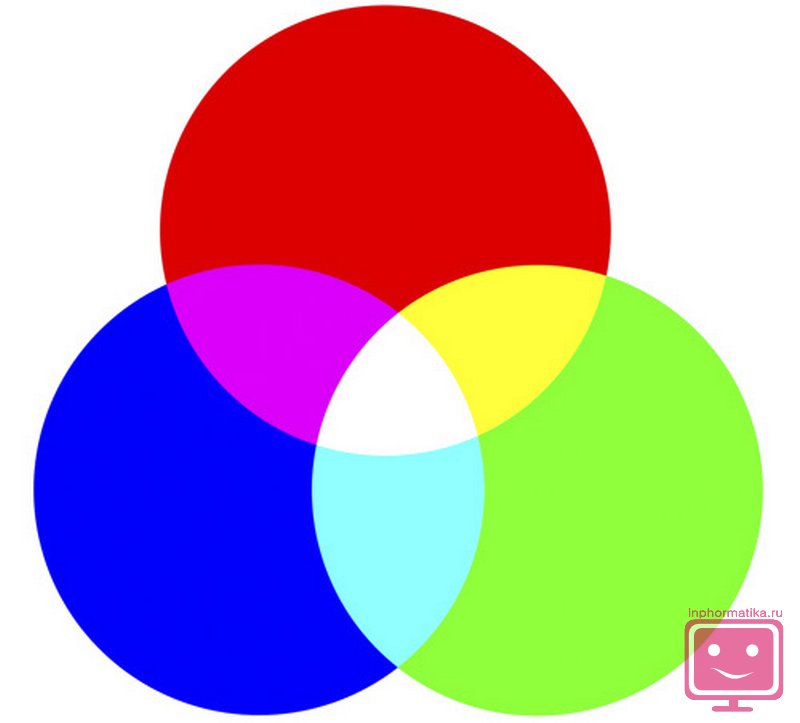
V praxi častěji RGB barevný model, kde jsou použity tři základní barvy: červená, zelená a modrá. Zbývající barevné odstíny se získají smícháním těchto základních barev.
Tedy ke kódování modelu z tři barvy ve 256 tónech je získáno přes 16,5 milionu různých barevných odstínů. To znamená, že pro kódování se používá 3⋅8=24 bitů, což odpovídá 3 bytům.
Přirozeně můžete použít minimální množství bit pro kódování barevných obrázků, ale pak se může vytvořit menší počet barevných tónů, v souvislosti s nimiž se kvalita obrazu výrazně sníží.
Chcete-li určit velikost obrázku, musíte vynásobit počet pixelů na šířku délkou počtu pixelů a znovu vynásobit velikostí samotného pixelu v bajtech.
- A- počet pixelů na šířku;
- b- počet pixelů na délku;
- já– velikost jednoho pixelu v bajtech.
Například barevný obrázek 800⋅600 pixelů je 60 000 bajtů.
Vektorová grafika
Objekty vektorové grafiky jsou kódovány zcela jiným způsobem. Zde se obraz skládá z čar, které mohou mít své vlastní koeficienty zakřivení.

Standardy kódování zvuku
Zvuky, které člověk slyší, jsou vibrace vzduchu. Zvukové vibrace jsou procesem šíření vln.
Zvuk má dvě hlavní vlastnosti:
- amplituda oscilace - určuje hlasitost zvuku;
- kmitání frekvence - určuje tón zvuku.
Zvuk lze pomocí mikrofonu převést na elektrický signál. Zvuk je zakódován s určitým, předem stanoveným časovým intervalem. V tomto případě se měří velikost elektrického signálu a je přiřazena binární hodnota. Čím častěji jsou tato měření prováděna, tím vyšší je kvalita zvuku.

700 MB CD pojme asi 80 minut zvuku v CD kvalitě.
Standardy kódování videa
Jak víte, videosekvence se skládá z rychle se měnících fragmentů. Snímky se mění rychlostí v rozsahu 24-60 snímků za sekundu.
Velikost stopáže v bajtech je určena velikostí snímku (počet pixelů na obrazovku na výšku a šířku), počtem použitých barev a počtem snímků za sekundu. Ale spolu s tím může být také zvuková stopa.
Seznámili jsme se s číselnými soustavami – způsoby kódování čísel. Čísla poskytují informaci o počtu položek. Tyto informace musí být zakódovány, uvedeny v nějakém číselném systému. Kterou ze známých metod zvolit, závisí na řešeném problému.
Donedávna počítače zpracovávaly především číselné a textové informace. Ale většinu informací o vnějším světě člověk dostává ve formě obrazů a zvuků. V tomto případě je důležitější obrázek. Pamatujte na přísloví: "Je lepší jednou vidět, než stokrát slyšet." Počítače proto dnes začínají stále aktivněji pracovat s obrazem a zvukem. Způsoby, jak takové informace zakódovat, budeme nutně zvažovat.
Binární kódování numerické a textové informace.
Jakákoli informace je v počítači zakódována pomocí sekvencí dvou číslic - 0 a 1. Počítač ukládá a zpracovává informace ve formě kombinace elektrických signálů: napětí 0,4V-0,6V odpovídá logické nule a napětí 2,4V-2,7V odpovídá logické jednotce. Volají se sekvence 0 a 1 binární kódy
a čísla 0 a 1 - bitů
(binární číslice). Toto kódování informací v počítači se nazývá binární kódování
. Binární kódování je tedy kódování s co nejmenším počtem elementárních znaků, kódování nejjednoduššími prostředky. To je z teoretického hlediska pozoruhodné.
Inženýry přitahuje binární kódování informací tím, že je snadné jej technicky implementovat. Elektronické obvody pro zpracování binárních kódů musí být pouze v jednom ze dvou stavů: je signál / není signál
nebo vysoké napětí/nízké napětí
.
Počítače ve své práci pracují s reálnými a celými čísly, reprezentovanými jako dva, čtyři, osm a dokonce deset bajtů. Dodatečný symbol se používá k reprezentaci znaménka čísla při počítání. podepsat bit
, který se obvykle umísťuje před číselné číslice. Pro kladná čísla je hodnota bitu znaménka 0 a pro záporná čísla je 1. Chcete-li zapsat interní reprezentaci záporného celého čísla (-N), musíte:
1) získejte další kód čísla N nahrazením 0 1 a 1 0;
2) k výslednému číslu přidejte 1.
Protože jeden bajt k reprezentaci tohoto čísla nestačí, je reprezentováno jako 2 bajty nebo 16 bitů, jeho doplňkový kód je 1111101111000101, tedy -1082=1111101111000110.
Pokud by PC zvládalo pouze jednotlivé bajty, bylo by to k ničemu. Ve skutečnosti PC pracuje s čísly, která jsou zapsána ve dvou, čtyřech, osmi a dokonce deseti bytech.
Od konce 60. let se ke zpracování textových informací stále více používají počítače. K reprezentaci textových informací se obvykle používá 256 různých znaků, například velká a malá písmena latinské abecedy, čísla, interpunkční znaménka atd. Ve většině moderních počítačů každý znak odpovídá sekvenci osmi nul a jedniček, tzv byte
.
Bajt je osmibitová kombinace nul a jedniček.
Při kódování informací v těchto elektronických počítačích se používá 256 různých sekvencí 8 nul a jedniček, což umožňuje zakódovat 256 znaků. Například velké ruské písmeno „M“ má kód 11101101, písmeno „I“ má kód 11101001, písmeno „R“ má kód 11110010. Slovo „MIR“ je tedy zakódováno sekvencí 24 bitů nebo 3 bajty: 111011011110100111110010.
Počet bitů ve zprávě se nazývá informační velikost zprávy.
To je zajímavé!
Zpočátku se v počítačích používala pouze latinka. Má 26 písmen. K označení každého by tedy stačilo pět pulzů (bitů). Ale text obsahuje interpunkční znaménka, desetinné číslice atd. Proto v prvních anglických počítačích obsahoval bajt – strojová slabika – šest bitů. Pak sedm - nejen pro rozlišení velkých písmen od malých, ale také pro zvýšení počtu ovládacích kódů pro tiskárny, signální světla a další zařízení. V roce 1964 se objevil výkonný IBM-360, ve kterém se bajt nakonec rovnal osmi bitům. Poslední osmý bit byl vyžadován pro pseudografické znaky.
Přiřazení konkrétního binárního kódu k symbolu je věcí dohody, která je pevně stanovena v tabulce kódů. Bohužel existuje pět různých kódování ruských písmen, takže texty vytvořené v jednom kódování se nebudou správně projevovat v jiném.
Chronologicky byl jedním z prvních standardů pro kódování ruských písmen na počítačích KOI8 („Kód výměny informací, 8 bitů“). Nejběžnějším kódováním je standardní kódování cyrilice Microsoft Windows, zkráceně СР1251 ("СР" znamená "Code Page" nebo "code page"). Apple vyvinul vlastní kódování ruských písmen (Mac) pro počítače Macintosh. Mezinárodní organizace pro normalizaci (ISO) schválila kódování ISO 8859-5 jako standard pro ruský jazyk. Konečně se objevil nový mezinárodní standard Unicode, který každému znaku přiřazuje nikoli jeden bajt, ale dva, a proto s ním lze zakódovat nikoli 256 znaků, ale až 65536.
Všechna tato kódování jsou pokračováním tabulky kódů ASCII (American Standard Code for Information Interchange), která kóduje 128 znaků.
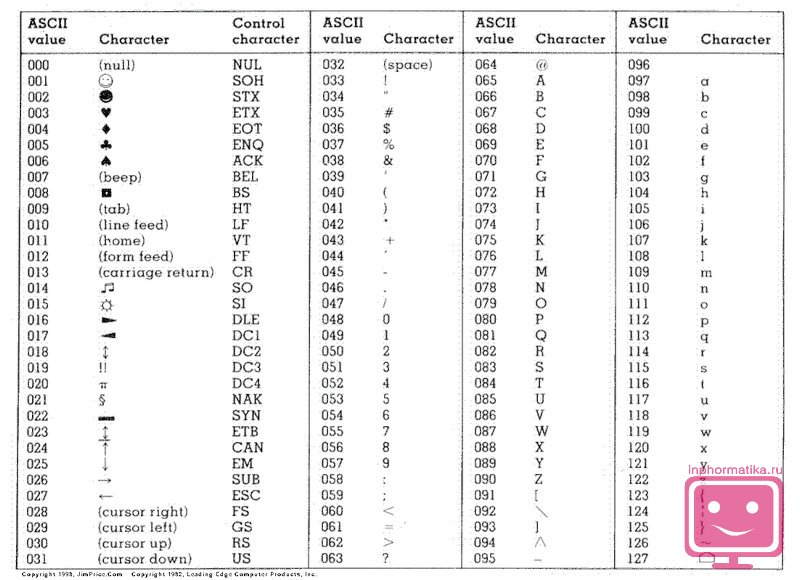
Tabulka znaků ASCII:
| kód | symbol | kód | symbol | kód | symbol | kód | symbol | kód | symbol | kód | symbol |
| 32 | Prostor | 48 | . | 64 | @ | 80 | P | 96 | " | 112 | p |
| 33 | ! | 49 | 0 | 65 | A | 81 | Q | 97 | A | 113 | q |
| 34 | " | 50 | 1 | 66 | B | 82 | R | 98 | b | 114 | r |
| 35 | # | 51 | 2 | 67 | C | 83 | S | 99 | C | 115 | s |
| 36 | $ | 52 | 3 | 68 | D | 84 | T | 100 | d | 116 | t |
| 37 | % | 53 | 4 | 69 | E | 85 | U | 101 | E | 117 | u |
| 38 | & | 54 | 5 | 70 | F | 86 | PROTI | 102 | F | 118 | proti |
| 39 | " | 55 | 6 | 71 | G | 87 | W | 103 | G | 119 | w |
| 40 | ( | 56 | 7 | 72 | H | 88 | X | 104 | h | 120 | X |
| 41 | ) | 57 | 8 | 73 | já | 89 | Y | 105 | i | 121 | y |
| 42 | * | 58 | 9 | 74 | J | 90 | Z | 106 | j | 122 | z |
| 43 | + | 59 | : | 75 | K | 91 | [ | 107 | k | 123 | { |
| 44 | , | 60 | ; | 76 | L | 92 | \ | 108 | l | 124 | | |
| 45 | - | 61 | < | 77 | M | 93 | ] | 109 | m | 125 | } |
| 46 | . | 62 | > | 78 | N | 94 | ^ | 110 | n | 126 | ~ |
| 47 | / | 63 | ? | 79 | Ó | 95 | _ | 111 | Ó | 127 | DEL |
Binární kódování textu probíhá následovně: při stisku klávesy se do počítače přenese určitá sekvence elektrických impulsů a každý znak má svou vlastní sekvenci elektrických impulsů (nuly a jedničky ve strojovém jazyce). Program ovladače klávesnice a obrazovky určí symbol z tabulky kódů a vytvoří jeho obraz na obrazovce. Texty a čísla jsou tedy uloženy v paměti počítače v binárním kódu a jsou programově převedeny na obrázky na obrazovce.
Binární kódování grafické informace.Od 80. let se technologie zpracování grafických informací na počítači rychle rozvíjí. Počítačová grafika je široce používána v počítačové simulaci ve vědeckém výzkumu, počítačových simulátorech, počítačové animaci, obchodní grafice, hrách atd.
Grafické informace na displeji jsou prezentovány ve formě obrázku, který je tvořen tečkami (pixely). Podívejte se pozorně na novinovou fotografii a uvidíte, že se také skládá z drobné tečky. Pokud se jedná pouze o černé a bílé body, pak každý z nich může být zakódován 1 bitem. Ale pokud jsou na fotografii odstíny, pak dva bity umožňují zakódovat 4 odstíny bodů: 00 - bílá barva, 01 - světle šedá, 10 - tmavě šedá, 11 - černá. Tři bity umožňují kódovat 8 odstínů atd.
Počet bitů potřebných k zakódování jednoho barevného odstínu se nazývá barevná hloubka.
V moderních počítačích rozlišení
(počet bodů na obrazovce), stejně jako počet barev závisí na grafickém adaptéru a lze je změnit programově.
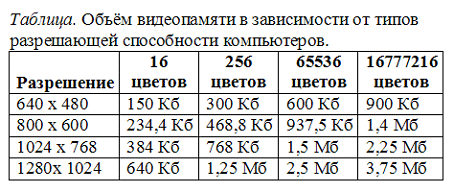
Barevné obrázky mohou mít různé režimy: 16 barev, 256 barev, 65536 barev ( vysoká barva), 16777216 barev ( pravdivá barva). Jeden bod za režim vysoká barva Je potřeba 16 bitů nebo 2 bajty.
Nejběžnější rozlišení obrazovky je 800 na 600 pixelů, tzn. 480 000 bodů. Vypočítejme množství video paměti potřebné pro režim vysoké barvy: 2 bajty *480000=960000 bajtů.
Větší jednotky se také používají k měření množství informací:
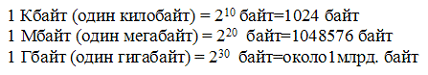
Proto se 960 000 bajtů přibližně rovná 937,5 KB. Pokud člověk mluví osm hodin denně bez přestávky, tak si za 70 let života řekne o 10 gigabajtech informací (to je 5 milionů stránek - stoh papíru vysoký 500 metrů).
Rychlost přenosu informací je počet bitů přenesených za 1 sekundu. Přenosová rychlost 1 bit za sekundu se nazývá 1 baud.
Ve videopaměti počítače je uložena bitmapa, což je binární kód obrázku, odkud je čtena procesorem (nejméně 50krát za sekundu) a zobrazena na obrazovce.
Binární kódování zvukové informace.
Od počátku 90. let byly osobní počítače schopny pracovat se zvukovými informacemi. Každý počítač se zvukovou kartou může ukládat jako soubory ( soubor je určité množství informací uložených na disku a má jméno
) a přehrát zvukové informace. Pomocí speciálních softwarových nástrojů (editorů zvukových souborů) se otevírají velké možnosti pro tvorbu, úpravu a poslech zvukových souborů. Jsou vytvořeny programy pro rozpoznávání řeči a je možné ovládat počítač hlasem.
Je to zvuková karta (karta), která převádí analogový signál na diskrétní zvukový záznam a naopak „digitalizovaný“ zvuk na analogový (kontinuální) signál, který je přiváděn do vstupu reproduktoru.

Při binárním kódování analogového audio signálu je vzorkován spojitý signál, tj. je nahrazena řadou jeho jednotlivých vzorků - odečtů. Kvalitní binární kódování závisí na dvou parametrech: počtu diskrétních úrovní signálu a počtu vzorků za sekundu. Počet vzorků nebo vzorkovací frekvence ve zvukových adaptérech se liší: 11 kHz, 22 kHz, 44,1 kHz atd. Pokud je počet úrovní 65536, pak se pro jeden zvukový signál počítá 16 bitů (216). 16bitový zvukový adaptér kóduje a reprodukuje zvuk přesněji než 8bitový.
Počet bitů potřebných k zakódování jedné úrovně zvuku se nazývá hloubka zvuku.
Hlasitost mono zvukového souboru (v bajtech) je určena vzorcem:

U stereofonního zvuku se hlasitost zvukového souboru zdvojnásobí, u kvadrafonního zvuku se zčtyřnásobí.
S tím, jak se programy stávají složitějšími a zvyšují se jejich funkce, stejně jako vzhled multimediálních aplikací, roste funkční objem programů a dat. Jestliže v polovině 80. let byl obvyklý objem programů a dat desítky a jen někdy stovky kilobajtů, tak v polovině 90. let to začaly být desítky megabajtů. V souladu s tím se zvyšuje množství paměti RAM.
Provoz elektronických počítačů pro zpracování dat se stal důležitým krokem v procesu zlepšování systémů řízení a plánování. Tento způsob sběru a zpracování informací je však poněkud odlišný od obvyklého, proto vyžaduje transformaci do systému symbolů srozumitelných počítači.
Co je to kódování informací?
Kódování dat je povinným krokem v procesu shromažďování a zpracování informací.
Kódem se zpravidla rozumí kombinace znaků, která odpovídá přenášeným datům nebo některé jejich kvalitativní vlastnosti. A kódování je proces sestavování zašifrované kombinace ve formě seznamu zkratek nebo speciálních znaků, které plně vyjadřují původní význam zprávy. Šifrování se někdy také nazývá šifrování, ale stojí za to vědět, že druhý postup zahrnuje ochranu dat před hackováním a čtením třetími stranami.
Účelem kódování je prezentovat informace ve vhodném a stručném formátu pro usnadnění jejich přenosu a zpracování na výpočetních zařízeních. Počítače pracují pouze s určitými formami informací, takže je důležité mít na paměti, abyste předešli problémům. Pojem zpracování dat zahrnuje vyhledávání, třídění a řazení a ke kódování v něm dochází ve fázi zadávání informací ve formě kódu.
Co je dekódování informací?
Otázka, co je to kódování a dekódování, může vyvstat pro uživatele PC z různých důvodů, ale v každém případě je důležité předat správné informace, které uživateli umožní úspěšně se posunout vpřed v toku informačních technologií. Jak víte, po procesu zpracování dat je získán výstupní kód. Pokud je takový fragment dešifrován, vytvoří se původní informace. To znamená, že dekódování je obrácený proces šifrování. 
Pokud při kódování data získají podobu symbolických signálů, které plně odpovídají přenášenému objektu, pak při dekódování jsou přenášené informace nebo některé jejich charakteristiky z kódu odstraněny.
Může existovat několik příjemců kódovaných zpráv, ale je velmi důležité, aby se informace dostaly do jejich rukou a nebyly dříve zveřejněny třetími stranami. Proto stojí za to studovat procesy kódování a dekódování informací. Pomáhají vyměňovat důvěrné informace mezi skupinou partnerů.
Kódování a dekódování textových informací
Když stisknete klávesu na klávesnici, počítač obdrží signál ve formuláři binární číslo, jehož dekódování naleznete v kódové tabulce - vnitřní reprezentace znaků v PC. ASCII tabulka je považována za světový standard. 
Nestačí však vědět, co je kódování a dekódování, musíte také rozumět tomu, jak jsou data umístěna v počítači. Například pro uložení jednoho symbolu binárního kódu elektronický počítač přidělí 1 bajt, tedy 8 bitů. Tato buňka může nabývat pouze dvou hodnot: 0 a 1. Ukázalo se, že jeden bajt umožňuje zašifrovat 256 různých znaků, protože toto je počet kombinací, které lze vytvořit. Tyto kombinace jsou klíčové ASCII tabulky. Například písmeno S je zakódováno jako 01010011. Když jej stisknete na klávesnici, data se zakódují a dekódují a na obrazovce dostaneme očekávaný výsledek.
Polovina tabulky standardů ASCII obsahuje kódy pro číslice, řídicí znaky a latinská písmena. Druhá část je vyplněna národními znaky, pseudografickými znaky a symboly, které nesouvisejí s matematikou. Je jasné, že v různých zemích se tato část tabulky bude lišit. Číslice jsou také při zadávání převedeny na binární podle standardního souhrnu. 
Kódování čísel
Podobný způsob kódování obrazových bodů se používá také v polygrafickém průmyslu. Pouze zde je zvykem používat čtvrtou barvu - černou. Z tohoto důvodu je konverzní tiskový systém zkrácen jako CMYK. Tento systém používá k reprezentaci obrázků až třicet dva bitů.

Metody kódování a dekódování informací zahrnují použití různých technologií v závislosti na typu vstupních dat. Například metoda šifrování grafických obrázků pomocí šestnáctibitových binárních kódů se nazývá High Color. Tato technologie umožňuje přenést na obrazovku až dvě stě padesát šest odstínů. Snížením počtu zapojených bitů použitých k šifrování bodů grafický obrázek, automaticky snížíte množství místa potřebného pro dočasné uložení informací. Tento způsob kódování dat se nazývá index.
Kódování zvuku
Nyní, když jsme se podívali na to, co je kódování a dekódování, a na metody, které jsou základem tohoto procesu, stojí za to se pozastavit nad takovou otázkou, jako je kódování zvukových dat.
Zvukové informace mohou být reprezentovány jako elementární jednotky a pauzy mezi každým z jejich párů. Každý signál je převeden a uložen do paměti počítače. Zvuky jsou reprodukovány pomocí šifrovaných kombinací uložených v paměti počítače.
Pokud jde o lidskou řeč, je mnohem obtížnější ji zakódovat, protože má různé odstíny a počítač musí každou frázi porovnat se standardem, který si předtím zapsal do paměti. K rozpoznání dojde pouze tehdy, když je mluvené slovo nalezeno ve slovníku.
Kódování informací v binárním kódu
Existují různé metody pro implementaci takového postupu, jako je kódování numerických, textových a grafických informací. K dekódování dat obvykle dochází v reverzní technologii.
Při kódování čísel se bere v úvahu i účel, pro který bylo číslo do systému zadáno: pro aritmetické výpočty nebo jednoduše pro výstup. Všechna data zakódovaná v binárním systému jsou šifrována pomocí jedniček a nul. Tyto znaky se také nazývají bity. Tato metoda kódování je nejoblíbenější, protože je z hlediska technologie nejjednodušší na organizaci: přítomnost signálu je 1, nepřítomnost je 0. Binární šifrování má pouze jednu nevýhodu - to je délka kombinací znaků. Ale z technického hlediska je snazší ovládat spoustu jednoduchých, jednotných součástí než malý počet složitějších.
Výhody binárního kódování
- To je vhodné pro různé typy.
- Při přenosu dat nedochází k žádným chybám.
- Pro PC je mnohem snazší zpracovávat takto zakódovaná data.
- Vyžaduje dvoustavová zařízení.
Nevýhody binárního kódování
- Velká délka kódů, která poněkud zpomaluje jejich zpracování.
- Složitost vnímání binárních kombinací osobou bez speciálního vzdělání nebo výcviku.

Závěr
Po přečtení tohoto článku jste mohli zjistit, co je kódování a dekódování a k čemu se používá. Lze konstatovat, že použité techniky konverze dat jsou zcela závislé na typu informace. Může to být nejen text, ale i čísla, obrázky a zvuk.
Kódování různých informací umožňuje sjednotit formu jejich prezentace, to znamená udělat je stejného typu, což výrazně urychluje zpracování a automatizaci dat pro další použití.
V elektronických počítačích se nejčastěji používají principy standardního binárního kódování, které převádí původní podobu reprezentace informace do formátu pohodlnějšího pro ukládání a další zpracování. Při dekódování probíhají všechny procesy v obráceném pořadí.
Obsah
I. Historie kódování informací………………………………..3
II. Kódovací informace ……………………………………………… 4
III. Kódování textových informací………………………………….4
IV. Typy kódovacích tabulek………………………………………………....6
V. Výpočet množství textových informací………………………14
Seznam použité literatury………………………………………..16
já . Historie kódování informací
Lidstvo používá textové šifrování (kódování) od okamžiku, kdy se objevily první tajné informace. Zde je několik technik kódování textu, které byly vynalezeny v různých fázích vývoje lidského myšlení:
Kryptografie je kryptografie, systém měnícího se písma, aby byl text pro nezasvěcené osoby nesrozumitelný;
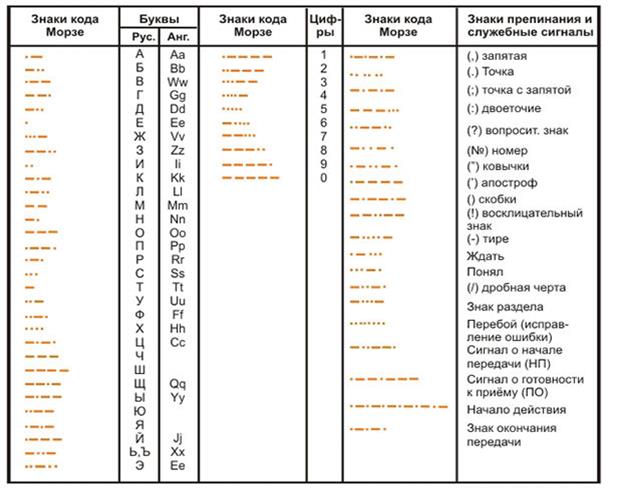
Morseova abeceda nebo nejednotný telegrafní kód, ve kterém je každé písmeno nebo znak reprezentován vlastní kombinací krátkých základních balíčků elektrický proud(tečky) a elementární parcely trojnásobného trvání (čárky);
Znakový jazyk je znakový jazyk používaný lidmi se sluchovým postižením.
Jedna z nejstarších známých šifrovacích metod nese jméno římského císaře Julia Caesara (1. století před naším letopočtem). Tato metoda je založena na nahrazení každého písmene zašifrovaného textu jiným tak, že se abeceda od původního písmene posune o pevný počet znaků a abeceda se čte v kruhu, tedy za písmenem i se uvažuje a. Takže slovo "byte" při posunutí o dva znaky doprava je zakódováno slovem "gvlf". Opačným procesem dešifrování daného slova je nahrazení každého zašifrovaného písmene druhým nalevo od něj.
II. Kódování informací
Kód je soubor konvencí (nebo signálů) pro záznam (nebo přenos) některých předem definovaných konceptů.
Kódování informací je proces vytváření určité reprezentace informace. V užším slova smyslu je pojem „kódování“ často chápán jako přechod od jedné formy prezentace informace k jiné, vhodnější pro ukládání, přenos nebo zpracování.
Obvykle je každý obrázek, když je zakódován (někdy se říká - zašifrovaný), reprezentován samostatným znakem.
Znak je prvkem konečného souboru odlišných prvků.
V užším slova smyslu je pojem „kódování“ často chápán jako přechod od jedné formy prezentace informace k jiné, vhodnější pro ukládání, přenos nebo zpracování.
Počítač umí zpracovávat textové informace. Při zadávání do počítače je každé písmeno zakódováno určitým číslem a při výstupu na externí zařízení (obrazovka nebo tisk) se pro lidské vnímání vytvářejí obrázky písmen pomocí těchto čísel. Korespondence mezi sadou písmen a čísel se nazývá kódování znaků.
Všechna čísla v počítači jsou zpravidla reprezentována nulami a jedničkami (a nikoli deseti číslicemi, jak je u lidí zvykem). Jinými slovy, počítače obvykle pracují v binárním systému, protože zařízení pro jejich zpracování jsou mnohem jednodušší. Zadávání čísel do počítače a jejich výstup pro čtení člověkem lze provádět v obvyklém desítkovém tvaru a všechny potřebné převody provádějí programy běžící na počítači.
III. Kódování textových informací
Stejné informace mohou být prezentovány (zakódovány) v několika formách. S příchodem počítačů bylo nutné zakódovat všechny typy informací, kterými se jednotlivec i lidstvo jako celek zabývá. Ale lidstvo začalo řešit problém kódování informací dávno před příchodem počítačů. Grandiózní výdobytky lidstva – psaní a aritmetika – nejsou ničím jiným než systémem kódování řeči a číselných informací. Informace se nikdy neobjeví čistá forma, je vždy nějak reprezentován, nějak zakódován.
Binární kódování je jedním z nejběžnějších způsobů reprezentace informací. V počítačích, robotech a obráběcích strojích s numerickým řízením jsou zpravidla všechny informace, se kterými zařízení pracuje, zakódovány ve formě slov binární abecedy.
Od konce 60. let 20. století se počítače stále častěji používají pro zpracování textu a nyní se většina světových osobních počítačů (a většina zčas) je zaneprázdněn zpracováním textových informací. Všechny tyto typy informací jsou v počítači reprezentovány binárním kódem, tj. používá se abeceda s mocninou dvě (pouze dva znaky 0 a 1). To je způsobeno skutečností, že je vhodné reprezentovat informace ve formě sekvence elektrických impulsů: neexistuje impuls (0), existuje impuls (1).
Takové kódování se obvykle nazývá binární a samotné logické sekvence nul a jedniček se nazývají strojový jazyk.
Z pohledu počítače se text skládá z jednotlivých znaků. Znaky zahrnují nejen písmena (velká nebo malá písmena, latinka nebo ruština), ale také číslice, interpunkční znaménka, speciální znaky jako "=", "(", "&" atd.) a dokonce (věnujte zvláštní pozornost!) mezery mezi slovy .
Texty se zadávají do paměti počítače pomocí klávesnice. Klávesy jsou psány nám známými písmeny, číslicemi, interpunkčními znaménky a dalšími symboly. Zadávají RAM v binárním kódu. To znamená, že každý znak je reprezentován 8bitovým binárním kódem.
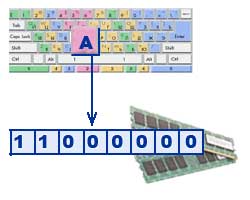 Tradičně se pro zakódování jednoho znaku používá množství informací rovné 1 bajtu, tj. I \u003d 1 byte \u003d 8 bitů. Pomocí vzorce, který dává do souvislosti počet možných událostí K a množství informací I, můžete vypočítat, kolik různých znaků lze zakódovat (za předpokladu, že znaky jsou možné události): K = 2 I = 2 8 = 256, tj. reprezentaci textových informací, můžete použít abecedu s kapacitou 256 znaků.
Tradičně se pro zakódování jednoho znaku používá množství informací rovné 1 bajtu, tj. I \u003d 1 byte \u003d 8 bitů. Pomocí vzorce, který dává do souvislosti počet možných událostí K a množství informací I, můžete vypočítat, kolik různých znaků lze zakódovat (za předpokladu, že znaky jsou možné události): K = 2 I = 2 8 = 256, tj. reprezentaci textových informací, můžete použít abecedu s kapacitou 256 znaků.
Tento počet znaků je dostatečný pro reprezentaci textových informací, včetně velkých a malých písmen ruské a latinské abecedy, čísel, znaků, grafických symbolů atd.
Kódování spočívá v tom, že každému znaku je přiřazen jedinečný desetinný kód od 0 do 255 nebo odpovídající binární kód od 00000000 do 11111111. Člověk tedy rozlišuje znaky podle jejich stylu a počítač podle jejich kódu.
Pohodlí bajtového kódování znaků je zřejmé, protože bajt je nejmenší adresovatelná část paměti, a proto může procesor při zpracování textu přistupovat ke každému znaku zvlášť. Na druhou stranu je 256 znaků dostačující pro reprezentaci široké škály informací o znacích.
V procesu zobrazení znaku na obrazovce počítače se provádí opačný proces - dekódování, tedy převod znakového kódu na jeho obraz. Je důležité, aby přiřazení konkrétního kódu k symbolu bylo věcí dohody, která je pevně stanovena v tabulce kódů.
Nyní vyvstává otázka, který osmibitový binární kód vložit do korespondence s každým znakem. Je jasné, že jde o podmíněnou záležitost, můžete přijít na mnoho způsobů kódování.
Všechny znaky počítačové abecedy jsou číslovány od 0 do 255. Každému číslu odpovídá osmibitový binární kód od 00000000 do 11111111. Tento kód je jednoduše pořadové číslo znaku v binární číselné soustavě.
IV . Typy kódovacích tabulek
Tabulka, ve které jsou všem znakům počítačové abecedy přiřazena pořadová čísla, se nazývá kódovací tabulka.
Pro odlišné typy Počítač používá různé kódovací tabulky.
Jako mezinárodní standard je přijata kódová tabulka ASCII (American Standard Code for Information Interchange), která kóduje první polovinu znaků číselnými kódy od 0 do 127 (kódy od 0 do 32 nejsou přiřazeny znakům, ale funkčním klávesám).
Tabulka ASCII kódů je rozdělena na dvě části.
Mezinárodním standardem je pouze první polovina tabulky, tzn. znaky s čísly od 0 (00000000) do 127 (01111111).
Struktura kódovací tabulky ASCII
| Sériové číslo | Kód | Symbol |
| 0 - 31 | 00000000 - 00011111 | Znaky s čísly od 0 do 31 se nazývají řídicí znaky. Jejich funkcí je řídit proces zobrazování textu na obrazovce nebo tisku, vydávání zvukového signálu, označování textu atd. |
| 32 - 127 | 0100000 - 01111111 | Standardní část tabulky (anglicky). To zahrnuje malá a velká písmena latinské abecedy, desetinné číslice, interpunkční znaménka, všechny druhy hranatých závorek, obchodní a další symboly. Znak 32 je mezera, tzn. prázdné místo v textu. Vše ostatní se odráží v určitých znameních. |
| 128 - 255 | 10000000 - 11111111 | Alternativní část tabulky (ruština). Druhá polovina tabulky kódů ASCII, nazývaná kódová stránka (128 kódů počínaje 10000000 a končící 11111111), může mít různé možnosti, každá možnost má své vlastní číslo. Kódová stránka se primárně používá k umístění jiných národních písem než latinky. V ruském národním kódování jsou v této části tabulky umístěny znaky ruské abecedy. |
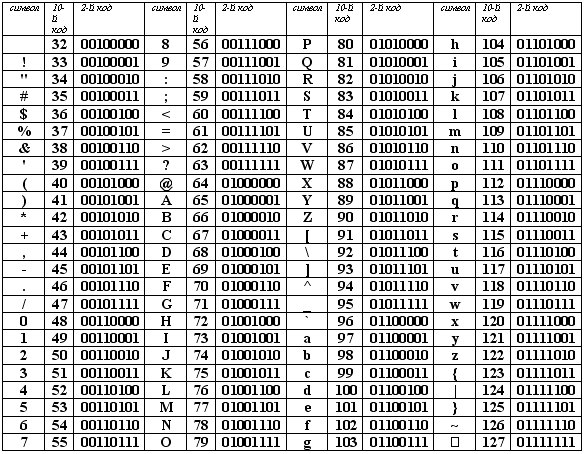
První polovina tabulky kódů ASCII
Je třeba věnovat pozornost skutečnosti, že v tabulce kódování jsou písmena (velká a malá písmena) uspořádána v abecedním pořadí a čísla jsou seřazeny vzestupně. Toto dodržování lexikografického řádu v uspořádání znaků se nazývá princip sekvenčního kódování abecedy.
U písmen ruské abecedy je také dodržován princip sekvenčního kódování.
Druhá polovina tabulky kódů ASCII
Bohužel v současné době existuje pět různých kódování azbuky (KOI8-R, Windows, MS-DOS, Macintosh a ISO). Z tohoto důvodu často vznikají problémy s přenosem ruského textu z jednoho počítače do druhého, z jednoho softwarového systému do druhého.
Chronologicky byl jedním z prvních standardů pro kódování ruských písmen na počítačích KOI8 ("Information Exchange Code, 8-bit"). Toto kódování se používalo již v 70. letech na počítačích řady počítačů EC a od poloviny 80. let se začalo používat v prvních rusifikovaných verzích operačního systému UNIX.
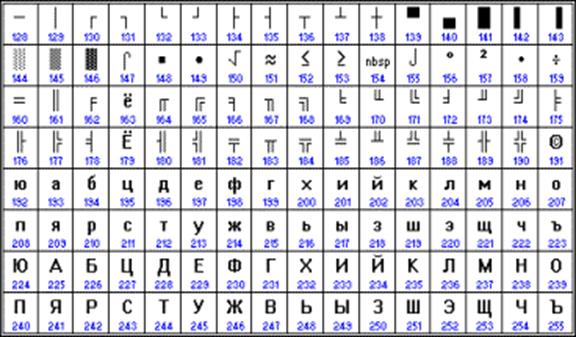
Od počátku 90. let, doby dominance operačního systému MS DOS, zůstává kódování CP866 ("CP" znamená "Code Page", "code page").
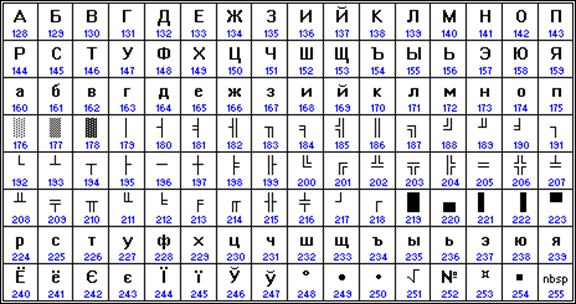
Počítače Apple s operačním systémem Mac OS používají vlastní kódování Mac.

Kromě toho Mezinárodní organizace pro normalizaci (International Standards Organization, ISO) schválila další kódování nazvané ISO 8859-5 jako standard pro ruský jazyk.
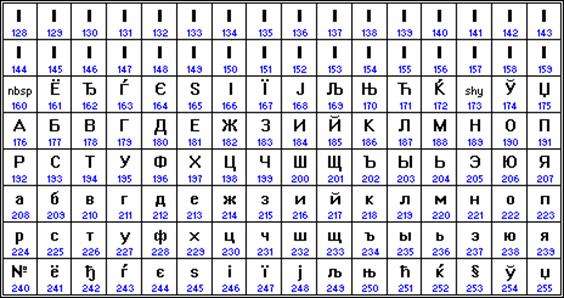
Nejběžnějším aktuálně používaným kódováním je Microsoft Windows, zkráceně CP1251. Představený společností Microsoft; s přihlédnutím rozšířený operační systémy(OS) a další softwarové produkty této společnosti v Ruská Federace se to rozšířilo.
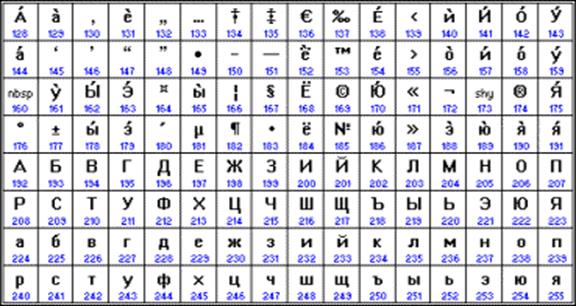
Od konce 90. let byl problém standardizace kódování znaků řešen zavedením nového mezinárodního standardu nazvaného Unicode.
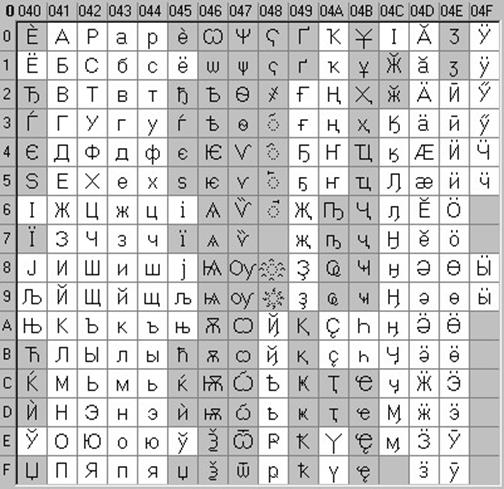
Jedná se o 16bitové kódování, tzn. má 2 bajty paměti na znak. V tomto případě se samozřejmě množství obsazené paměti zvýší dvakrát. Ale taková kódová tabulka umožňuje zahrnutí až 65536 znaků. Kompletní specifikace standardu Unicode zahrnuje všechny existující, zaniklé a uměle vytvořené abecedy světa a také mnoho matematických, hudebních, chemických a dalších symbolů.
Vnitřní reprezentace slov v paměti počítače
pomocí ASCII tabulky
Někdy se stává, že text, který se skládá z písmen ruské abecedy, přijatý z jiného počítače, nelze přečíst - na obrazovce monitoru je vidět nějaký druh "abracadabra". To je způsobeno skutečností, že počítače používají různá kódování znaků ruského jazyka.
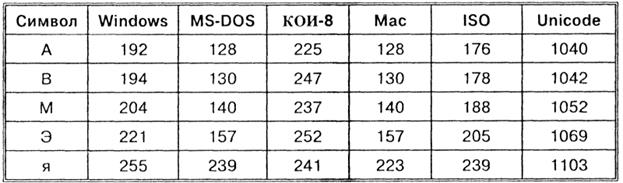
Každé kódování je tedy specifikováno vlastní kódovou tabulkou. Jak je vidět z tabulky, stejný binární kód v různá kódování jsou přiřazeny různé symboly.
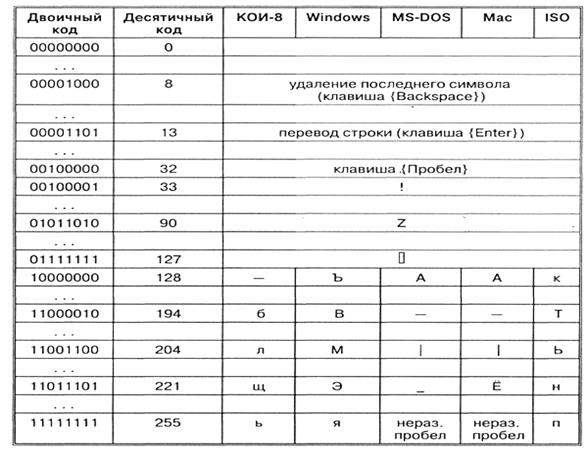 Například sekvence číselných kódů 221, 194, 204 v kódování CP1251 tvoří slovo „počítač“, zatímco v jiných kódováních se bude jednat o nicneříkající sadu znaků.
Například sekvence číselných kódů 221, 194, 204 v kódování CP1251 tvoří slovo „počítač“, zatímco v jiných kódováních se bude jednat o nicneříkající sadu znaků.
Naštěstí se ve většině případů uživatel nemusí starat o překódování textových dokumentů, protože to zajišťují speciální převodní programy zabudované v aplikacích.
PROTI . Výpočet množství textových informací
Úkol 1: Kódujte slovo „Řím“ pomocí kódovacích tabulek KOI8-R a CP1251.
Řešení:

Úkol 2: Za předpokladu, že každý znak je zakódován jedním bajtem, odhadněte objem informací následující věty:
"Můj strýc nejčestnějších pravidel,
Když jsem vážně onemocněl,
Přinutil se respektovat
A lepší mě nenapadl."
Řešení: Tato fráze má 108 znaků, včetně interpunkčních znamének, uvozovek a mezer. Toto číslo vynásobíme 8 bity. Dostaneme 108*8=864 bitů.
Úkol 3: Oba texty obsahují stejný počet znaků. První text je napsán v ruštině a druhý v jazyce kmene Naguri, jehož abeceda se skládá ze 16 znaků. Čí text obsahuje více informací?
Řešení:
1) I \u003d K * a (informační objem textu se rovná součinu počtu znaků a informační váhy jednoho znaku).
2) Protože oba texty mají stejný počet znaků (K), pak rozdíl závisí na informačním obsahu jednoho znaku abecedy (a).
3) 2 a1 = 32, tzn. a 1 = 5 bitů, 2 a2 = 16, tzn. a 2 = 4 bity.
4) I 1 = K * 5 bitů, I 2 = K * 4 bity.
5) Znamená to, že text psaný v ruštině nese 5/4krát více informací.
Úkol 4: Objem zprávy obsahující 2048 znaků byl 1/512 MB. Určete sílu abecedy.
Řešení:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bitů - informační objem zprávy byl převeden na bity.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 bitů - připadá na jeden znak abecedy.
3) 2*16*2048 = 65536 znaků - síla použité abecedy.
Úkol 5: Laserová tiskárna Canon LBP tiskne průměrnou rychlostí 6,3 Kbps. Jak dlouho bude trvat tisk 8stránkového dokumentu, pokud je známo, že na jedné stránce je průměrně 45 řádků, 70 znaků na řádek (1 znak - 1 bajt)?
Řešení:
1) Najděte množství informací obsažených na 1 stránce: 45 * 70 * 8 bitů = 25200 bitů
2) Najděte množství informací na 8 stránkách: 25200 * 8 = 201600 bitů
3) Dovedeme k jednotným měrným jednotkám. Za tímto účelem převedeme Mbps na bity: 6,3 * 1024 = 6451,2 bps.
4) Najděte čas tisku: 201600: 6451,2 = 31 sekund.
Bibliografie
1. Ageev V.M. Teorie informace a kódování: diskretizace a kódování měřené informace. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Základy teorie informace a kódování. - Kyjev, škola Vishcha, 1986.
3. Nejjednodušší metody šifrování textu / D.M. Zlatopolský. - M.: Chistye Prudy, 2007 - 32 s.
4. Ugrinovič N.D. Informatika a informační technologie. Učebnice pro ročníky 10-11 / N.D. Ugrinovich. – M.: BINOM. Vědomostní laboratoř, 2003. - 512 s.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n
INFORMACE O KÓDOVÁNÍ
INFORMACE O KÓDOVÁNÍ
Vytvoření korespondence mezi prvky zprávy a signály, s pomocí které je lze opravit.
Nechat V, ,
- mnoho prvků zprávy, a abeceda se symboly , Nechť se nazývá konečná posloupnost symbolů. slovo v této abecedě. Spousta slov v abecedě A volal kód, pokud je uveden v osobní korespondenci se sadou V. Každé slovo obsažené v kódu se nazývá. kódové slovo. Zavolá se počet znaků v kódovém slově. délka slova. Kódová slova mohou být stejná nebo různá. délka. V souladu s tímto kódem se nazývá. jednotné nebo nerovnoměrné.
Cíle K. a .: prezentace vstupních informací v, koordinace informačních zdrojů s přenosovým kanálem, detekce a oprava chyb při přenosu a zpracování dat, skrytí významu zprávy (kryptografie) atd. Informace vlastnosti objektu jsou zpravidla takové, že kód může být prezentován co nejekonomičtěji. Zdrojový kodér řeší tento problém odstraněním redundance ze zpráv. Další fáze přenosu dat - přenos přenosovým kanálem a (nebo) uložení do paměťových zařízení - vyžadují detekci a (nebo) opravu chyb, které se v nich vyskytují v důsledku rušení. Těchto cílů je dosaženo opravným kódováním, které provádí autor kanálu. Nakonec se pomocí aritmetiky provádějí informace ze zkreslení během zpracování v počítači. kódy.
Kódování hodnot. Přirozené číslo N reprezentováno v číselné soustavě s poziční váhou, pokud se vztah uskuteční

kde je digitální abeceda s Pčíslic, " - váhy číslic, - počty číslic. Termín "poziční" znamená, že v kódové reprezentaci (nebo jen kódu) čísla vyjádřeného podmíněnou rovností
kvantitativní ekvivalent spojený s obrázkem a l, závisí na jeho umístění v kódu. Výraz "významný" znamená, že každá číslice má pl. Nízká hmotnost objednávky p 0 v digitální měřicí technice se ztotožňuje s rozlišením analogově-digitální konverze. Výběr abecedy A a vážicí systémy R specifikuje klasifikaci pozičních číselných soustav (hodnotové kódování). V přírodních systémech
a pokud n- základ číselné soustavy - přirozené číslo, libovolné číslo X lze prezentovat jako
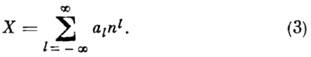
Výběr abecedy posunut: A= (0, 1, . . ., P-1), A=(-n- 1, . . ., 1, 0), nebo symetrické: A = (-p- 1, . . ., -1, 0, 1, . . ., P- 1) umožňuje reprezentovat kladná, záporná nebo libovolná čísla. Symetrický systém musí mít lichou základnu.
Počítač téměř výhradně používá poziční binární ofsetový systém (n = 2) s čísly (0, 1) a přirozeným poměrem vah představujících řadu čísel
Je možné například použít jinou sadu čísel. (-1, 1), což přináší některé specifické výhody.
Vyvíjejí se binární systémy, jejichž váhy číslic nejsou v přirozeném (2), ale ve složitějším poměru, tvořícím např. Fibonacciho řadu (neboli „zlatý řez“). Číslo N ve Fibonacciho kódu je reprezentován poměrem
kde jsou Fibonacciho čísla související vztahem
Číslo rozkladu (4). N nejednoznačně. Pro každého N existuje kód, ve kterém se nevyskytují dvě po sobě jdoucí nuly, a také kód, ve kterém jedničky neexistují. Tyto, stejně jako další strukturální rysy Fibonacciho kódů a „zlatých“ kódů, je činí vhodnými pro vytváření samoopravných převodníků, které ukládají a počítají. zařízení, digitálně řízené servopohony atd.
Ternární číselné soustavy naib. jsou ekonomické v tom smyslu, že právě v ternárním kódu je def. Počet znaků může vyjádřit největší rozmanitost čísel. Je důvod se domnívat, že v budoucnu, právě kvůli této vlastnosti, bude ternární symetrický kódovací systém s čísly (-1, 0, 1) počítat. technologie dominuje. Problémem zůstává vytvoření prvků, které implementují základní funkce v ternární logice: ternární invertor a ternární NAND nebo ternární NOR (viz. Logika),
Nepolohové kódy se používají ve specializovaných měřeních. a vypočítat. zařízení . Nejjednodušší z nepozičních - unitární kód lze získat vložením (2) n=1 a p 0=1. Má to číslo N se objeví jako N=n+l - postupně sčítané jednotky. Takto fungují například čítače pulsů.
Mezi systémy nepozičního kódování vyniká číselný systém ve zbytkových třídách (RNS). Číslo N v RNS je reprezentován jako uspořádaný soubor zbytků (zbytků) na koprimových bázích p1, . . ., rp;, kde je nejmenší zbytek N modulo R. Systém základů p 1, p 2, . . ., r p definuje rozsah reprezentace čísel P=p 1, p 2, . . ., r p V aritmetice SOK. operace se provádějí nezávisle pro každý základ, což umožňuje výrazně zvýšit jejich výkon. V RNS je vhodné řídit operace, protože chyby jsou lokalizovány v rámci základen. Specifické pro výpočet. zařízení pracující v SOC je použití tabulkové aritmetiky: hodnoty funkce, která se má vypočítat, se zadávají do tabulky předem a poté se načítají, když dorazí hodnoty operandů.
Efektivní kódování informačního zdroje má za cíl sladit informační vlastnosti informačního zdroje (IS) s přenosovým kanálem. Umělá inteligence má vydávat , skládající se z písmen m- písmenná abeceda
vzhled písmen je navíc statisticky nezávislý a podléhá distribuci
Zdroj je charakterizován entropií na symbol
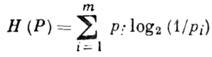
Entropie ![]() má význam nejistoty ohledně vzhledu další postavy na výstupu AI. Rovnost H(P)=0 je dosaženo s degenerovanou distribucí R, protože zpráva
má význam nejistoty ohledně vzhledu další postavy na výstupu AI. Rovnost H(P)=0 je dosaženo s degenerovanou distribucí R, protože zpráva
zatímco je deterministický; rovnost ![]() je dosaženo s ekvipravděpodobným výskytem - situace největší nejistoty. S m=2 a jednotným vzhledem písmen 1 A a 2 entropie je maximální a H(P) = 1. Tato hodnota - nejistota s ekvipravděpodobným výběrem ze dvou alternativ - se používá jako jednotka entropie -1.
je dosaženo s ekvipravděpodobným výskytem - situace největší nejistoty. S m=2 a jednotným vzhledem písmen 1 A a 2 entropie je maximální a H(P) = 1. Tato hodnota - nejistota s ekvipravděpodobným výběrem ze dvou alternativ - se používá jako jednotka entropie -1.
Každá metoda kódování je charakterizována srov. číslo L(P) písmena výstupní abecedy na jedno písmeno vstupní abecedy A t. Pro abecední kódování ![]() - délka slova v abecedě V r. Pokud je kódování jedna ku jedné, pak
- délka slova v abecedě V r. Pokud je kódování jedna ku jedné, pak
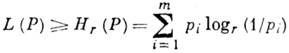
Hodnota Já (P) = L(P)-H r (P) volal redundance kódování v distribuci R. Problém je najít v dané třídě kódování jedna ku jedné kódování, které má min. velikost I(P). Existence minima a jeho hodnota jsou stanoveny Shannonovou větou pro kanál bez šumu, který říká, že pro zdroj s konečnou abecedou Na s entropií H(P) lze přiřadit kódová slova písmenům zdroje tak, že srov. délka kódového slova L (P) splní podmínky
Optimální kód je takový, že žádný jiný kód nebude poskytovat menší hodnotu L(P).
Konstruktivní postup hledání optimálního. kód pro kódování dané sady zpráv navrhl v roce 1952 D. R. Huffman. Myšlenka je, že písmena abecedy Na jsou seřazeny podle a kratší kódová slova jsou přiřazena pravděpodobnějším. Huffmanův kód má . vlastnosti: slovo odpovídající nejméně pravděpodobné zprávě má největší délku; dvě nejméně pravděpodobné zprávy jsou zakódovány slovy stejné délky, z nichž jedno končí nulou a druhé jednou (r=2).
Optimální jednotné kódování. Nechte zdroj být s dvoupísmennou abecedou a generujte slova délky l. S ohledem na celou sadu 2 l slov (zdrojový slovník) existuje tvrzení, že pro a dostatečně velké l zdrojový slovník je rozdělen na dvě podmnožiny: skupinu ekvipravděpodobných slov (pracovní zdrojový slovník) a skupinu slov s celkovou pravděpodobností blízkou nule ("atypické" sekvence). Tady H(R) - entropie na symbol zdroje. Podíl slov v pracovním slovníku je velmi malý a stále roste l inklinuje k nule. Myšlenka jednotného nebo blokového kódování spočívá v tom, že kodér, který přijímá zdrojová slova jako vstup, porovnává kódová slova pouze se slovy z pracovního slovníku a všechna ostatní zakóduje jedním slovem, které má význam chyby. Pravděpodobnost chyby lze libovolně snížit zvýšením délky zdrojového slova. V tomto případě objem kódovaných slov vyžaduje symboly kódového slova. Protože slova pracovního slovníku jsou téměř stejně pravděpodobná, kódová slova budou stejně pravděpodobná a entropie na symbol kódového slova se bude blížit 1 bitu. Kodér tedy vytváří slova délky , šetřící tím, že „načítá“ každý znak až do maximální možné informační zátěže 1 bit.
Zdrojové kódování získává nový význam díky nutnosti „komprimovat“ informační pole dat v databázích a databankách. Pole organizační, ekonomické, měřící. informace mají tak velkou redundanci, že umožňují až 80–85 %. Vyvinuté systémy pro správu databází (DBMS) mají speciální. programy (utility) pro analýzu, komprimaci a obnovu textu, pracující na principech uvedených výše.
Opravné kódování informací. Jeho účelem je detekovat a (nebo) opravovat chyby v kódových slovech, které se vyskytly během přenosu informací přes zašuměný kanál. Korekce zkreslení je možná zavedením redundance do přenosového systému. V tomto případě z celé sady slov kanálového kodéru N0 pouze N bude odpovídat přenášeným zprávám (povoleným slovům). Teoreticky v tomto případě podíl zjištěných chyb nepřekročí 1-N/N0.
Předpokládá se, že informační slovo U= (u 1, . . ., u n), kde u j=0, 1, je přiveden na vstup kanálového kodéru (dále jen kodér), který mu přiřadí kódové slovo X (x 1, . .., xl), ,
Kodér tedy přidává podle definice. pravidlo pro slovo U skupina k=l-n redundantní (opravné) bity. Kódové slovo X vstupuje do zašuměného kanálu, kde interference zkresluje některé symboly x i . Slovo přijaté na výstupu kanálu Y= (v 1, . . ., y 2) vstoupí do dekodéru, který obnoví (s aproximací výšky) slovo X. Kódová slova jsou provozována jako vektory v lineárním vektorovém prostoru s Hammingovou metrikou, která specifikuje vzdálenost mezi vektory.
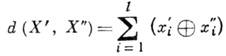
Shannonova věta pro šumové kanály, která říká, že pomocí vhodných kódů je možné přenášet informace tak, že pravděpodobnost chyby po dekódování je libovolně malá, za předpokladu, že přenosová rychlost nepřesáhne šířku pásma komunikačního kanálu, není konstruktivní: neoznačuje způsob, jak vytvořit kód. Při konstrukci kódu má rozhodující význam volba modelu výskytu chyb v přenášeném slově.
Naíb. rozšířený je model symetrického kanálu se stejně pravděpodobnými chybami rozkladu. typy - přechody, například znak 0 na 1 a 1 na 0.
Model kanálu "s výmazem" je specifický. Výstupní abeceda takového kanálu obsahuje speciální. symbol výmazu, do kterého se při výskytu chyby tohoto typu přenesou znaky vstupní abecedy.
Rozšířený rozdíl. předpoklady týkající se rozložení chyb v přenášené sekvenci symbolů (kódové slovo). Model nezávislých chyb (kanál bez paměti), model seskupených chyb (shluky chyb), chyby umístěné na konkrétním vzdálenost od sebe atd. Existují široce rozšířené domněnky o omezujícím počtu chyb v kódových slovech.
Za posledně uvedeného předpokladu se opravná schopnost kódu odhaduje podle počtu detekovaných chyb a (nebo) opravených s jeho pomocí v kódových slovech. Předpokládá se, že v kanálu s X součtový (mod 2) vektor šumu symbol-by-symbol Z, tvořící slovo. Násobnost výsledné chyby je stejná jako počet jednotek (Hammingova váha) v Z. Ve vektoru z l prvky ne více než r jednotky mohou být umístěny způsoby.
Jedná se o různé chyby, které se mohou vyskytnout během přenosu.
Hlavní charakteristikou kódu, která určuje jeho korekční schopnost ve vztahu k nezávislým chybám, je kódová vzdálenost. Kódová vzdálenost je nejmenší Hammingova vzdálenost mezi všemi možnými slovy = ( , . . . , ) a kódem. Aby kód detekoval všechny kombinace s chyby a opraveny všechny kombinace t chyby, je nutné a postačující, aby vzdálenost kódu byla rovna s+t+1.
Širokou třídou kódů pro symetrický kanál jsou lineární (skupinové) kódy, například Hammingovy kódy, které se široce používají k ochraně informací v hlavní paměti počítače. Hammingův kód má kódovou vzdálenost d=3, opravuje jednotlivé chyby a detekuje dvojité chyby. Má kontrolní číslice umístěné na pozicích očíslovaných 2°, 2, 2 2 , . . . Lineární kód je dán dvojicí matic: generování , , a check . Řádky generující matice jsou lineárně nezávislé vektory, které tvoří základ prostoru obsahujícího 2 n prvků - kódových slov. Každý z řádků kontrolní matice je ortogonální k řádkům , a
Kodér řádkového kódu generuje kódová slova podle pravidla X T = U T G. Model zkreslení předpokládá, že v kanálu s X součtový vektor šumu symbol po symbolu Z, tvořící slovo Y=X+Z.
Myšlenkou dekódování je vytvořit produkt S T \u003d Y T H T, nazývaný syndrom. Rovnost S= 0 to znamená Z=0, nebo je chyba nezjistitelná. Syndrom má 2 k -1 nenulových realizací, z nichž každá může být použita k označení chyby, ke které došlo.
Cyklický. kódy jsou zahrnuty jako podtřída ve skupinových kódech. V nich spolu se slovem X a všichni jeho cyklisté vstoupí. permutace. Kódová slova jsou tvořena jako součin dvou polynomů: U (E) stupeň P- 1, koeficient to-rogo tvoří informační slovo ty, a generativní g (E) stupeň l-p, neredukovatelné a beze zbytku dělící binomické (1+ E l). Dekódování spočívá v dělení přijatého slova (polynomu). g(E). Přítomnost nenulového zbytku indikuje přítomnost chyby. Cyklický. kódy jsou obvykle nesystematické.
Specialista. cyklický kódy jsou navrženy tak, aby detekovaly a opravovaly shluky chyb, například kódy požáru, definované generováním polynomů formuláře g(E) = =p(E)(Ec +1), Kde p(E) - neredukovatelný polynom a množství S je určena délkou opravených a zjištěných shluků chyb.
Hromady chyb jsou typické pro magnetická paměťová zařízení. nosiče, zejména pro magnetické pohony. disky (NMD) modern. počítač (viz paměť zařízení). K ochraně dat v NMD se proto hojně používá K. a. cyklický kódy implementované hardwarem.
Aritmetické kódy navrženy tak, aby detekovaly chyby, ke kterým došlo během provádění aritmetiky. operace s počítačem. V teorii aritmetiky. kódování, jsou zavedeny pojmy hmotnost, vzdálenost a chyba, které se liší od Hammingových. Aritmetický váha čísla je definována jako min. počet členů v reprezentaci čísla ve tvaru , ![]() . Chyby, v jejichž důsledku se velikost čísla změní o, r "= 0, 1, 2,..., se nazývají aritmetické. Aritmetická vzdálenost mezi N 1 A N 2 - aritmetický váha rozdílu se rovná násobku chyby, která převádí číslo N 1 PROTI N2, a určuje aritmetiku opravné schopnosti. kód je podobný Hammingově vzdálenosti.
. Chyby, v jejichž důsledku se velikost čísla změní o, r "= 0, 1, 2,..., se nazývají aritmetické. Aritmetická vzdálenost mezi N 1 A N 2 - aritmetický váha rozdílu se rovná násobku chyby, která převádí číslo N 1 PROTI N2, a určuje aritmetiku opravné schopnosti. kód je podobný Hammingově vzdálenosti.
Společné AN- kódování čísel N- operand - se provádí jeho vynásobením speciálně vybraným faktorem A. Kód 3A, který má kódovou vzdálenost 2, tedy detekuje jednotlivé chyby dělením součtu třemi. Chyby jsou detekovány s nenulovým zbytkem: aritmetickou hodnotou. chyby 2 i není dělitelná ani 3. Kromě jednoduchých chyb je při A=3 nalezena i část chyb dvojitých - těch, u kterých má správný a chybný výsledek po dělení 3 neshodné zbytky.
Kryptografie se provádí substitucí, kdy je každému písmenu zašifrované zprávy přiřazeno specifické. znak (např. další písmeno), buď permutací, kdy se písmena v umělých blocích textu zaměňují, nebo kombinací těchto metod. Shannon ukázal, že jsou možné kryptogramy, které nelze dešifrovat za přijatelné.
lit.: 1) Stakhov A.P., Úvod do algoritmické teorie měření, M., 1977; jeho vlastní, Kódy zlatého řezu, M., 1984; 2) Akušskij I., Juditskij D., Strojní aritmetika ve zbytkových třídách, Moskva, 1968; 3) Gal-lager R., Teorie informace a spolehlivé komunikace, přel. z angličtiny, M., 1974; 4) Dadaev Yu.G., Teorie aritmetických kódů, M., 1981; 5) Aršinov M. N., Sadovský L. E., Kódy a matematika, Moskva, 1983. L. N. Efimov.
Fyzická encyklopedie. V 5 svazcích. - M.: Sovětská encyklopedie. Šéfredaktor A. M. Prochorov. 1988 .
Podívejte se, co je „KÓDOVÁNÍ INFORMACÍ“ v jiných slovnících:
kódování informací- Proces transformace a (nebo) prezentace dat. [GOST 7.0 99] Témata činnosti informační knihovny EN kódování informací FR codage de l'information ... Technická příručka překladatele







