Teksta informācijas kodēšana. Pabeigt nodarbības — zināšanu hipermārkets
Priekšmets
- Kodēšana teksta informācija.
Mērķis
- Iepazīstināt ar tekstu kodēšanas metodēm datora atmiņā.
Nodarbību laikā
Datora laukā teksts ir jebkuru rakstzīmju secība. Mūsdienās mašīnas izmanto šādu rakstzīmju kopu, kas satur līdz 256 rakstzīmēm.
Turklāt katram ir savs astoņu bitu binārais kods. Tādējādi datora atmiņā jebkura teksta rakstzīme aizņem 8 bitus vai 1 baitu.
Paturot to prātā, šķiet, ka ir iespējams izmērīt atmiņas apjomu, kas nepieciešams jebkura teksta dokumenta glabāšanai.
1 bitam (bināram ciparam) ir divas nozīmes, katra bita pievienošana kodam dubulto iegūto kombināciju skaitu: 2 biti - četras iespējas, 3 biti - astoņi, 4 biti - sešpadsmit utt.
Piemēram, A4 rakstāmmašīnas lapā ir aptuveni 55 rindiņas. Katrs no tiem satur apmēram 60 rakstzīmes.
Izmantojot šo informāciju, mēs varam saskaitīt teksta informācijas daudzumu konkrētajā lapā.
Katra rakstzīme ir 1 baits informācijas, un kopējais rakstzīmju skaits ir 3300 (60 reizes 55). Izrādās, ka informācijas apjoms lapā ir ap 3 KB.
Binārie kodi un tiem atbilstošās rakstzīmes ir saistītas ar kodēšanas tabulu. Visas datorā izmantotās tabulas ir balstītas uz Amerikas ASCII4 standartu. Tas definē pirmos 128 kodus ( vēstules, skaitļi, zīmes). Atlikušie 128 tiek izmantoti nacionālo alfabētu (krievu, ķīniešu, arābu) speciālajām rakstzīmēm un burtiem. Un, tā kā tam nebija vienotu standartu, radās daudzi kodējumi, tostarp kirilicai.
Tāpēc dažreiz jūs varat redzēt kāda tekstu "svītru" kopas formā.
Lai šādus tekstus varētu lasīt, ir pārveidotāju programmas. Tie aizstāj katras rakstzīmes bināro kodu ar cita kodējuma kodu. Un bieži vien lietotājam ir jānorāda, no kura kodējuma notiek reklāmguvums.
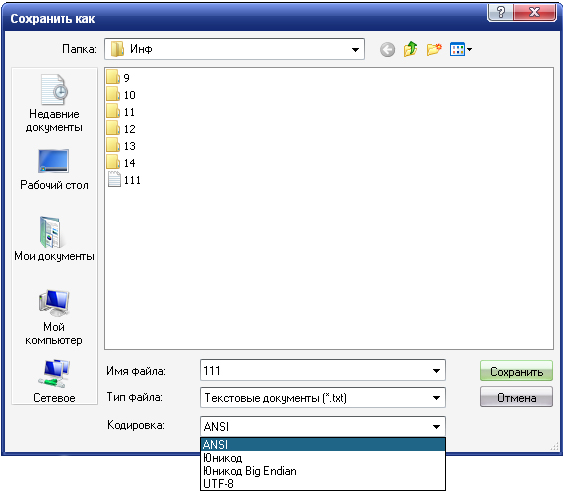
Taču jau ir programmas, kas var automātiski noteikt avota teksta kodējumu.
Tātad tiek izsaukta tabula, kurā visiem mašīnas alfabēta simboliem ir piešķirti atbilstošie sērijas numuri kodēšanas tabula.
ASCII kodu tabula
Kā jau minēts, ASCII tabula (American Standard Code for Information Interchange) ir kļuvusi par starptautisko standartu personālajiem datoriem.
Varat arī atrast citu tabulu - KOI-8 (Informācijas apmaiņas kods), ko izmanto datortīklos.
ASCII kodu tabula ir sadalīta divas daļas.
Starptautiskajā praksē standarts ir tikai tabulas pirmā daļa, tas ir, rakstzīmes ar cipariem no 0 (00000000) līdz 127 (01111111). Tie ir latīņu alfabēta mazie un lielie burti, cipari, pieturzīmes, dažāda veida iekavas, komerciālie un citi simboli.
Rakstzīmju numerāciju no 0 līdz 31 parasti sauc par kontroles rakstzīmēm. Tie kontrolē teksta parādīšanas procesu ekrānā vai drukāšanu, skaņas signālu skaļruņiem un teksta iezīmēšanu.
32. rakstzīme ir atstarpe vai tukša vieta tekstā.
Es vēršu jūsu uzmanību uz to, ka kodēšanas tabulā burti (lielie un mazie) ir sakārtoti alfabētiskā secībā, un cipari ir sakārtoti vērtību augošā secībā. Šo leksikogrāfiskās kārtības ievērošanu rakstzīmju izkārtojumā sauc par secīgu alfabēta kodēšanas principu.
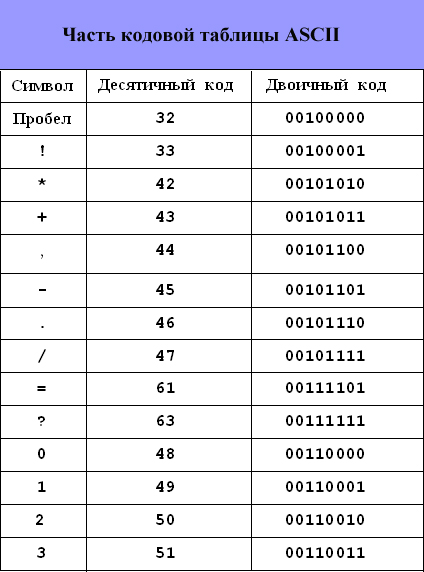
Otra puse ASCII tabulas sauc par kodu lapu. Tie ir atlikušie 128 kodi no 10000000 līdz 11111111, kuriem ir dažādas iespējas, un katrai (!) opcijai ir savs numurs.
Pirmkārt, kodu lapa tiek izmantota, lai pielāgotu nacionālos alfabētus, kas atšķiras no latīņu valodas. Krievu nacionālajos kodējumos krievu alfabēta rakstzīmes ir ievietotas šajā tabulas daļā. Tātad katrai valodai atsevišķi.
Unikoda kodējums
Šis ir 16 bitu kodējums — tajā ir 2 baiti atmiņa katrai rakstzīmei.
Attiecīgi aizņemtās atmiņas apjoms palielinās 2 reizes. Bet šāda kodu tabula var saturēt līdz 65536 rakstzīmēm.
Pilnajā Unicode versijā ir iekļauti visi pasaules esošie un izmirušie alfabēti un daudzi matemātikas, mūzikas, ķīmiskie simboli.
Programmas darbam ar tekstu
Vēlme vienkāršot darbu ar tekstu ir novedusi pie daudzu īpaši šim nolūkam paredzētu programmu - teksta redaktoru - izveidošanas.
Teksta redaktors nav tikai rakstāmmašīnas aizstājējs, bet gan universāls rīks darbam ar tekstiem.
Tie sniedz ļoti plašas iespējas manipulēt ar teksta dokumentiem.
Šādās programmās jūs varat strādāt ne tikai ar atsevišķām rakstzīmēm, bet arī ar vārdi, rindiņas, rindkopas, grafika. Papildus tādām darbībām kā ierakstīšana, kopēšana, saglabāšana, pārvietošana un fragmentu dzēšana, fonta, krāsas un izmēra maiņa, teksta nosūtīšana uz diska un drukāšana.
Apstrādātais teksts tiek parādīts it kā dotā formāta papīra loksnes veidā, kas ritinās ekrānā.
Tekstu failu glabāšanas priekšrocības:
1) ietaupiet papīru
2) kompakts izvietojums
3) iespēja uzreiz kopēt uz citiem medijiem
4) iespēja pārsūtīt tekstu pa tīkla vai interneta līnijām
Jautājumi
1. Kas ir kodēšanas tabula?
2. Kāds kodējums ir kļuvis par starptautisko standartu?
3. Ko sauc par teksta redaktoru?
Izmantoto avotu saraksts
1. Nodarbība par tēmu: “Teksta kodēšanas process”, Pavlovs M. S., Čerkasi
2. Eremins E.A. Kā darbojas tastatūras buferis / Informātika #45, 2004
3. Semakins I.G.
P Pirmās 128 rakstzīmes ir standartizētas. Tie ir vienādi absolūti visos kodējumos visā pasaulē. Ja mēs runājam par simboliem, tad tas ir viss angļu alfabēts, cipari un pamata rakstzīmes. Atlikušās 128 pozīcijas tika piešķirtas "pēc nacionālo alfabētu un papildu rakstzīmju žēlastības". Tā tas ir lielākajā daļā valstu. Tomēr Krievijā nav viena vai pat divu nacionālo kodējumu. Tie ir tieši pieci. Tādējādi, ja teksts ir rakstīts krievu valodā vienā kodējumā, tad citā tas izskatīsies kā absolūti nejaušs dažādu rakstzīmju kopums.
M Daudzi šī Wiki raksta lasītāji droši vien jautās: "Bet kāpēc Krievijā ir tik daudz dažādu kodējumu?". Lai atbildētu uz šo jautājumu, jums būs jāveic īsa atkāpe vēsturē. Viss sākās pagājušā gadsimta 70. gados. Toreiz mūsu datoros parādījās UNIX operētājsistēma (nevis personīgajos — tās toreiz neeksistēja). Protams, tas tika pielāgots krievu valodai. Toreiz parādījās pirmais kodējums ar nosaukumu KOI-8. Kopš tā laika tas ir kļuvis par "de facto" standartu visiem UNIX līdzīgiem operētājsistēmas- piemēram, Linux.
H nedaudz vēlāk sākās personālo datoru uzvaras gājiens. Un līdz ar tiem ļoti plaši ir izplatījusies operētājsistēma MS-DOS. Tās izstrādātājs Microsoft rusifikācijas laikā neizmantoja KOI-8, bet nāca klajā ar savu kodējumu, ko sauc par DOS (koda lapa 866). Šajā tabulā starp papildu rakstzīmēm parādījās rāmja elementi, kas ievērojami atviegloja tabulu zīmēšanu dažādos teksta redaktoros. Tas arī veicināja DOS kodēšanas izplatību. Starp citu, apmēram tajā pašā laikā vai nedaudz vēlāk Krievijas tirgus Iznāca Macintosh datori. Protams, tajās instalētās operētājsistēmas rusifikācijas laikā tika izveidota vēl viena simbolu tabula - MAC. Tiesa, jāatzīmē, ka tas gandrīz nekad netika izmantots pašu Mac datoru nelielā izplatības dēļ.
IN 1990. gadā Microsoft izlaida jaunu operētājsistēmu Windows versija 3.0. Tajā tika iebūvēts valsts valodu atbalsts. Bet šeit ir tas, kas ir interesanti - nez kāpēc Microsoft speciālisti neizmantoja jau esošo krievu DOS kodējumu, bet atkal izgudroja jaunu - Win (koda lapa 1251). Visticamāk, tas tika darīts tāpēc, ka tabulā tika ieviestas citas papildu rakstzīmes rāmju un līdzīgu rakstzīmju vietā. Bet mēs, visticamāk, nezināsim droši par Win kodējuma parādīšanās iemesliem. Jau vēlāk starptautiskā organizācija International Organization for Standardization, kas nodarbojas ar standartizācijas jautājumiem, vērsa uzmanību uz vairāku nacionālo kodējumu esamības problēmu Krievijā un dažās citās valstīs. Un atkal tā vietā, lai par pamatu ņemtu visizplatītāko kodējumu (toreiz tā bija Win tabula), ISO pārstāvji izgudroja savu (ISO 8859-5). Bet praktisks pielietojums viņa nesaņēma. Un, lai gan ISO kodējums tiek atbalstīts visās pārlūkprogrammās, iespējams, nav nevienas vietnes, kas to izmantotu.
UZ Turklāt mēģinājumi "uzspiest" universālo Unicode kodējumu ir novēroti diezgan ilgu laiku. Tās veidotāji ieteica katrai rakstzīmei izmantot nevis vienu, bet divus baitus. Tas ļauj palielināt iespējamo vērtību skaitu līdz 65535 un iekļaut tabulā visas esošo alfabētu rakstzīmes. Tiesa, visi šie mēģinājumi paliek absolūti neauglīgi.
Tāpēc mēs izceļam vairākas kodēšanas atšķirību kopīgās iezīmes:
1) Kopā ir 256 rakstzīmes.
2) Pirmās 128 rakstzīmes ir standartizētas, tās ir vienādas visā pasaulē un sastāv no angļu alfabēta, cipariem un zīmēm.
3) Atlikušie 128 tiek piešķirti nacionālo alfabētu un papildu rakstzīmju "žēlastībā".
4) Krievijā ir 5 dažādi kodējumi!
5) Teksts, kas rakstīts vienā kodējumā krievu valodā, citā kodējumā, izskatīsies pēc dažādām nejaušām rakstzīmēm, tāpēc katrs kodējums ir individuāls un neatbalsta ciešu "sadarbību" ar citu kodējumu.
6) Katrs kodējums ir norādīts savā kodu tabulā. Uz to pašu binārais kods V dažādi kodējumi tiek piešķirti dažādi simboli.
7) Kopēja iezīme lielākajā daļā kodējumu tiek izmantota 1 rakstzīmei, kas ir tieši 1 baits. Ir Unicode kodējums, kur tā veidotāji ieteica katrai rakstzīmei izmantot nevis vienu, bet divus baitus. Tas ļauj palielināt iespējamo vērtību skaitu līdz 65535 un iekļaut tabulā visas esošo alfabētu rakstzīmes. Tiesa, visi šie mēģinājumi paliek absolūti neauglīgi.
Atšķirība starp teksta failiem, kas izveidoti dažādos kodējumos
UZ Kad teksta fails ir kodēts, tas tiek saglabāts saskaņā ar kodēšanas standartu, īpašu noteikumu kopumu, kas katrai teksta rakstzīmei piešķir skaitlisku vērtību. Ir daudz dažādu kodēšanas standartu, kas atspoguļo dažādās valodās izmantotās rakstzīmju kopas, un daži no šiem standartiem atbalsta tikai vienas valodas rakstzīmes. Tātad ķīniešu tekstam var izmantot GB2312-80 kodēšanas standartu vienkāršotās rakstīšanas gadījumā un Big5 kodēšanas standartu tradicionālās rakstīšanas gadījumā.
P Tā kā Microsoft Word izmanto Unicode kodēšanas standartu (Unicode. Rakstzīmju kodēšanas standarts, ko izstrādājis Unicode konsorcijs. Izmantojot vairāk nekā vienu baitu, lai attēlotu katru rakstzīmi, Unicode ļauj attēlot gandrīz visas pasaules valodas vienā rakstzīmju kopā.) , varat atvērt un saglabāt Microsoft Word failos, izmantojot dažādu valodu kodēšanas standartus. Piemēram, strādājot ar operētājsistēmu, kas izmanto interfeisu angļu valoda, programmā Microsoft Word varat atvērt teksta failu, kas izveidots, izmantojot grieķu vai japāņu valodas kodēšanas standartu.
Saturs
I. Informācijas kodēšanas vēsture………………………………..3
II. Kodēšanas informācija……………………………………………4
III. Teksta informācijas kodēšana……………………………….4
IV. Kodēšanas tabulu veidi…………………………………………………6
V. Teksta informācijas apjoma aprēķins…………………………14
Izmantotās literatūras saraksts…………………………………..16
es
.
Informācijas kodēšanas vēsture
Cilvēce izmanto teksta šifrēšanu (kodēšanu) kopš brīža, kad parādījās pirmā slepenā informācija. Šeit ir vairākas teksta kodēšanas metodes, kas tika izgudrotas dažādos cilvēka domas attīstības posmos:
Kriptogrāfija ir kriptogrāfija, rakstības maiņas sistēma, lai padarītu tekstu nesaprotamu nezinātājiem;
Morzes kods vai neviendabīgs telegrāfa kods, kurā katrs burts vai rakstzīme ir attēlota ar savu īsu elementāru paku kombināciju elektriskā strāva(punkti) un trīskāršā ilguma elementārpakāpes (domuzīmes);
Zīmju valoda ir zīmju valoda, ko lieto cilvēki ar dzirdes traucējumiem.
Viena no agrākajām zināmajām šifrēšanas metodēm nes Romas imperatora Jūlija Cēzara (1. gadsimtā pirms mūsu ēras) vārdu. Šīs metodes pamatā ir katra šifrētā teksta burta aizstāšana ar citu, mainot alfabētu no sākotnējā burta par noteiktu rakstzīmju skaitu, un alfabēts tiek lasīts aplī, tas ir, pēc burta i tiek ņemts vērā a. Tātad vārds "baits", pārvietojot divas rakstzīmes pa labi, tiek kodēts ar vārdu "gvlf". Dotā vārda atšifrēšanas apgrieztais process ir aizstāt katru šifrēto burtu ar otro pa kreisi no tā.
II.
Informācijas kodēšana
Kods ir vienošanos (vai signālu) kopa dažu iepriekš definētu jēdzienu ierakstīšanai (vai pārraidīšanai).
Informācijas kodēšana ir noteikta informācijas attēlojuma veidošanas process. Šaurākā nozīmē termins "kodēšana" bieži tiek saprasts kā pāreja no viena informācijas pasniegšanas veida uz citu, ērtāku uzglabāšanai, pārraidei vai apstrādei.
Parasti katrs attēls, kad tas ir kodēts (dažkārt saka - šifrēts), tiek attēlots ar atsevišķu rakstzīmi.
Zīme ir atšķirīgu elementu ierobežotas kopas elements.
Šaurākā nozīmē termins "kodēšana" bieži tiek saprasts kā pāreja no viena informācijas pasniegšanas veida uz citu, ērtāku uzglabāšanai, pārraidei vai apstrādei.
Dators var apstrādāt teksta informāciju. Ievadot datorā, katrs burts tiek kodēts ar noteiktu numuru, un, izvadot ārējās ierīcēs (ekrānā vai drukā), cilvēka uztverei tiek veidoti burtu attēli, izmantojot šos ciparus. Atbilstību starp burtu un ciparu kopu sauc par rakstzīmju kodējumu.
Parasti visi skaitļi datorā tiek attēloti, izmantojot nulles un vieniniekus (nevis desmit ciparus, kā tas ir ierasts cilvēkiem). Citiem vārdiem sakot, datori parasti darbojas binārajā sistēmā, jo ierīces to apstrādei ir daudz vienkāršākas. Ciparu ievadīšanu datorā un izvadīšanu cilvēka lasīšanai var veikt parastajā decimāldaļā, un visas nepieciešamās konvertācijas veic datorā strādājošas programmas.
III.
Teksta informācijas kodēšana
To pašu informāciju var pasniegt (kodēt) vairākos veidos. Līdz ar datoru parādīšanos radās nepieciešamība kodēt visa veida informāciju, ar ko nodarbojas gan indivīds, gan cilvēce kopumā. Bet cilvēce sāka risināt informācijas kodēšanas problēmu ilgi pirms datoru parādīšanās. Cilvēces grandiozie sasniegumi - rakstīšana un aritmētika - ir nekas vairāk kā runas kodēšanas sistēma un skaitliskā informācija. Informācija nekad neparādās tīrā formā, tas vienmēr ir kaut kā attēlots, kaut kā iekodēts.
Binārā kodēšana ir viens no visizplatītākajiem informācijas attēlošanas veidiem. Datoros, robotos un darbgaldos ar ciparu vadību, kā likums, visa informācija, ar ko ierīce nodarbojas, tiek kodēta binārā alfabēta vārdu veidā.
Kopš 1960. gadu beigām datorus arvien vairāk izmanto teksta apstrādei, un tagad lielākā daļa pasaules personālo datoru (un Lielākā daļa laiks) ir aizņemts ar teksta informācijas apstrādi. Visi šie informācijas veidi datorā tiek attēloti binārā kodā, t.i., tiek izmantots alfabēts ar jaudu divi (tikai divas rakstzīmes 0 un 1). Tas ir saistīts ar faktu, ka informāciju ir ērti attēlot elektrisko impulsu secības veidā: nav impulsa (0), ir impulss (1).
Šādu kodēšanu parasti sauc par bināro, un pašas nulles un vieninieku loģiskās secības sauc par mašīnvalodu.
No datora viedokļa teksts sastāv no atsevišķām rakstzīmēm. Rakstzīmes ietver ne tikai burtus (lielos vai mazos burtus, latīņu vai krievu), bet arī ciparus, pieturzīmes, speciālās rakstzīmes, piemēram, "=", "(", "&" utt.) un pat (pievērsiet īpašu uzmanību!) atstarpes starp vārdiem. .
Teksti tiek ievadīti datora atmiņā, izmantojot tastatūru. Taustiņi ir rakstīti mums pazīstami burti, cipari, pieturzīmes un citi simboli. Viņi ievada RAM binārā kodā. Tas nozīmē, ka katra rakstzīme tiek attēlota ar 8 bitu bināro kodu.
Tradicionāli vienas rakstzīmes kodēšanai tiek izmantots informācijas apjoms, kas vienāds ar 1 baitu, t.i., I \u003d 1 baits \u003d 8 biti. Izmantojot formulu, kas saista iespējamo notikumu skaitu K un informācijas daudzumu I, varat aprēķināt, cik daudz dažādu rakstzīmju var iekodēt (pieņemot, ka rakstzīmes ir iespējamie notikumi): K \u003d 2 I
= 2 8
= 256, t.i., teksta informācijas attēlošanai var izmantot alfabētu ar 256 rakstzīmju ietilpību.
Šis rakstzīmju skaits ir pietiekami, lai attēlotu teksta informāciju, ieskaitot krievu un latīņu alfabēta lielos un mazos burtus, ciparus, zīmes, grafiskos simbolus utt.
Kodēšana ir tāda, ka katrai rakstzīmei tiek piešķirta unikāla decimālkods no 0 līdz 255 vai atbilstošs binārais kods no 00000000 līdz 11111111. Tādējādi cilvēks atšķir rakstzīmes pēc stila, bet dators pēc koda.
Rakstzīmju kodēšanas ērtība ir acīmredzama, jo baits ir mazākā adresējamā atmiņas daļa un līdz ar to procesors, veicot teksta apstrādi, var piekļūt katrai rakstzīmei atsevišķi. No otras puses, ar 256 rakstzīmēm ir pilnīgi pietiekami, lai attēlotu visdažādāko rakstzīmju informāciju.
Rakstzīmes parādīšanas procesā datora ekrānā tiek veikts apgrieztais process - dekodēšana, tas ir, rakstzīmes koda pārvēršana tā attēlā. Būtiski, ka konkrēta koda piešķiršana simbolam ir vienošanās jautājums, kas tiek fiksēts kodu tabulā.
Tagad rodas jautājums, kuru astoņu bitu bināro kodu ievietot sarakstē ar katru rakstzīmi. Ir skaidrs, ka tas ir nosacīts jautājums, jūs varat izdomāt daudzus veidus, kā kodēt.
Visas datora alfabēta rakstzīmes ir numurētas no 0 līdz 255. Katrs cipars atbilst astoņu bitu binārajam kodam no 00000000 līdz 11111111. Šis kods ir vienkārši rakstzīmes kārtas numurs binārajā skaitļu sistēmā.
IV
. Kodēšanas tabulu veidi
Tabulu, kurā visām datora alfabēta rakstzīmēm ir piešķirti sērijas numuri, sauc par kodēšanas tabulu.
Priekš dažādi veidi Dators izmanto dažādas kodēšanas tabulas.
ASCII (American Standard Code for Information Interchange) kodu tabula ir pieņemta kā starptautisks standarts, kas kodē rakstzīmju pirmo pusi ar ciparu kodiem no 0 līdz 127 (kodi no 0 līdz 32 tiek piešķirti nevis rakstzīmēm, bet gan funkciju taustiņiem).
ASCII kodu tabula ir sadalīta divās daļās.
Tikai tabulas pirmā puse ir starptautisks standarts, t.i. rakstzīmes ar cipariem no 0 (00000000) līdz 127 (01111111).
ASCII kodēšanas tabulas struktūra
| Sērijas numurs | Kods | Simbols |
| 0 - 31 | 00000000 - 00011111 | Rakstzīmes ar cipariem no 0 līdz 31 sauc par kontroles rakstzīmēm. To funkcija ir kontrolēt teksta parādīšanas ekrānā vai drukāšanas procesu, skaņas signāla došanu, teksta iezīmēšanu utt. |
| 32 - 127 | 0100000 - 01111111 | Standarta tabulas daļa (angļu val.). Tas ietver latīņu alfabēta mazos un lielos burtus, decimālciparus, pieturzīmes, visa veida iekavas, komerciālos un citus simbolus. 32. rakstzīme ir atstarpe, t.i. tukša vieta tekstā. Visu pārējo atspoguļo noteiktas zīmes. |
| 128 - 255 | 10000000 - 11111111 | Alternatīvā tabulas daļa (krievu val.). ASCII kodu tabulas otrajā pusē, ko sauc par kodu lapu (128 kodi, sākot ar 10000000 un beidzot ar 11111111), var būt dažādas opcijas, katrai opcijai ir savs numurs. Kodu lapa galvenokārt tiek izmantota, lai ievietotu nacionālos rakstus, kas nav latīņu valoda. Krievu nacionālajos kodējumos krievu alfabēta rakstzīmes ir ievietotas šajā tabulas daļā. |
ASCII kodu tabulas pirmā puse
Jāpievērš uzmanība tam, ka kodēšanas tabulā burti (lielie un mazie) ir sakārtoti alfabētiskā secībā, un cipari ir sakārtoti augošā secībā. Šo leksikogrāfiskās kārtības ievērošanu rakstzīmju izkārtojumā sauc par alfabēta secīgās kodēšanas principu.
Krievu alfabēta burtiem tiek ievērots arī secīgās kodēšanas princips.
ASCII kodu tabulas otrā puse
Diemžēl šobrīd ir pieci dažādi kirilicas kodējumi (KOI8-R, Windows. MS-DOS, Macintosh un ISO). Šī iemesla dēļ bieži rodas problēmas ar krievu valodas teksta pārsūtīšanu no viena datora uz otru, no vienas programmatūras sistēmas uz citu.
Hronoloģiski viens no pirmajiem standartiem krievu burtu kodēšanai datoros bija KOI8 ("Informācijas apmaiņas kods, 8-bit"). Šis kodējums tika izmantots 70. gados EC sērijas datoru datoros, un no 80. gadu vidus to sāka izmantot pirmajās operētājsistēmas UNIX rusificētajās versijās.
No 90. gadu sākuma, MS DOS operētājsistēmas dominēšanas laika, kodējums paliek CP866 ("CP" nozīmē "koda lapa", "koda lapa").
Apple datori, kuros darbojas operētājsistēma Mac OS, izmanto savu Mac kodējumu.
Turklāt Starptautiskā standartizācijas organizācija (Starptautiskā standartizācijas organizācija, ISO) apstiprināja citu kodējumu ar nosaukumu ISO 8859-5 kā krievu valodas standartu.
Pašlaik visbiežāk izmantotais kodējums ir Microsoft Windows, saīsināts kā CP1251. Ieviesa Microsoft; ņemot vērā plaši izplatīts operētājsistēmām (OS) un citiem šī uzņēmuma programmatūras produktiem Krievijas Federācija tas ir kļuvis plaši izplatīts.
Kopš 90. gadu beigām rakstzīmju kodēšanas standartizācijas problēma ir atrisināta, ieviešot jaunu starptautisku standartu ar nosaukumu Unicode.
Šis ir 16 bitu kodējums, t.i. tai ir 2 baiti atmiņas katrai rakstzīmei. Protams, šajā gadījumā aizņemtās atmiņas apjoms palielinās 2 reizes. Bet šāda kodu tabula ļauj iekļaut līdz 65536 rakstzīmēm. Pilnīgā Unicode standarta specifikācijā ir iekļauti visi pasaulē esošie, izmirušie un mākslīgi radītie alfabēti, kā arī daudzi matemātiskie, muzikālie, ķīmiskie un citi simboli.
Vārdu iekšējais attēlojums datora atmiņā
izmantojot ASCII tabulu
Dažreiz gadās, ka tekstu, kas sastāv no krievu alfabēta burtiem, kas saņemts no cita datora, nevar izlasīt - monitora ekrānā ir redzama sava veida "abrakadabra". Tas ir saistīts ar faktu, ka datori izmanto dažādus krievu valodas rakstzīmju kodējumus.
Tādējādi katrs kodējums ir norādīts ar savu kodu tabulu. Kā redzams tabulā, vienam un tam pašam binārajam kodam tiek piešķirtas dažādas rakstzīmes dažādos kodējumos.
Piemēram, ciparu kodu 221, 194, 204 secība CP1251 kodējumā veido vārdu "dators", savukārt citos kodējumos tā būs bezjēdzīga rakstzīmju kopa.
Par laimi, vairumā gadījumu lietotājam nav jāuztraucas par teksta dokumentu pārkodēšanu, jo to veic īpašas lietojumprogrammās iebūvētas pārveidotāju programmas.
V
. Teksta informācijas apjoma aprēķins
1. uzdevums:
Kodējiet vārdu "Roma", izmantojot KOI8-R un CP1251 kodēšanas tabulas.
Risinājums:
2. uzdevums:
Pieņemot, ka katra rakstzīme ir kodēta ar vienu baitu, aprēķiniet šāda teikuma informācijas apjomu:
"Mans visgodīgāko noteikumu tēvocis,
Kad es nopietni saslimu,
Viņš piespieda sevi cienīt
Un es nevarēju iedomāties labāku.
Risinājums:
Šajā frāzē ir 108 rakstzīmes, ieskaitot pieturzīmes, pēdiņas un atstarpes. Mēs reizinām šo skaitli ar 8 bitiem. Mēs iegūstam 108 * 8 = 864 bitus.
3. uzdevums:
Abos tekstos ir vienāds rakstzīmju skaits. Pirmais teksts ir rakstīts krievu valodā, bet otrais - Naguri cilts valodā, kuras alfabēts sastāv no 16 rakstzīmēm. Kurā tekstā ir vairāk informācijas?
Risinājums:
1) I \u003d K * a (teksta informācijas apjoms ir vienāds ar rakstzīmju skaita un vienas rakstzīmes informācijas svara reizinājumu).
2) jo abos tekstos ir vienāds zīmju skaits (K), tad atšķirība ir atkarīga no vienas alfabēta rakstzīmes informācijas satura (a).
3) 2 a1
= 32, t.i. a 1
= 5 biti, 2 a2
= 16, t.i. a 2
= 4 biti.
4) es 1
= K * 5 biti, I 2
= K * 4 biti.
5) Tas nozīmē, ka krievu valodā rakstītais teksts satur 5/4 reizes vairāk informācijas.
4. uzdevums:
Ziņojuma apjoms, kas satur 2048 rakstzīmes, bija 1/512 MB. Nosakiet alfabēta spēku.
Risinājums:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 biti - ziņojuma informācijas apjoms tika pārveidots bitos.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 biti - ietilpst vienā alfabēta rakstzīmē.
3) 2*16*2048 = 65536 rakstzīmes - izmantotā alfabēta jauda.
5. uzdevums:
Canon LBP lāzerprinteris drukā ar vidējo ātrumu 6,3 Kbps. Cik ilgā laikā tiks izdrukāts 8 lappušu dokuments, ja ir zināms, ka uz vienas lapas ir vidēji 45 rindiņas, 70 rakstzīmes katrā rindā (1 rakstzīme - 1 baits)?
Risinājums:
1) Atrodiet 1 lappusē esošās informācijas apjomu: 45 * 70 * 8 biti = 25200 biti
2) Atrodiet informācijas apjomu 8 lapās: 25200 * 8 = 201600 biti
3) Mēs izveidojam vienotas mērvienības. Lai to izdarītu, mēs pārvēršam Mbps bitos: 6,3 * 1024 = 6451,2 bps.
4) Atrodiet drukas laiku: 201600: 6451,2 = 31 sekunde.
Bibliogrāfija
1. Agejevs V.M. Informācijas un kodēšanas teorija: mērījumu informācijas diskretizācija un kodēšana. - M.: MAI, 1977. gads.
2. Kuzmins I.V., Kedrus V.A. Informācijas teorijas un kodēšanas pamati. - Kijeva, Viščas skola, 1986. gads.
3. Vienkāršākās teksta šifrēšanas metodes / D.M. Zlatopoļskis. - M.: Chistye Prudy, 2007 - 32 lpp.
4. Ugrinovičs N.D. Informātika un informācijas tehnoloģijas. Mācību grāmata 10.-11.klasei / N.D.Ugrinovičs. – M.: BINOM. Zināšanu laboratorija, 2003. - 512 lpp.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n