Koliko informacija kodira dva moguća stanja. Što je kodiranje i dekodiranje? Primjeri. Metode kodiranja i dekodiranja informacija numeričkih, tekstualnih i grafičkih
U informatici se veliki broj informacijskih procesa odvija pomoću kodiranje podataka. Stoga je razumijevanje ovog procesa vrlo važno za shvaćanje osnova ove znanosti. Pod kodiranjem informacija podrazumijeva se proces pretvaranja znakova napisanih na različitim prirodnim jezicima (ruski, Engleski jezik itd.) u brojčanu oznaku.

To znači da se prilikom kodiranja teksta svakom znaku dodjeljuje određena vrijednost u obliku nula i jedinica - .
Zašto kodirati informacije?
Prvo morate odgovoriti na pitanje zašto kodirati informacije? Činjenica je da je računalo sposobno obraditi i pohraniti samo jednu vrstu prikaza podataka - digitalnu. Stoga se sve informacije uključene u njega moraju prevesti na digitalni pogled.
Standardi kodiranja teksta
Kako bi sva računala nedvosmisleno razumjela određeni tekst, potrebno je koristiti općeprihvaćeno standardi kodiranja teksta. U drugim će slučajevima biti potrebno dodatno kodiranje ili nekompatibilnost podataka.
ASCII
Prvi računalni standard kodiranja znakova bio je ASCII (puni naziv - američki standardni kod za razmjenu informacija). Za kodiranje bilo kojeg znaka u njemu korišteno je samo 7 bitova. Kao što se sjećate, samo 27 znakova ili 128 znakova može se kodirati pomoću 7 bita. Ovo je dovoljno za kodiranje velikih i malih slova latinične abecede, arapskih brojeva, interpunkcijskih znakova, kao i određenog skupa posebnih znakova, na primjer, znak dolara - "$". Međutim, da bi se kodirali simboli alfabeta drugih naroda (uključujući i simbole ruske abecede), kod je morao biti dopunjen na 8 bita (28=256 simbola). Istodobno, za svaki jezik korišteno je zasebno kodiranje.
UNICODE
Trebalo je spasiti situaciju u smislu kompatibilnosti tablice kodiranja. Stoga su s vremenom razvijeni novi ažurirani standardi. Trenutno je najpopularnije kodiranje tzv UNICODE. U njemu je svaki znak kodiran pomoću 2 bajta, što odgovara 216=62536 različitih kodova.
Standardi grafičkog kodiranja
Za kodiranje slike potrebno je mnogo više bajtova nego za kodiranje znakova. Većina stvorenih i obrađenih slika pohranjenih u memoriji računala podijeljena je u dvije glavne skupine:
- rasterske grafičke slike;
- slike vektorske grafike.
Rasterska grafika
U rasterskoj grafici, slika je predstavljena skupom točaka u boji. Takve se točke nazivaju pikselima. Kada se slika poveća, takve se točke pretvaraju u kvadrate.
Za kodiranje crno-bijele slike, svaki piksel je kodiran jednim bitom. Na primjer, crno je 0, a bijelo je 1)
Naša prošla slika može se kodirati ovako:
Kod kodiranja slika bez boja najčešće se koristi paleta od 256 nijansi sive, u rasponu od bijele do crne. Stoga je jedan bajt (28=256) dovoljan za kodiranje takve gradacije.
U kodiranju slika u boji koristi se nekoliko shema boja.
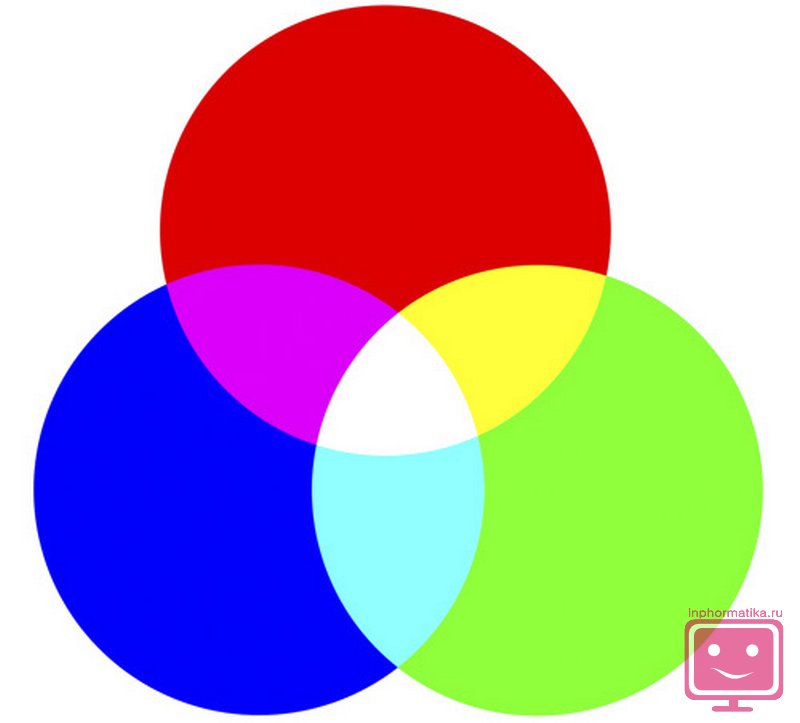
U praksi češće RGB model boja, gdje se redom koriste tri osnovne boje: crvena, zelena i plava. Preostale nijanse boja dobivaju se miješanjem ovih primarnih boja.
Dakle, za kodiranje modela iz tri boje u 256 tonova dobiva se preko 16,5 milijuna različitih nijansi boja. Odnosno, za kodiranje se koristi 3⋅8=24 bita, što odgovara 3 bajta.
Naravno, možete koristiti minimalni iznos bit za kodiranje slika u boji, ali tada se može formirati manji broj tonova boja, zbog čega će se kvaliteta slike značajno smanjiti.
Da biste odredili veličinu slike, trebate pomnožiti broj piksela u širinu s duljinom broja piksela i ponovno pomnožiti s veličinom samog piksela u bajtovima.
- A- broj piksela po širini;
- b- broj piksela po duljini;
- ja– veličina jednog piksela u bajtovima.
Na primjer, slika u boji od 800⋅600 piksela je 60 000 bajtova.
Vektorska grafika
Objekti vektorske grafike kodirani su na potpuno drugačiji način. Ovdje se slika sastoji od linija, koje mogu imati svoje koeficijente zakrivljenosti.

Standardi audio kodiranja
Zvukovi koje osoba čuje su vibracije zraka. Zvučne vibracije su proces širenja valova.
Zvuk ima dvije glavne karakteristike:
- amplituda oscilacija - određuje glasnoću zvuka;
- frekvencija osciliranja – određuje ton zvuka.
Zvuk se pomoću mikrofona može pretvoriti u električni signal. Zvuk je kodiran s određenim, unaprijed određenim vremenskim intervalom. U tom slučaju mjeri se veličina električnog signala i dodjeljuje se binarna vrijednost. Što se ova mjerenja češće provode, to je kvaliteta zvuka veća.

CD od 700 MB sadrži oko 80 minuta zvuka CD kvalitete.
Standardi video kodiranja
Kao što znate, video sekvenca sastoji se od fragmenata koji se brzo mijenjaju. Sličice se mijenjaju brzinom u rasponu od 24-60 sličica u sekundi.
Veličina snimke u bajtovima određena je veličinom okvira (brojem piksela po visini i širini ekrana), brojem upotrijebljenih boja i brojem okvira u sekundi. Ali uz ovo može postojati i audio zapis.
Upoznali smo se s brojevnim sustavima – načinima kodiranja brojeva. Brojevi daju informaciju o broju predmeta. Ove informacije moraju biti kodirane, predstavljene u nekom brojevnom sustavu. Koju od poznatih metoda odabrati ovisi o problemu koji se rješava.
Sve donedavno računala su uglavnom obrađivala numeričke i tekstualne informacije. Ali većinu informacija o vanjskom svijetu osoba prima u obliku slika i zvukova. U ovom slučaju slika je važnija. Zapamtite poslovicu: “Bolje jednom vidjeti nego sto puta čuti.” Stoga danas računala počinju sve aktivnije raditi sa slikom i zvukom. Mi ćemo nužno razmotriti načine kodiranja takvih informacija.
Binarno kodiranje numeričko i tekstualne informacije.
Bilo koja informacija kodirana je u računalu pomoću nizova od dvije znamenke - 0 i 1. Računalo pohranjuje i obrađuje informacije u obliku kombinacije električnih signala: napon od 0,4 V-0,6 V odgovara logičkoj nuli, a napon od 2,4V-2,7V odgovara logičkoj jedinici. Pozivaju se nizovi od 0 i 1 binarnih kodova
, a brojevi 0 i 1 - komadići
(binarne znamenke). Ovo kodiranje informacija na računalu naziva se binarno kodiranje
. Dakle, binarno kodiranje je kodiranje sa najmanjim mogućim brojem elementarnih znakova, kodiranje na najjednostavniji način. To je ono što ga čini izvanrednim s teorijske točke gledišta.
Inženjere binarno kodiranje informacija privlači činjenicom da ga je lako tehnički implementirati. Elektronički sklopovi za obradu binarnih kodova mora biti samo u jednom od dva stanja: ima signala / nema signala
ili visoki napon/niski napon
.
Računala u svom radu rade s realnim i cijelim brojevima, predstavljenim kao dva, četiri, osam pa čak i deset bajtova. Dodatni simbol se koristi za predstavljanje predznaka broja pri brojanju. znakovni bit
, koji se obično stavlja ispred brojčanih znamenki. Za pozitivne brojeve vrijednost bita predznaka je 0, a za negativne brojeve 1. Za pisanje interne reprezentacije negativnog cijelog broja (-N) morate:
1) dobiti dodatni kod broja N zamjenom 0 s 1 i 1 s 0;
2) dodajte 1 dobivenom broju.
Budući da jedan bajt nije dovoljan za predstavljanje ovog broja, on se predstavlja kao 2 bajta ili 16 bita, njegov komplementarni kod je 1111101111000101, dakle -1082=1111101111000110.
Kad bi računalo moglo rukovati samo jednim bajtom, bilo bi od male koristi. U stvarnosti, računalo radi s brojevima koji su napisani u dva, četiri, osam, pa čak i deset bajtova.
Od kasnih 60-ih, računala se sve više koriste za obradu tekstualnih informacija. Za predstavljanje tekstualnih informacija obično se koristi 256 različitih znakova, na primjer, velika i mala slova latinične abecede, brojke, interpunkcijski znakovi itd. U većini modernih računala svaki znak odgovara nizu od osam nula i jedinica, tzv bajt
.
Bajt je osmobitna kombinacija nula i jedinica.
Kod kodiranja informacija u ovim elektroničkim računalima koristi se 256 različitih nizova od 8 nula i jedinica, što omogućuje kodiranje 256 znakova. Na primjer, veliko rusko slovo "M" ima šifru 11101101, slovo "I" ima šifru 11101001, slovo "R" ima šifru 11110010. Dakle, riječ "MIR" je kodirana nizom od 24 bita ili 3 bajta: 111011011110100111110010.
Broj bitova u poruci naziva se informacijska veličina poruke.
Ovo je zanimljivo!
U početku se u računalima koristila samo latinica. Ima 26 slova. Dakle, pet impulsa (bitova) bilo bi dovoljno za označavanje svakog. Ali tekst sadrži interpunkcijske znakove, decimalne znamenke itd. Stoga je u prvim računalima na engleskom jeziku bajt - strojni slog - uključivao šest bitova. Zatim sedam - ne samo za razlikovanje velikih slova od malih, već i za povećanje broja kontrolnih kodova za pisače, signalna svjetla i drugu opremu. Godine 1964. pojavio se moćni IBM-360, u kojem je bajt konačno postao jednak osam bitova. Posljednji osmi bit bio je potreban za pseudografske znakove.
Dodjeljivanje određenog binarnog koda simbolu stvar je dogovora, koji je fiksiran u tablici kodova. Nažalost, postoji pet različitih kodiranja ruskih slova, tako da se tekstovi stvoreni u jednom kodiranju neće ispravno odražavati u drugom.
Kronološki, jedan od prvih standarda za kodiranje ruskih slova na računalima bio je KOI8 ("Information Exchange Code, 8 bit"). Najčešće kodiranje je standardno Microsoft Windows ćirilično kodiranje, skraćeno kao SR1251 ("SR" je kratica za "Code Page" ili "kodnu stranicu"). Apple je razvio vlastito kodiranje ruskih slova (Mac) za Macintosh računala. Međunarodna organizacija za standarde (ISO) odobrila je kodiranje ISO 8859-5 kao standard za ruski jezik. Konačno se pojavio novi međunarodni Unicode standard koji svakom znaku ne dodjeljuje jedan bajt, već dva, pa se njime može kodirati ne 256 znakova, već čak 65536.
Sva ova kodiranja nastavci su ASCII (American Standard Code for Information Interchange) tablice kodova, koja kodira 128 znakova.
Tablica ASCII znakova:
| kodirati | simbol | kodirati | simbol | kodirati | simbol | kodirati | simbol | kodirati | simbol | kodirati | simbol |
| 32 | Prostor | 48 | . | 64 | @ | 80 | P | 96 | " | 112 | str |
| 33 | ! | 49 | 0 | 65 | A | 81 | Q | 97 | a | 113 | q |
| 34 | " | 50 | 1 | 66 | B | 82 | R | 98 | b | 114 | r |
| 35 | # | 51 | 2 | 67 | C | 83 | S | 99 | c | 115 | s |
| 36 | $ | 52 | 3 | 68 | D | 84 | T | 100 | d | 116 | t |
| 37 | % | 53 | 4 | 69 | E | 85 | U | 101 | e | 117 | u |
| 38 | & | 54 | 5 | 70 | F | 86 | V | 102 | f | 118 | v |
| 39 | " | 55 | 6 | 71 | G | 87 | W | 103 | g | 119 | w |
| 40 | ( | 56 | 7 | 72 | H | 88 | x | 104 | h | 120 | x |
| 41 | ) | 57 | 8 | 73 | ja | 89 | Y | 105 | ja | 121 | g |
| 42 | * | 58 | 9 | 74 | J | 90 | Z | 106 | j | 122 | z |
| 43 | + | 59 | : | 75 | K | 91 | [ | 107 | k | 123 | { |
| 44 | , | 60 | ; | 76 | L | 92 | \ | 108 | l | 124 | | |
| 45 | - | 61 | < | 77 | M | 93 | ] | 109 | m | 125 | } |
| 46 | . | 62 | > | 78 | N | 94 | ^ | 110 | n | 126 | ~ |
| 47 | / | 63 | ? | 79 | O | 95 | _ | 111 | o | 127 | DEL |
Binarno kodiranje teksta događa se na sljedeći način: kada se pritisne tipka, određeni slijed električnih impulsa se prenosi na računalo, a svaki znak ima svoj vlastiti slijed električnih impulsa (nule i jedinice u strojnom jeziku). Program upravljačkog programa tipkovnice i zaslona određuje simbol iz kodne tablice i stvara njegovu sliku na ekranu. Tako se tekstovi i brojevi pohranjuju u memoriju računala u binarnom kodu i programski se pretvaraju u slike na ekranu.
Binarno kodiranje grafičke informacije.Od 80-ih godina prošlog stoljeća ubrzano se razvija tehnologija obrade grafičkih informacija na računalu. Računalna grafika se široko koristi u računalnim simulacijama u znanstvenim istraživanjima, računalnim simulatorima, računalnim animacijama, poslovnoj grafici, igrama itd.
Grafičke informacije na zaslonu prikazane su u obliku slike koja se sastoji od točaka (piksela). Pogledajte pažljivo novinsku fotografiju i vidjet ćete da se i ona sastoji od sitne točkice. Ako su to samo crne i bijele točke, onda se svaka od njih može kodirati s 1 bitom. Ali ako na fotografiji postoje nijanse, tada vam dva bita omogućuju kodiranje 4 nijanse točaka: 00 - bijela boja, 01 - svijetlo siva, 10 - tamno siva, 11 - crna. Tri bita vam omogućuju kodiranje 8 nijansi, itd.
Broj bitova potrebnih za kodiranje jedne nijanse boje naziva se dubina boje.
U modernim računalima rezolucija
(broj točaka na ekranu), kao i broj boja ovisi o video adapteru i može se programski mijenjati.
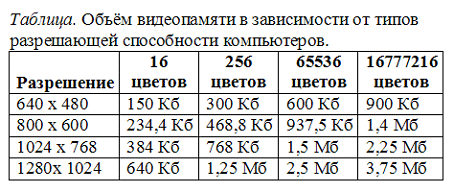
Slike u boji mogu imati različite načine: 16 boja, 256 boja, 65536 boja ( visoka boja), 16777216 boja ( prava boja). Jedan bod za način visoka boja Potrebno je 16 bita ili 2 bajta.
Najčešća rezolucija zaslona je 800 x 600 piksela, tj. 480000 bodova. Izračunajmo količinu video memorije potrebne za način visoke boje: 2 bajta *480000=960000 bajta.
Za mjerenje količine informacija koriste se i veće jedinice:
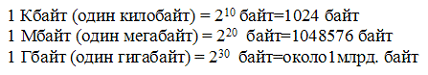
Stoga je 960000 bajtova približno jednako 937,5 KB. Ako čovjek govori osam sati dnevno bez pauze, tada će za 70 godina života izgovoriti oko 10 gigabajta informacija (to je 5 milijuna stranica – hrpa papira visoka 500 metara).
Brzina prijenosa informacija je broj bitova prenesenih u 1 sekundi. Brzina prijenosa od 1 bita u sekundi naziva se 1 baud.
Video memorija računala pohranjuje bitmapu, koja je binarni kod slike, odakle je čita procesor (najmanje 50 puta u sekundi) i prikazuje na ekranu.
Binarno kodiranje zvučnih informacija.
Od početka 90-ih osobna računala mogu raditi sa zvučnim informacijama. Svako računalo sa zvučnom karticom može spremati kao datoteke ( datoteka je određena količina informacija pohranjena na disku i ima naziv
) i reproducirajte audio informacije. Uz pomoć posebnih softverskih alata (uređivača audio datoteka) otvaraju se velike mogućnosti za stvaranje, uređivanje i slušanje zvučnih datoteka. Izrađuju se programi za prepoznavanje govora i postaje moguće upravljati računalom glasom.
Zvučna kartica (kartica) je ta koja pretvara analogni signal u diskretni fonogram i obrnuto, "digitalizirani" zvuk u analogni (kontinuirani) signal koji se dovodi na ulaz zvučnika.

U binarnom kodiranju analognog audio signala uzorkuje se kontinuirani signal, tj. zamjenjuje se nizom njegovih pojedinačnih uzoraka – čitanja. Kvaliteta binarno kodiranje ovisi o dva parametra: broju diskretnih razina signala i broju uzoraka u sekundi. Broj uzoraka ili brzina uzorkovanja u audio adapterima varira: 11 kHz, 22 kHz, 44,1 kHz itd. Ako je broj razina 65536, tada se za jedan audio signal izračunava 16 bitova (216). 16-bitni audio adapter kodira i reproducira zvuk točnije od 8-bitnog.
Broj bitova potrebnih za kodiranje jedne razine zvuka naziva se dubina zvuka.
Glasnoća mono audio datoteke (u bajtovima) određena je formulom:

Kod stereofonog zvuka, glasnoća audio datoteke se udvostručuje, kod kvadrafonog zvuka, učetverostručuje se.
Kako programi postaju sve složeniji i njihove funkcije se povećavaju, kao i pojava multimedijskih aplikacija, funkcionalni obujam programa i podataka raste. Ako je sredinom 80-ih uobičajeni volumen programa i podataka iznosio desetke, a tek ponekad stotine kilobajta, onda je sredinom 90-ih počeo iznositi desetke megabajta. Sukladno tome, povećava se količina RAM-a.
Rad elektroničkih računala za obradu podataka postao je važan korak u procesu poboljšanja sustava upravljanja i planiranja. Ali ova metoda prikupljanja i obrade informacija je nešto drugačija od uobičajene, stoga zahtijeva transformaciju u sustav simbola razumljiv računalu.
Što je kodiranje informacija?
Kodiranje podataka obavezan je korak u procesu prikupljanja i obrade informacija.
Šifra u pravilu označava kombinaciju znakova koja odgovara prenesenim podacima ili nekim njihovim kvalitativnim karakteristikama. A kodiranje je proces sastavljanja šifrirane kombinacije u obliku popisa kratica ili posebnih znakova koji u potpunosti prenose izvorno značenje poruke. Enkripcija se ponekad naziva i enkripcijom, ali vrijedi znati da potonji postupak uključuje zaštitu podataka od hakiranja i čitanja trećih strana.
Svrha kodiranja je prikazati informacije u prikladnom i sažetom obliku kako bi se olakšao njihov prijenos i obrada na računalnim uređajima. Računala rade samo s određenim oblicima informacija, pa je važno to imati na umu kako biste izbjegli probleme. Pojam obrade podataka uključuje pretraživanje, sortiranje i sređivanje, a kodiranje se u njemu događa u fazi unosa informacija u obliku koda.
Što je dekodiranje informacija?
Pitanje što je kodiranje i dekodiranje može se pojaviti kod korisnika osobnog računala iz različitih razloga, ali u svakom slučaju, važno je prenijeti točne informacije koje će korisniku omogućiti da uspješno napreduje u tijeku informacijske tehnologije. Kao što razumijete, nakon procesa obrade podataka dobiva se izlazni kod. Ako se takav fragment dešifrira, formira se izvorna informacija. Odnosno, dekodiranje je obrnuti proces od šifriranja. 
Ako tijekom kodiranja podaci dobiju oblik simboličkih signala koji u potpunosti odgovaraju prenesenom objektu, tada se tijekom dekodiranja prenesena informacija ili neka njezina karakteristika uklanja iz koda.
Može postojati nekoliko primatelja kodiranih poruka, ali vrlo je važno da informacije padnu u njihove ruke i da ih treće strane nisu prethodno otkrile. Stoga je vrijedno proučavati procese kodiranja i dekodiranja informacija. Oni pomažu u razmjeni povjerljivih informacija između skupine sugovornika.
Kodiranje i dekodiranje tekstualnih informacija
Kada pritisnete tipku na tipkovnici, računalo prima signal u obliku binarni broj, čije se dekodiranje može pronaći u tablici kodova - interni prikaz znakova u računalu. ASCII tablica se smatra svjetskim standardom. 
Međutim, nije dovoljno znati što su kodiranje i dekodiranje, potrebno je razumjeti i kako se podaci nalaze u računalu. Na primjer, za pohranjivanje jednog simbola binarnog koda, elektroničko računalo izdvaja 1 bajt, odnosno 8 bitova. Ova ćelija može imati samo dvije vrijednosti: 0 i 1. Ispada da vam jedan bajt omogućuje šifriranje 256 različitih znakova, jer je to broj kombinacija koje možete napraviti. Ove kombinacije su ključne ASCII tablice. Na primjer, slovo S je kodirano kao 01010011. Kada ga pritisnete na tipkovnici, podaci se kodiraju i dekodiraju, a na ekranu dobivamo očekivani rezultat.
Polovica tablice ASCII standarda sadrži kodove za znamenke, kontrolne znakove i latinična slova. Drugi dio ispunjen je nacionalnim znakovima, pseudografskim znakovima i simbolima koji nisu povezani s matematikom. Jasno je da će u različitim zemljama ovaj dio tablice biti drugačiji. Znamenke se također pretvaraju u binarno kada se unose, u skladu sa standardnim sažetkom. 
Kodiranje brojeva
Slična metoda kodiranja slikovnih točaka također se koristi u tiskarskoj industriji. Samo ovdje je uobičajeno koristiti četvrtu boju - crnu. Zbog toga se sustav pretvorbenog ispisa skraćeno naziva CMYK. Ovaj sustav koristi čak trideset i dva bita za predstavljanje slika.

Metode kodiranja i dekodiranja informacija uključuju korištenje različitih tehnologija, ovisno o vrsti ulaznih podataka. Na primjer, metoda šifriranja grafičkih slika šesnaestobitnim binarnim kodovima naziva se High Color. Ova tehnologija omogućuje prijenos čak dvjesto pedeset i šest nijansi na ekran. Smanjenjem broja uključenih bitova koji se koriste za šifriranje točaka grafička slika, automatski smanjujete količinu prostora potrebnog za privremenu pohranu informacija. Ova metoda kodiranja podataka naziva se indeks.
Audio kodiranje
Sada kada smo pogledali što su kodiranje i dekodiranje, i metode koje su u osnovi ovog procesa, vrijedi se zadržati na takvom pitanju kao što je kodiranje audio podataka.
Zvučne informacije mogu se prikazati kao elementarne jedinice i pauze između svakog od njihovih parova. Svaki signal se pretvara i pohranjuje u memoriju računala. Zvukovi se emitiraju pomoću šifriranih kombinacija pohranjenih u memoriji računala.
Što se tiče ljudskog govora, njega je mnogo teže kodirati, jer ima raznih nijansi, a računalo mora svaku frazu usporediti sa standardom koji je prethodno unesen u njegovu memoriju. Prepoznavanje će se dogoditi samo kada se izgovorena riječ pronađe u rječniku.
Kodiranje informacija u binarnom kodu
Postoje različite metode za provedbu takvog postupka kao što je kodiranje numeričkih, tekstualnih i grafičkih informacija. Dekodiranje podataka obično se odvija u obrnutoj tehnologiji.
Kod kodiranja brojeva uzima se u obzir čak i svrha za koju je broj unesen u sustav: za aritmetičke izračune ili jednostavno za izlaz. Svi podaci kodirani u binarnom sustavu šifrirani su jedinicama i nulama. Ovi znakovi se također nazivaju bitovi. Ova metoda kodiranja je najpopularnija, jer je najlakše organizirati u smislu tehnologije: prisutnost signala je 1, odsutnost je 0. Binarno šifriranje ima samo jedan nedostatak - to je duljina kombinacija znakova. Ali s tehničke točke gledišta, lakše je rukovati hrpom jednostavnih, uniformnih komponenti nego malim brojem složenijih.
Prednosti binarnog kodiranja
- Ovo je prikladno za razne vrste.
- Tijekom prijenosa podataka ne dolazi do pogrešaka.
- Računalu je mnogo lakše obraditi podatke kodirane na ovaj način.
- Zahtijeva uređaje s dvojnim stanjem.
Nedostaci binarnog kodiranja
- Velika duljina kodova, što donekle usporava njihovu obradu.
- Složenost percepcije binarnih kombinacija od strane osobe bez posebnog obrazovanja ili obuke.

Zaključak
Nakon što ste pročitali ovaj članak, mogli ste saznati što je kodiranje i dekodiranje i za što se koristi. Može se zaključiti da tehnike pretvorbe podataka koje se koriste u potpunosti ovise o vrsti informacije. To može biti ne samo tekst, već i brojevi, slike i zvuk.
Kodiranje različitih informacija omogućuje vam da unificirate oblik njihove prezentacije, odnosno da bude iste vrste, što značajno ubrzava obradu i automatizaciju podataka za daljnju upotrebu.
U elektroničkim računalima najčešće se koriste principi standardnog binarnog kodiranja, kojim se izvorni oblik prikaza informacija pretvara u format pogodniji za pohranu i daljnju obradu. Prilikom dekodiranja svi se procesi odvijaju obrnutim redoslijedom.
Sadržaj
I. Povijest kodiranja informacija………………………………..3
II. Informacije o kodiranju……………………………………………4
III. Kodiranje tekstualnih informacija…………………………….4
IV. Vrste tablica kodiranja………………………………………………...6
V. Izračun količine tekstualnih informacija………………………14
Popis korištene literature…………………………………..16
ja . Povijest kodiranja informacija
Čovječanstvo koristi enkripciju (kodiranje) teksta od samog trenutka kada su se pojavile prve tajne informacije. Evo nekoliko tehnika kodiranja teksta koje su izumljene u različitim fazama razvoja ljudske misli:
Kriptografija je kriptografija, sustav mijenjanja pisma kako bi se tekst učinio nerazumljivim neupućenim osobama;
Morseov kod ili neuniformirani telegrafski kod, u kojem je svako slovo ili znak predstavljen vlastitom kombinacijom kratkih elementarnih parcela električna struja(točke) i elementarne parcele trostrukog trajanja (crtice);
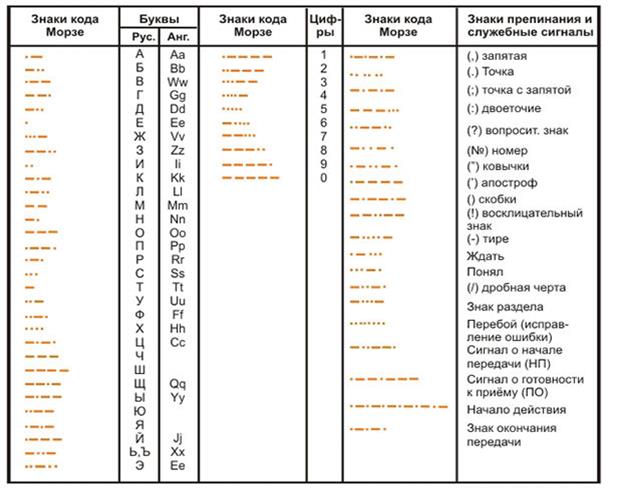
Znakovni jezik je znakovni jezik kojim se služe osobe s oštećenjem sluha.
Jedna od najranijih poznatih metoda šifriranja nosi ime rimskog cara Julija Cezara (1. st. pr. Kr.). Ova se metoda temelji na zamjeni svakog slova šifriranog teksta drugim pomicanjem abecede od izvornog slova za fiksni broj znakova, a abeceda se čita u krug, odnosno nakon slova i, u obzir se uzima a. Dakle, riječ "bajt" kada se pomakne za dva znaka udesno je kodirana riječju "gvlf". Obrnuti proces od dešifriranja dane riječi je zamjena svakog šifriranog slova s drugim lijevo od njega.
II. Kodiranje informacija
Kod je skup konvencija (ili signala) za snimanje (ili prijenos) nekih unaprijed definiranih koncepata.
Kodiranje informacija je proces formiranja određenog prikaza informacija. U užem smislu, pojam "kodiranje" često se shvaća kao prijelaz iz jednog oblika prezentacije informacija u drugi, pogodniji za pohranu, prijenos ili obradu.
Obično je svaka slika, kada je kodirana (ponekad kažu - šifrirana), predstavljena posebnim znakom.
Znak je element konačnog skupa različitih elemenata.
U užem smislu, pojam "kodiranje" često se shvaća kao prijelaz iz jednog oblika prezentacije informacija u drugi, pogodniji za pohranu, prijenos ili obradu.
Računalo može obrađivati tekstualne informacije. Kada se unese u računalo, svako slovo je kodirano određenim brojem, a kada se izađe na vanjske uređaje (zaslon ili ispis), za ljudsku percepciju, slike slova se grade pomoću tih brojeva. Korespondencija između skupa slova i brojeva naziva se kodiranje znakova.
U pravilu su svi brojevi u računalu predstavljeni pomoću nula i jedinica (a ne deset znamenki, kako je to uobičajeno za ljude). Drugim riječima, računala obično rade u binarnom sustavu, jer su uređaji za njihovu obradu mnogo jednostavniji. Unos brojeva u računalo i njihovo ispisivanje za ljudsko čitanje može se obaviti u uobičajenom decimalnom obliku, a sve potrebne pretvorbe obavljaju programi koji rade na računalu.
III. Kodiranje tekstualnih informacija
Ista informacija može se prikazati (kodirati) u nekoliko oblika. Pojavom računala postalo je potrebno kodirati sve vrste informacija s kojima se suočavaju pojedinac i čovječanstvo u cjelini. Ali čovječanstvo je počelo rješavati problem kodiranja informacija mnogo prije pojave računala. Grandiozna postignuća čovječanstva - pisanje i aritmetika - nisu ništa više od sustava za kodiranje govora i numeričkih informacija. Podaci se nikada ne pojavljuju u čisti oblik, uvijek je nekako reprezentirano, nekako kodirano.
Binarno kodiranje jedan je od najčešćih načina predstavljanja informacija. U računalima, robotima i alatnim strojevima s numeričkim upravljanjem u pravilu su sve informacije s kojima uređaj barata kodirane u obliku riječi binarne abecede.
Od kasnih 1960-ih, računala se sve više koriste za obradu teksta, a sada većina svjetskih osobnih računala (i većina vrijeme) je zauzet obradom tekstualnih informacija. Sve ove vrste informacija u računalu su predstavljene u binarnom kodu, tj. koristi se abeceda s potencijom dvojke (samo dva znaka 0 i 1). To je zbog činjenice da je prikladno prikazati informacije u obliku niza električnih impulsa: nema impulsa (0), postoji impuls (1).
Takvo se kodiranje obično naziva binarnim, a sami logički nizovi nula i jedinica nazivaju se strojnim jezikom.
Sa stajališta računala, tekst se sastoji od pojedinačnih znakova. Znakovi ne uključuju samo slova (velika ili mala, latinična ili ruska), već i brojeve, interpunkcijske znakove, posebne znakove poput "=", "(", "&" itd., pa čak i (obratite posebnu pozornost!) razmake između riječi .
Tekstovi se unose u memoriju računala pomoću tipkovnice. Tipke su napisane poznatim nam slovima, brojevima, interpunkcijskim znakovima i drugim simbolima. U RAM ulaze u binarnom kodu. To znači da je svaki znak predstavljen 8-bitnim binarnim kodom.
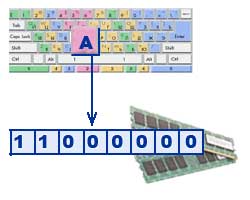 Tradicionalno, za kodiranje jednog znaka koristi se količina informacija jednaka 1 bajtu, tj. I \u003d 1 bajt \u003d 8 bita. Koristeći formulu koja povezuje broj mogućih događaja K i količinu informacija I, možete izračunati koliko se različitih znakova može kodirati (pod pretpostavkom da su znakovi mogući događaji): K = 2 I = 2 8 = 256, tj. za predstavljanje tekstualnih informacija, možete koristiti abecedu s kapacitetom od 256 znakova.
Tradicionalno, za kodiranje jednog znaka koristi se količina informacija jednaka 1 bajtu, tj. I \u003d 1 bajt \u003d 8 bita. Koristeći formulu koja povezuje broj mogućih događaja K i količinu informacija I, možete izračunati koliko se različitih znakova može kodirati (pod pretpostavkom da su znakovi mogući događaji): K = 2 I = 2 8 = 256, tj. za predstavljanje tekstualnih informacija, možete koristiti abecedu s kapacitetom od 256 znakova.
Ovaj broj znakova sasvim je dovoljan za predstavljanje tekstualnih informacija, uključujući velika i mala slova ruske i latinične abecede, brojeve, znakove, grafičke simbole itd.
Kodiranje je da je svakom znaku dodijeljen jedinstveni decimalni kod od 0 do 255 ili odgovarajući binarni kod od 00000000 do 11111111. Dakle, osoba razlikuje znakove po stilu, a računalo po kodu.
Pogodnost bajt-po-bajt kodiranja znakova je očigledna, budući da je bajt najmanji adresabilni dio memorije i, prema tome, procesor može pristupiti svakom znaku zasebno prilikom obrade teksta. S druge strane, 256 znakova sasvim je dovoljno za predstavljanje najrazličitijih znakovnih informacija.
U procesu prikazivanja znaka na zaslonu računala vrši se obrnuti proces - dekodiranje, odnosno pretvaranje koda znaka u njegovu sliku. Važno je da je dodjela određenog koda simbolu stvar dogovora, koji je fiksiran u tablici kodova.
Sada se postavlja pitanje koji osmobitni binarni kod staviti u korespondenciju sa svakim znakom. Jasno je da je ovo uvjetna stvar, možete smisliti mnogo načina za kodiranje.
Svi znakovi računalne abecede označeni su brojevima od 0 do 255. Svaki broj odgovara osmobitnom binarnom kodu od 00000000 do 11111111. Taj je kod jednostavno redni broj znaka u binarnom brojevnom sustavu.
IV . Vrste tablica kodiranja
Tablica u kojoj su svi znakovi računalne abecede dodijeljeni serijski brojevi naziva se tablica kodiranja.
Za različiti tipovi Računalo koristi različite tablice kodiranja.
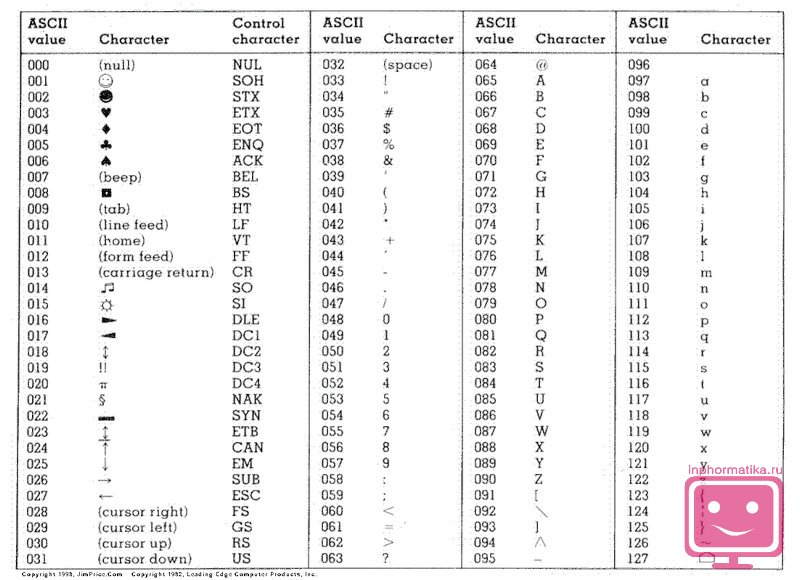
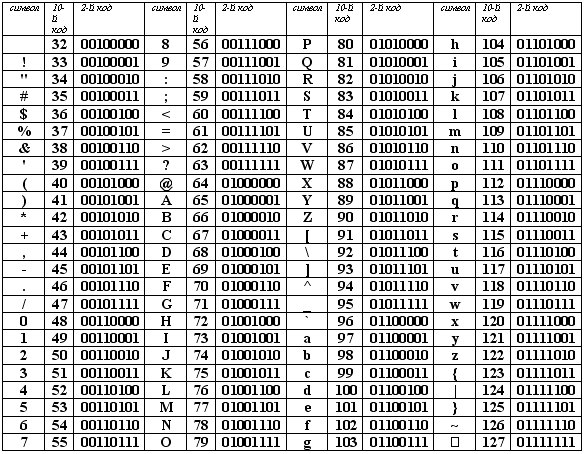
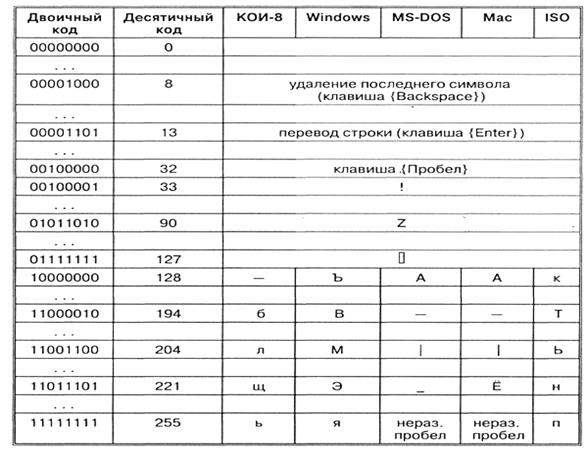
Tablica kodova ASCII (American Standard Code for Information Interchange) usvojena je kao međunarodni standard, kodirajući prvu polovicu znakova numeričkim kodovima od 0 do 127 (kodovi od 0 do 32 nisu dodijeljeni znakovima, već funkcijskim tipkama).
Tablica ASCII kodova podijeljena je u dva dijela.
Samo je prva polovica tablice međunarodni standard, tj. znakova s brojevima od 0 (00000000) do 127 (01111111).
Struktura ASCII tablice kodiranja
| Serijski broj | Kodirati | Simbol |
| 0 - 31 | 00000000 - 00011111 | Znakovi s brojevima od 0 do 31 nazivaju se kontrolni znakovi. Njihova je funkcija upravljanje procesom prikaza teksta na ekranu ili ispisa, davanje zvučnog signala, označavanje teksta i sl. |
| 32 - 127 | 0100000 - 01111111 | Standardni dio tablice (engleski). To uključuje mala i velika slova latinične abecede, decimalne znamenke, interpunkcijske znakove, sve vrste zagrada, reklamne i druge simbole. Znak 32 je razmak, tj. prazno mjesto u tekstu. Sve ostalo odražavaju se određenim znakovima. |
| 128 - 255 | 10000000 - 11111111 | Alternativni dio tablice (ruski). Druga polovica tablice ASCII kodova, nazvana kodna stranica (128 kodova, počevši s 10000000 i završavajući s 11111111), može imati različite opcije, svaka opcija ima svoj broj. Kodna stranica prvenstveno se koristi za prilagođavanje nacionalnih pisama osim latinice. U ruskim nacionalnim kodovima, znakovi ruske abecede smješteni su u ovaj dio tablice. |
Prva polovica tablice ASCII kodova
Skreće se pozornost na činjenicu da su u tablici kodiranja slova (velika i mala) poredana abecednim redom, a brojevi uzlazno. Ovo poštivanje leksikografskog reda u rasporedu znakova naziva se načelo sekvencijalnog kodiranja abecede.
Za slova ruske abecede također se poštuje princip sekvencijalnog kodiranja.
Druga polovica tablice ASCII kodova
Nažalost, trenutno postoji pet različitih kodiranja ćirilice (KOI8-R, Windows. MS-DOS, Macintosh i ISO). Zbog toga se često javljaju problemi s prijenosom ruskog teksta s jednog računala na drugo, s jednog softverskog sustava na drugi.
Kronološki, jedan od prvih standarda za kodiranje ruskih slova na računalima bio je KOI8 ("Information Exchange Code, 8-bit"). Ovo kodiranje korišteno je 70-ih godina prošlog stoljeća na računalima serije EC, a od sredine 80-ih počelo se koristiti u prvim rusificiranim verzijama operativnog sustava UNIX.
Od početka 90-ih, vremena dominacije MS DOS operativnog sustava, kodiranje ostaje CP866 ("CP" je kratica za "Code Page", "kodna stranica").
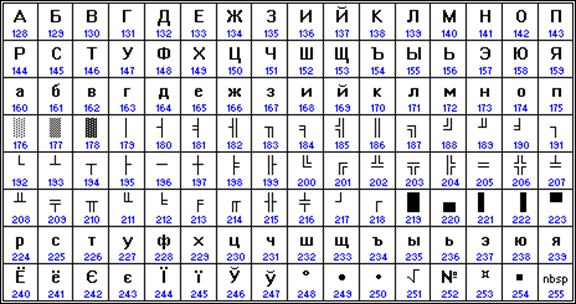
Apple računala s operativnim sustavom Mac OS koriste vlastito Mac kodiranje.

Osim toga, Međunarodna organizacija za standardizaciju (International Standards Organisation, ISO) odobrila je još jedno kodiranje pod nazivom ISO 8859-5 kao standard za ruski jezik.
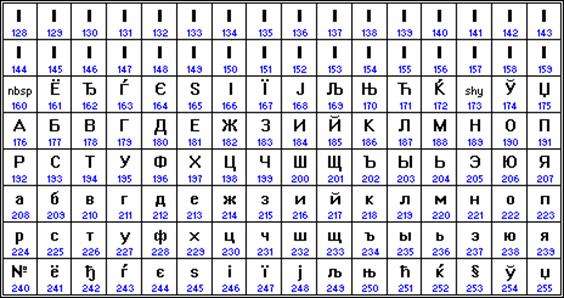
Najčešće korišteno kodiranje je Microsoft Windows, skraćeno CP1251. Predstavio Microsoft; uzeti u obzir raširen operativni sustavi(OS) i drugi softverski proizvodi ove tvrtke u Ruska Federacija postalo je rašireno.
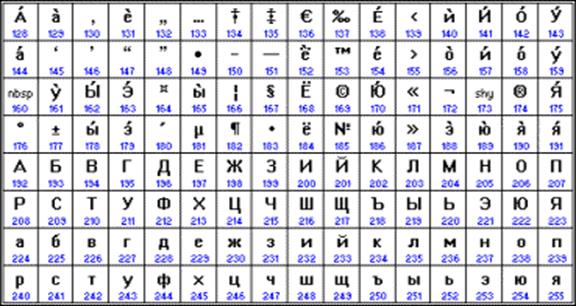
Od kraja 90-ih problem standardizacije kodiranja znakova riješen je uvođenjem novog međunarodnog standarda pod nazivom Unicode.
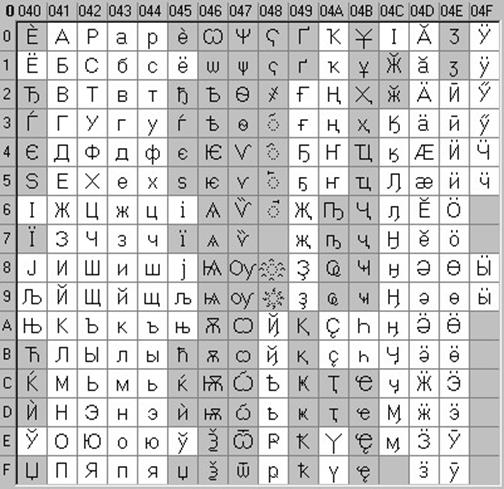
Ovo je 16-bitno kodiranje, tj. ima 2 bajta memorije po znaku. Naravno, u ovom slučaju količina zauzete memorije povećava se 2 puta. Ali takva kodna tablica dopušta uključivanje do 65536 znakova. Potpuna specifikacija Unicode standarda uključuje sve postojeće, izumrle i umjetno stvorene abecede svijeta, kao i mnoge matematičke, glazbene, kemijske i druge simbole.
Interni prikaz riječi u memoriji računala
koristeći ASCII tablicu
Ponekad se dogodi da se tekst koji se sastoji od slova ruske abecede, primljen s drugog računala, ne može pročitati - na zaslonu monitora vidljiva je neka vrsta "abrakadabre". To je zbog činjenice da računala koriste različita kodiranja znakova ruskog jezika.
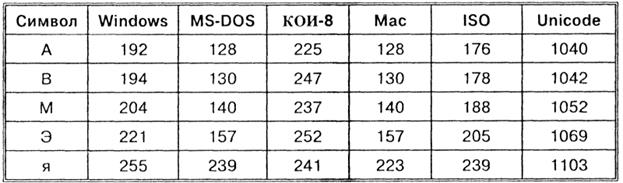
Stoga je svako kodiranje određeno vlastitom tablicom kodova. Kao što se može vidjeti iz tablice, isti binarni kod u razna kodiranja dodijeljeni su različiti simboli.
 Na primjer, niz numeričkih kodova 221, 194, 204 u CP1251 kodiranju tvori riječ "računalo", dok će u drugim kodovima to biti besmislen skup znakova.
Na primjer, niz numeričkih kodova 221, 194, 204 u CP1251 kodiranju tvori riječ "računalo", dok će u drugim kodovima to biti besmislen skup znakova.
Srećom, u većini slučajeva korisnik ne mora brinuti o transkodiranju tekstualnih dokumenata, jer to rade posebni programi pretvarača ugrađeni u aplikacije.
V . Izračun količine tekstualnih informacija
Zadatak 1: Kodirajte riječ "Rim" pomoću tablica za kodiranje KOI8-R i CP1251.
Riješenje:

Zadatak 2: Uz pretpostavku da je svaki znak kodiran jednim bajtom, procijenite količinu informacija sljedeće rečenice:
"Moj ujak najpoštenijih pravila,
Kad sam ozbiljno obolio,
Prisilio se na poštovanje
I nisam se mogao sjetiti boljeg."
Riješenje: Ova fraza ima 108 znakova, uključujući interpunkcijske znakove, navodnike i razmake. Taj broj množimo s 8 bita. Dobivamo 108*8=864 bita.
Zadatak 3: Dva teksta sadrže isti broj znakova. Prvi tekst je napisan na ruskom, a drugi na jeziku plemena Naguri, čija se abeceda sastoji od 16 znakova. Čiji tekst nosi više informacija?
Riješenje:
1) I \u003d K * a (informacijski volumen teksta jednak je proizvodu broja znakova i informacijske težine jednog znaka).
2) Zato što oba teksta imaju isti broj znakova (K), tada razlika ovisi o informacijskom sadržaju jednog znaka abecede (a).
3) 2 a1 = 32, tj. a 1 = 5 bita, 2 a2 = 16, tj. i 2 = 4 bita.
4) I 1 = K * 5 bita, I 2 = K * 4 bita.
5) To znači da tekst napisan na ruskom jeziku nosi 5/4 puta više informacija.
Zadatak 4: Volumen poruke, koja je sadržavala 2048 znakova, bio je 1/512 MB. Odredite snagu abecede.
Riješenje:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bita - količina informacija poruke pretvorena je u bitove.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 bita - pada na jedan znak abecede.
3) 2*16*2048 = 65536 znakova - snaga korištene abecede.
Zadatak 5: Canon LBP laserski pisač ispisuje prosječnom brzinom od 6,3 Kbps. Koliko će trajati ispis dokumenta od 8 stranica ako se zna da na jednoj stranici ima prosječno 45 redaka, 70 znakova po retku (1 znak - 1 bajt)?
Riješenje:
1) Pronađite količinu informacija sadržanu na 1 stranici: 45 * 70 * 8 bita = 25200 bita
2) Pronađite količinu informacija na 8 stranica: 25200 * 8 = 201600 bita
3) Dovodimo do jedinstvenih mjernih jedinica. Da bismo to učinili, prevodimo Mbps u bitove: 6,3 * 1024 = 6451,2 bps.
4) Pronađite vrijeme ispisa: 201600: 6451,2 = 31 sekunda.
Bibliografija
1. Ageev V.M. Teorija informacija i kodiranje: diskretizacija i kodiranje mjernih informacija. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Osnove teorije informacija i kodiranja. - Kijev, Vishcha škola, 1986.
3. Najjednostavnije metode šifriranja teksta / D.M. Zlatopolskog. - M.: Chistye Prudy, 2007. - 32 str.
4. Ugrinovich N.D. Informatika i informacijske tehnologije. Udžbenik za razrede 10-11 / N.D. Ugrinovich. – M.: BINOM. Laboratorij znanja, 2003. - 512 str.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n
KODIRANJE INFORMACIJA
KODIRANJE INFORMACIJA
Uspostavljanje korespondencije između elemenata poruke i signala, uz pomoć koje se oni mogu fiksirati.
Neka U, ,
- mnogo elemenata poruke, a abeceda sa simbolima , Neka se konačan niz simbola zove. riječ u ovoj abecedi. Puno riječi u abecedi A nazvao kod ako je stavljen u korespondenciju jedan na jedan sa skupom U. Svaka riječ uključena u kod, tzv. kodna riječ. Poziva se broj znakova u kodnoj riječi. dužina riječi. Kodne riječi mogu biti iste ili različite. duljina. U skladu s ovim kodom se zove. ujednačena ili neujednačena.
Ciljevi K. i .: prikaz ulaznih informacija u, koordinacija izvora informacija s prijenosnim kanalom, otkrivanje i ispravljanje pogrešaka u prijenosu i obradi podataka, skrivanje značenja poruke (kriptografija) itd. Informacije svojstva objekta u pravilu su takva da se kod može prikazati na najekonomičniji način. Izvorni koder rješava ovaj problem uklanjanjem redundancije iz poruka. Daljnje faze prijenosa podataka - prijenos putem prijenosnog kanala i (ili) pohranjivanje u memorijske uređaje - zahtijevaju otkrivanje i (ili) ispravljanje grešaka koje se u njima javljaju zbog smetnji. Ti se ciljevi postižu korektivnim kodiranjem koje provodi autor kanala. Konačno, informacije iz izobličenja tijekom obrade u računalu izvode se pomoću aritmetike. šifre.
Kodiranje vrijednosti. Prirodni broj N predstavljen u brojevnom sustavu s položajnom težinom, ako odnos postoji

gdje je digitalna abeceda sa P znamenke, " - težine znamenki, - brojevi znamenki. Pojam "pozicijski" znači da u kodnom prikazu (ili samo kodu) broja izraženog uvjetnom jednakošću
kvantitativni ekvivalent povezan sa slikom a l, ovisi o mjestu u kodu. Pojam "značajno" znači da svaka znamenka ima pl. Mala težina narudžbe p 0 u digitalnoj mjernoj tehnici poistovjećuje se s razlučivošću analogno-digitalne pretvorbe. Izbor abecede A i sustavi vaganja R specificira klasifikaciju položajnih brojevnih sustava (kodiranje vrijednosti). U prirodnim sustavima
i ako n- baza brojevnog sustava - prirodni broj, bilo koji broj x može se predstaviti kao
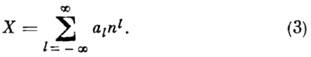
Odabir pomaknute abecede: A= (0, 1, . . ., P-1), A=(-p- 1, . . ., 1, 0), ili simetrično: A = (-p- 1, . . ., -1, 0, 1, . . ., P- 1) omogućuje vam predstavljanje pozitivnih, negativnih ili bilo kojih brojeva. Simetrični sustav mora imati neparnu bazu.
Računalo gotovo isključivo koristi položajni binarni sustav pomaka (n = 2) s brojevima (0, 1) i prirodnim omjerom težina koji predstavljaju niz brojeva
Moguće je, na primjer, koristiti drugačiji skup brojeva. (-1, 1), dajući neke specifične prednosti.
Razvijaju se binarni sustavi čije težine znamenki nisu u prirodnom (2), već u složenijem omjeru, tvoreći, na primjer, Fibonaccijev niz (ili "zlatni rez"). Broj N u Fibonaccijevom kodu predstavljen je omjerom
gdje su Fibonaccijevi brojevi povezani relacijom
Razlaganje (4) broj N dvosmisleno. Za bilo koga N postoji kod u kojem se ne pojavljuju dvije uzastopne nule, a također i kod u kojem jedinice ne postoje zajedno. Ove, kao i druge strukturne značajke Fibonaccijevih kodova i "zlatnih" kodova, čine ih prikladnima za izgradnju samoispravljajućih pretvarača koji pohranjuju i izračunavaju. uređaji, digitalno upravljani servo pogoni itd.
Ternarni brojevni sustavi naib. su ekonomični u smislu da je u ternarnom kodu def. Broj znakova može izraziti najveću raznolikost brojeva. Ima razloga vjerovati da će u budućnosti, upravo zbog ovog svojstva, ternarni simetrični sustav kodiranja s brojevima (-1, 0, 1) uzeti u obzir. tehnologija dominira. Problem ostaje stvaranje elemenata koji implementiraju osnovne funkcije u ternarnoj logici: ternarni pretvarač i ternarni NAND ili ternarni NOR (vidi. Logika),
Nepozicijski kodovi koriste se u specijaliziranim mjerenjima. i izračunati. uređaji . Najjednostavniji od nepozicijskih - jedinstveni kod može se dobiti stavljanjem u (2) n=1 i p 0=1. Ima broj N pojavljuje se kao N=n+l - sekvencijalno zbrojene jedinice. Ovako rade, na primjer, brojači pulsa.
Među nepozicijskim kodnim sustavima ističe se brojevni sustav u rezidualnim klasama (RNS). Broj N u RNS je predstavljen kao uređeni skup ostataka (rezidua) na međusobno prostim bazama p1, . . ., r p;, gdje je najmanji ostatak N modulo R. Sustav temelja str 1, str 2, . . ., r str definira raspon prikaza brojeva P=p1, p2, . . ., r str U SOK aritmetici. operacije se izvode neovisno za svaku osnovu, a to vam omogućuje značajno povećanje njihove izvedbe. U RNS-u je zgodno kontrolirati operacije, budući da su pogreške lokalizirane unutar baza. Specifično za izračunavanje. uređaja koji rade u SOC-u je korištenje tablične aritmetike: vrijednosti funkcije koje se izračunavaju unaprijed se unose u tablicu, a zatim se dohvaćaju kada stignu vrijednosti operanda.
Učinkovito kodiranje izvora informacija ima za cilj uskladiti svojstva informacija izvora informacija (IS) s kanalom prijenosa. AI bi trebao dati izlaz koji se sastoji od slova m- slovna abeceda
štoviše, izgled slova je statistički neovisan i podložan distribuciji
Izvor karakterizira entropija po simbolu
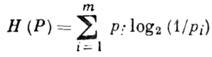
Entropija ![]() ima značenje neizvjesnosti o pojavljivanju sljedećeg znaka na AI izlazu. Jednakost H(P)=0 postiže se degeneriranom raspodjelom R, jer poruka
ima značenje neizvjesnosti o pojavljivanju sljedećeg znaka na AI izlazu. Jednakost H(P)=0 postiže se degeneriranom raspodjelom R, jer poruka
dok je deterministički; jednakost ![]() postiže se jednakovjerojatnom pojavom – situacija najveće neizvjesnosti. Uz m=2 i ujednačen izgled slova a 1 I a 2 entropija je maksimalna i H(P) = 1. Ova vrijednost - nesigurnost s jednako vjerojatnim izborom dviju alternativa - koristi se kao jedinica entropije - 1.
postiže se jednakovjerojatnom pojavom – situacija najveće neizvjesnosti. Uz m=2 i ujednačen izgled slova a 1 I a 2 entropija je maksimalna i H(P) = 1. Ova vrijednost - nesigurnost s jednako vjerojatnim izborom dviju alternativa - koristi se kao jedinica entropije - 1.
Svaki način šifriranja karakterizira usp. broj L(str) slova izlazne abecede po jednom slovu ulazne abecede I T. Za abecedno kodiranje ![]() - duljina riječi u abecedi U r. Ako je kodiranje jedan na jedan, onda
- duljina riječi u abecedi U r. Ako je kodiranje jedan na jedan, onda
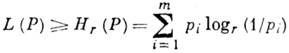
Vrijednost ja (str) = L(P)-H r (P) nazvao redundantnost kodiranja u distribuciji R. Problem je pronaći, u danoj klasi kodiranja jedan na jedan, kodiranje koje ima min. veličina I(P). Postojanje minimuma i njegova vrijednost utvrđuje Shannonov teorem za kanal bez šuma, koji kaže da za izvor s konačnom abecedom A t s entropijom H(P) mogu se slovima izvora dodijeliti kodne riječi na način da usp. duljina kodne riječi L (P) će zadovoljiti uvjete
Optimalan kod je takav da nijedan drugi kod ne daje manju vrijednost L(P).
Konstruktivni postupak za pronalaženje optimalnog. kod za kodiranje određenog skupa poruka predložio je 1952. D. R. Huffman. Ideja je da slova abecede A t raspoređuju se po, a kraće kodne riječi se dodjeljuju vjerojatnijim. Huffmanov kod ima . svojstva: riječ koja odgovara najmanje vjerojatnoj poruci ima najveću duljinu; dvije najmanje vjerojatne poruke kodirane su riječima iste duljine, od kojih jedna završava na nula, a druga na jedinicu (r=2).
Optimalno uniformno kodiranje. Neka izvor bude s abecedom od dva slova i generirajte riječi dužine l. S obzirom na cijeli skup od 2 l riječi (izvorni rječnik) postoji izjava da za i dovoljno velika l izvorni rječnik podijeljen je u dva podskupa: skupinu jednako vjerojatnih riječi (radni izvorni rječnik) i skupinu riječi s ukupnom vjerojatnošću blizu nule ("atipične" sekvence). Ovdje H(R) - entropija po simbolu izvora. Udio riječi u radnom rječniku vrlo je malen i raste l teži nuli. Ideja jednoobraznog ili blokovskog kodiranja je da koder, primajući izvorne riječi kao ulaz, spaja kodne riječi samo s riječima iz radnog rječnika, a sve ostale kodira jednom riječju koja ima značenje greške. Vjerojatnost pogreške može se proizvoljno smanjiti povećanjem duljine izvorne riječi. U ovom slučaju, volumen kodiranih riječi zahtijeva simbole kodne riječi. Budući da su riječi radnog rječnika gotovo jednako vjerojatne, kodne riječi će biti jednako vjerojatne, a entropija po simbolu kodne riječi bit će blizu 1 bita. Koder, dakle, proizvodi riječi duljine , štedeći zbog činjenice da "učitava" svaki znak do najvećeg mogućeg informacijskog opterećenja od 1 bita.
Izvorno kodiranje dobiva novo značenje zbog potrebe "sažimanja" informacijskih nizova podataka u bazama i bankama podataka. Nizovi organizacijskih, ekonomskih, mjernih. informacije imaju tako veliku redundanciju da dopuštaju do 80-85%. Razvijeni sustavi za upravljanje bazama podataka (DBMS) imaju posebne. programi (uslužni programi) za analizu, sažimanje i vraćanje teksta, koji rade na gore navedenim načelima.
Korektivno kodiranje informacija. Njegova je svrha otkriti i (ili) ispraviti pogreške u kodnim riječima koje su se dogodile tijekom prijenosa informacija putem kanala s šumom. Ispravljanje izobličenja moguće je uvođenjem redundancije u prijenosni sustav. U ovom slučaju, iz cijelog skupa riječi kodera kanala N0 samo N odgovarat će prenesenim porukama (dopuštene riječi). Teoretski, u ovom slučaju, udio otkrivenih pogrešaka neće premašiti 1-N/N 0 .
Pretpostavlja se da informacijska riječ U= (u 1, . . ., u n), gdje u j=0, 1, dovodi se na ulaz kanalnog enkodera (u daljnjem tekstu enkoder), koji mu dodjeljuje kodnu riječ X (x 1 , . .., xl), ,
Koder, dakle, zbraja po definiciji. pravilo za riječ U grupa od k=l-n redundantni (korektivni) bitovi. Kodna riječ x ulazi u kanal s šumom, gdje smetnje iskrivljuju neke od simbola x i . Riječ primljena na izlazu kanala Y= (na 1 , . . ., y 2) ulazi u dekoder, koji obnavlja (s aproksimacijom visine tona) riječ x. Kodne riječi se koriste kao vektori u linearnom vektorskom prostoru s Hammingovom metrikom koja određuje udaljenost između vektora
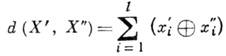
Shannonov teorem za kanale sa smetnjama, koji tvrdi da je uz pomoć prikladnih kodova moguće prenijeti informacije tako da je vjerojatnost pogreške nakon dekodiranja proizvoljno mala, pod uvjetom da brzina prijenosa ne prelazi propusnost komunikacijskog kanala, nije konstruktivan: ne ukazuje na način konstruiranja koda. Prilikom konstruiranja koda od odlučujuće je važnosti izbor modela za pojavu pogreške u prenesenoj riječi.
Naib. raširen je model simetričnog kanala s jednako vjerojatnim pogreškama decomp. tipovi - prijelazi, na primjer, znak 0 u 1 i 1 u 0.
Specifičan je model kanala "s brisanjem". Izlazna abeceda takvog kanala sadrži posebne. simbol za brisanje, u koji se prenose znakovi unesene abecede kada se pojavi greška ove vrste.
Prošireni razl. pretpostavke glede raspodjele pogrešaka u prenesenom nizu simbola (kodna riječ). Model nezavisnih grešaka (kanal bez memorije), model grupiranih grešaka (rafali grešaka), greške locirane na određenom međusobna udaljenost itd. Postoje široko rasprostranjene pretpostavke o ograničenju višestrukosti pogrešaka u kodnim riječima.
Pod potonjom pretpostavkom, korektivna sposobnost koda procjenjuje se brojem grešaka otkrivenih i (ili) ispravljenih uz njegovu pomoć u kodnim riječima. Pretpostavlja se da je u kanalu sa x simbol-po-simbol sumirani (mod 2) vektor šuma Z, tvoreći riječ. Višestrukost rezultirajuće pogreške jednaka je broju jedinica (Hammingova težina). Z. U vektoru iz l elementi ne više od r jedinice se mogu postaviti na različite načine.
Ovo je niz pogrešaka koje se mogu pojaviti tijekom prijenosa.
Glavna karakteristika koda, koja određuje njegovu sposobnost ispravljanja u odnosu na neovisne pogreške, je kodna udaljenost. Kodna udaljenost je najmanja Hammingova udaljenost između svih mogućih riječi = ( , . . ., ) i koda. Kako bi kod otkrio sve kombinacije s pogreške i ispravljene sve kombinacije t pogreške, potrebno je i dovoljno da kodna udaljenost bude jednaka s+t+1.
Široka klasa kodova za simetrični kanal su linearni (grupni) kodovi, na primjer, Hammingovi kodovi, koji se široko koriste za zaštitu informacija u glavnoj memoriji računala. Hammingov kod ima kodnu udaljenost d=3, ispravlja pojedinačne pogreške i otkriva dvostruke pogreške. Ima kontrolne znamenke smještene na pozicijama označenim brojevima 2°, 2, 2 2 , . . . Linearni kod zadan je parom matrica: generiranjem, i provjerom. Redovi generirajuće matrice su linearno neovisni vektori koji čine bazu prostora koji sadrži 2 n elemenata - kodnih riječi. Svaki od redova kontrolne matrice je okomit na redove , i
Enkoder linijskog koda generira kodne riječi prema pravilu X T = U T G. Model izobličenja pretpostavlja da u kanalu s X simbol po simbol sumirani vektor šuma Z, tvoreći riječ Y=X+Z.
Ideja dekodiranja je formiranje proizvoda S T \u003d Y T H T, naziva sindrom. Jednakost S= 0 znači da Z=0, ili se greška ne može detektirati. Sindrom ima 2 k -1 realizacije različite od nule, od kojih se svaka može koristiti za označavanje greške koja se dogodila.
Ciklički. kodovi su uključeni kao podrazred u grupne kodove. U njima, uz riječ x i svi njegovi cikli-lići ulaze. permutacije. Kodne riječi se formiraju kao produkt dva polinoma: U (E) stupanj P- 1, koeficijent to-rogo sastaviti informativnu riječ ti, i generativni g (E) stupanj l-p, nesvodljiv i djeljiv bez ostatka binom (1+ E l). Dekodiranje se sastoji u dijeljenju primljene riječi (polinoma) sa g(E). Prisutnost ostatka različitog od nule ukazuje na prisutnost greške. Ciklički. kodovi su obično nesustavni.
Specijalista. ciklički kodovi su dizajnirani za otkrivanje i ispravljanje nizova pogrešaka, na primjer, požarni kodovi, definirani generiranjem polinoma oblika g(E) = =p(E)(E c +1), Gdje p(E) - nesvodljivi polinom i kvantitet S određuje se duljinom ispravljenih i otkrivenih nizova pogrešaka.
Hrpe pogrešaka tipične su za uređaje za magnetsku pohranu. nosači, posebno za magnetske pogone. diskovi (NMD) moderni. računalo (vidi memorija uređaja). Za zaštitu podataka u NMD, stoga, K. i naširoko se koristi. ciklički kodovi implementirani hardverom.
Aritmetički kodovi dizajniran za otkrivanje grešaka koje su se dogodile tijekom izvođenja aritmetike. računalne operacije. U teoriji aritmetike. kodiranja, uvode se pojmovi težine, udaljenosti i pogreške koji se razlikuju od Hammingovih. Aritmetika težina broja je definirana kao min. broj članova u reprezentaciji broja u obliku , ![]() . Pogreške, uslijed kojih se veličina broja mijenja za, r "= 0, 1, 2, . . ., zovu se aritmetičke. Aritmetička udaljenost između N 1 I N 2 - aritmetika težina razlike jednaka je višestrukosti pogreške koja prevodi broj N 1 V N2, te utvrđuje aritmetiku popravne sposobnosti. kod je sličan Hammingovoj udaljenosti.
. Pogreške, uslijed kojih se veličina broja mijenja za, r "= 0, 1, 2, . . ., zovu se aritmetičke. Aritmetička udaljenost između N 1 I N 2 - aritmetika težina razlike jednaka je višestrukosti pogreške koja prevodi broj N 1 V N2, te utvrđuje aritmetiku popravne sposobnosti. kod je sličan Hammingovoj udaljenosti.
Zajedničko AN- kodiranje brojeva N- operand - provodi se množenjem s posebno odabranim faktorom A. Dakle, kod 3A, koji ima kodnu udaljenost 2, otkriva pojedinačne pogreške dijeljenjem zbroja s 3. Pogreške se otkrivaju s ostatkom koji nije nula: aritmetička vrijednost. greške 2 i nije djeljiv ni sa 3. Osim pojedinačnih pogrešaka, kod A=3 nalazi se i dio dvostrukih pogrešaka - onih kod kojih točan i pogrešan rezultat imaju neusklađene ostatke nakon dijeljenja s 3.
Kriptografija se provodi zamjenom, kada se svakom slovu šifrirane poruke dodjeljuje određeno. znak (npr. drugo slovo), bilo permutacijom, kada se slova unutar umjetnih blokova teksta mijenjaju, ili kombinacijom ovih metoda. Shannon je pokazao da su mogući kriptogrami koji se ne mogu dešifrirati za prihvatljivu .
Lit.: 1) Stakhov A.P., Uvod u algoritamsku teoriju mjerenja, M., 1977; vlastiti, Kodovi zlatnog reza, M., 1984; 2) Akushsky I., Yuditsky D., Strojna aritmetika u rezidualnim klasama, Moskva, 1968.; 3) Gal-lager R., Teorija informacija i pouzdane komunikacije, prev. s engleskog, M., 1974.; 4) Dadaev Yu.G., Teorija aritmetičkih kodova, M., 1981; 5) Aršinov M. N., Sadovski L. E., Kodovi i matematika, Moskva, 1983. L. N. Efimov.
Fizička enciklopedija. U 5 svezaka. - M.: Sovjetska enciklopedija. Glavni urednik A. M. Prokhorov. 1988 .
Pogledajte što je "KODIRANJE INFORMACIJA" u drugim rječnicima:
kodiranje informacija- Proces transformacije i (ili) prezentiranja podataka. [GOST 7.0 99] Teme aktivnosti knjižnice informacija EN kodiranje informacija FR codage de l'information ... Tehnički prevoditeljski priručnik