Metin bilgilerinin kodlanması. Eksiksiz Dersler - Bilgi Hipermarketi
Ders
- kodlama metin bilgisi.
Hedef
- Bilgisayar belleğindeki metinleri kodlama yöntemlerini tanıtmak.
dersler sırasında
Bilgisayar alanında metin, herhangi bir karakter dizisidir. Bugün makineler, 256'ya kadar karakter içeren bir dizi karakter kullanıyor.
Ayrıca, her birinin kendi sekiz bitlik ikili kodu vardır. Böylece, bir bilgisayarın belleğinde herhangi bir metin karakteri 8 bit veya 1 bayt yer kaplar.
Bunu göz önünde bulundurarak, herhangi bir metin belgesini saklamak için gereken bellek miktarını ölçmek mümkün görünüyor.
1 bitin (ikili basamak) iki anlamı vardır, her bitin koda eklenmesi elde edilen kombinasyon sayısını iki katına çıkarır: 2 bit - dört seçenek, 3 bit - sekiz, 4 bit - on altı, vb.
Örneğin, daktilo ile yazılmış bir A4 sayfası yaklaşık 55 satır içerir. Her biri yaklaşık 60 karakter içerir.
Bu bilgilerle, belirli bir sayfadaki metinsel bilgi miktarını sayabiliriz.
Her karakter 1 bayt bilgidir ve toplam karakter sayısı 3300'dür (60 çarpı 55). Sayfadaki bilgi miktarının 3 KB civarında olduğu ortaya çıkıyor.
İkili kodlar ve bunlara karşılık gelen karakterler, bir kodlama tablosuyla bağlantılıdır. PC'de kullanılan tüm tablolar Amerikan ASCII4 standardına dayanmaktadır. İlk 128 kodu tanımlar ( edebiyat, sayılar, işaretler). Geri kalan 128 tanesi özel karakterler ve ulusal alfabelerin (Rusça, Çince, Arapça) harfleri için kullanılır. Ve bunun için ortak standartlar olmadığı için Kiril alfabesi de dahil olmak üzere birçok kodlama ortaya çıktı.
Bu nedenle, bazen birinin metnini bir dizi "dalgalı çizgi" şeklinde görebilirsiniz.
Bu tür metinlerin okunabilmesi için çevirici programlar bulunmaktadır. Her karakterin ikili kodunu farklı bir kodlamanın koduyla değiştirirler. Ve genellikle, kullanıcının dönüştürmenin hangi kodlamadan yapıldığını belirtmesi gerekir.
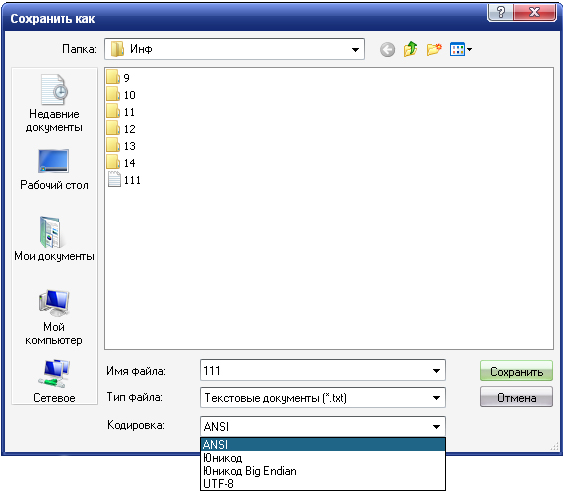
Ancak, kaynak metnin kodlamasını otomatik olarak belirleyebilen programlar zaten var.
Bu nedenle, makine alfabesinin tüm sembollerine karşılık gelen seri numaralarının atandığı bir tablo denir. kodlama tablosu
ASCII kod tablosu
Daha önce bahsedildiği gibi, ASCII tablosu (Bilgi Alışverişi için Amerikan Standart Kodu), PC'ler için uluslararası standart haline geldi.
Bilgisayar ağlarında kullanılan başka bir tablo - KOI-8 (Bilgi Değişim Kodu) da bulabilirsiniz.
ASCII kod tablosu aşağıdakilere ayrılmıştır: iki parça.
Uluslararası uygulamada, standart yalnızca tablonun ilk kısmı, yani 0 (00000000) ile 127 (01111111) arasındaki sayılara sahip karakterler. Bunlar Latin alfabesinin küçük ve büyük harfleri, sayılar, noktalama işaretleri, farklı tür parantezler, ticari ve diğer semboller.
0'dan 31'e kadar olan karakterlerin numaralandırılmasına genellikle kontrol karakterleri denir. Metnin ekranda görüntülenme veya yazdırılma sürecini, hoparlörlere ses sinyalini ve metnin işaretlenmesini kontrol ederler.
Karakter 32, metinde bir boşluk veya boş konumdur.
Kodlama tablosunda harflerin (büyük ve küçük) alfabetik sıraya göre düzenlendiğine ve sayıların artan değer sırasına göre sıralandığına dikkatinizi çekiyorum. Karakterlerin dizilişinde sözlükbilimsel düzenin bu şekilde gözetilmesine sıralı alfabe kodlama ilkesi denir.
İkinci yarı ASCII tabloları kod sayfası denir. Bunlar 10000000'den 11111111'e kadar farklı seçeneklere sahip kalan 128 koddur ve her (!) seçeneğin kendi numarası vardır.
Her şeyden önce, kod sayfası Latin alfabesinden farklı olan ulusal alfabeleri barındırmak için kullanılır. Rus ulusal kodlamalarında, Rus alfabesinin karakterleri tablonun bu bölümüne yerleştirilir. Yani her dil için ayrı ayrı.
Unicode kodlama
Bu 16 bitlik bir kodlamadır - her karakter için 2 bayt belleğe sahiptir.
Buna göre, kullanılan bellek miktarı 2 kat artar. Ancak böyle bir kod tablosu 65536 karaktere kadar tutabilir.
Unicode'un tam sürümü, dünyadaki mevcut ve yok olmuş tüm alfabeleri ve birçok matematiksel, müzikal, kimyasal sembolü içerir.
Metinle çalışmak için programlar
Metinle çalışmayı basitleştirme arzusu, bunun için özel olarak tasarlanmış birçok programın - metin editörlerinin - oluşturulmasına yol açmıştır.
Bir kelime işlemci, yalnızca bir daktilonun yerine geçmez, aynı zamanda metinlerle çalışmak için evrensel bir araçtır.
Metin belgelerini değiştirmek için çok geniş olanaklar sağlarlar.
Bu tür programlarda sadece bireysel karakterlerle değil, aynı zamanda karakterlerle de çalışabilirsiniz. kelimeler, çizgiler, paragraflar, grafikler. Yazma, kopyalama, kaydetme, parçaları taşıma ve silme, yazı tipini, rengini ve boyutunu değiştirme, diske metin gönderme ve yazdırma gibi işlemlere ek olarak.
İşlenen metin, sanki ekranda kayan belirli bir formattaki kağıt yaprakları şeklinde sunulur.
Metinlerin dosyada saklanmasının avantajları:
1) kağıt tasarrufu
2) kompakt yerleşim
3) anında diğer medyaya kopyalama yeteneği
4) ağ hatları veya İnternet üzerinden metin iletme yeteneği
Sorular
1. Kodlama tablosu nedir?
2. Hangi kodlama uluslararası standart haline geldi?
3. Metin düzenleyiciye ne denir?
Kullanılan kaynakların listesi
1. Konuyla ilgili ders: “Metin kodlama süreci”, Pavlov M. S., Cherkasy
2. Eremin E.A. Klavye tamponu nasıl çalışır / Bilişim #45, 2004
3. Şemakin İ.G.
Pİlk 128 karakter standardize edilmiştir. Dünyadaki tüm kodlamalarda kesinlikle aynıdırlar. Sembollerden bahsedersek, o zaman bu tüm İngiliz alfabesi, sayılar ve temel karakterlerdir. Kalan 128 pozisyon, ulusal alfabelerin ve ek karakterlerin "merhametine" verildi. Ülkelerin büyük çoğunluğunda bu böyledir. Bununla birlikte, Rusya'da bir hatta iki ulusal kodlama yoktur. Tam olarak beş tane var. Bu nedenle, metin bir kodlamada Rusça yazılırsa, diğerinde kesinlikle rastgele bir farklı karakter kümesi gibi görünecektir.
M Bu Wiki makalesinin pek çok okuyucusu muhtemelen şunu soracaktır: "Ama neden Rusya'da bu kadar çok farklı kodlama var?". Bu soruyu cevaplamak için tarihe kısa bir giriş yapmanız gerekecek. Her şey geçen yüzyılın 70'lerinde başladı. O zaman UNIX işletim sistemi bilgisayarlarımızda göründü (kişisel olanlar değil - o zamanlar yoktu). Doğal olarak Rus diline uyarlandı. O zaman KOI-8 adı verilen ilk kodlama ortaya çıktı. O zamandan beri tüm UNIX benzeri uygulamalar için "fiili" standart haline geldi. işletim sistemleri- örneğin Linux için.
H biraz sonra kişisel bilgisayarların muzaffer yürüyüşü başladı. Ve bunlarla birlikte MS-DOS işletim sistemi de oldukça yaygınlaştı. Geliştiricisi Microsoft, Ruslaştırma sırasında KOI-8'i kullanmadı, ancak DOS (kod sayfası 866) adı verilen kendi kodlamasını buldu. Bu tabloda, ek karakterler arasında, çeşitli metin düzenleyicilerde tabloların çizilmesini büyük ölçüde kolaylaştıran çerçeve öğeleri ortaya çıktı. Bu aynı zamanda DOS kodlamasının yayılmasına da katkıda bulundu. Bu arada, aşağı yukarı aynı zamanlarda veya biraz sonra Rusya pazarı Macintosh bilgisayarlar çıktı. Doğal olarak, üzerlerinde yüklü işletim sisteminin Ruslaştırılması sırasında başka bir sembol tablosu oluşturuldu - MAC. Doğru, Mac'lerin küçük dağılımı nedeniyle neredeyse hiç kullanılmadığına dikkat edilmelidir.
İÇİNDE 1990 yılında Microsoft yeni bir işletim sistemi çıkardı. Windows sürümü 3.0. İçine ulusal diller için destek yerleştirildi. Ancak ilginç olan şu - bir nedenden dolayı Microsoft uzmanları zaten var olan Rus DOS kodlamasını kullanmadılar, ancak yine yeni bir tane icat ettiler - Win (kod sayfası 1251). Büyük olasılıkla, bu, tabloya çerçeveler ve benzer karakterler yerine başka ek karakterlerin eklenmesi nedeniyle yapıldı. Ancak Win kodlamasının ortaya çıkma nedenlerini büyük olasılıkla kesin olarak bilmeyeceğiz. Daha sonra, standardizasyon konularıyla ilgilenen Uluslararası Standardizasyon Örgütü Uluslararası Örgütü, Rusya'da ve diğer bazı ülkelerde birkaç ulusal kodlamanın varlığı sorununa dikkat çekti. Ve yine, en yaygın kodlamayı temel almak yerine (o zamanlar Win tablosuydu), ISO temsilcileri kendi kodlamalarını icat ettiler (ISO 8859-5). Ancak pratik uygulama o almadı. Ve ISO kodlaması tüm tarayıcılarda desteklense de, muhtemelen onu kullanan tek bir site yoktur.
İLE Ek olarak, evrensel Unicode kodlamasını "zorlama" girişimleri oldukça uzun bir süredir gözlemlenmektedir. Yaratıcıları, her karakter için bir değil iki bayt kullanılmasını önerdi. Bu, olası değerlerin sayısını 65535'e kadar artırmanıza ve mevcut alfabelerin tüm karakterlerini tabloya sığdırmanıza olanak tanır. Doğru, tüm bu girişimler kesinlikle sonuçsuz kalıyor.
Bu nedenle, kodlama farklılıklarının birkaç ortak özelliğini vurguluyoruz:
1) Toplam 256 karakter vardır.
2) İlk 128 karakter standardize edilmiştir, dünyanın her yerinde aynıdır ve İngiliz alfabesi, sayılar ve işaretlerden oluşur.
3) Kalan 128 karakter, ulusal alfabelerin ve ek karakterlerin "insafına" verilmiştir.
4) Rusya'da 5 farklı kodlama var!
5) Bir kodlamada Rusça, başka bir kodlamada yazılan metin, çeşitli rastgele karakterler gibi görünecektir, bu nedenle, her kodlama bireyseldir ve başka bir kodlamayla yakın "işbirliğini" desteklemez.
6) Her kodlama kendi kod tablosu tarafından belirtilir. Aynısı ikili kod v çeşitli kodlamalar farklı semboller atanır.
7) Çoğu kodlamada ortak olan bir özellik 1 karakter için tamı tamına 1 byte kullanılmaktadır. Yaratıcılarının her karakter için bir değil iki bayt kullanmayı önerdiği bir Unicode kodlaması var. Bu, olası değerlerin sayısını 65535'e kadar artırmanıza ve mevcut alfabelerin tüm karakterlerini tabloya sığdırmanıza olanak tanır. Doğru, tüm bu girişimler kesinlikle sonuçsuz kalıyor.
Farklı kodlamalarda oluşturulan metin dosyaları arasındaki fark
İLE Bir metin dosyası kodlandığında, her metin karakterine sayısal bir değer atayan belirli bir kurallar dizisi olan bir kodlama standardına göre kaydedilir. Farklı dillerde kullanılan karakter kümelerini temsil eden birçok farklı kodlama standardı vardır ve bu standartlardan bazıları yalnızca bir dildeki karakterleri destekler. Bu nedenle, Çince metin için Basitleştirilmiş yazı durumunda GB2312-80 kodlama standardı ve Geleneksel yazı durumunda Big5 kodlama standardı kullanılabilir.
P Microsoft Word, Unicode kodlama standardını kullandığından (Unicode. Unicode konsorsiyumu tarafından geliştirilen bir karakter kodlama standardı. Unicode, her karakteri temsil etmek için birden fazla bayt kullanarak, neredeyse tüm dünya dillerini tek bir karakter setinde temsil etmenizi sağlar.) , çeşitli diller için kodlama standartlarını kullanarak Microsoft Word dosyalarını açabilir ve kaydedebilirsiniz. Örneğin, bir arayüz kullanan bir işletim sistemiyle çalışırken ingilizce dili, Yunanca veya Japonca kodlama standardı kullanılarak oluşturulmuş bir metin dosyasını Microsoft Word'de açabilirsiniz.
İçerik
I. Bilgi kodlama tarihi………………………………..3
II. Kodlama bilgileri…………………………………………4
III. Metinsel bilgilerin kodlanması………………………….4
IV. Kodlama tablosu türleri…………………………………………...6
V. Metin bilgisi miktarının hesaplanması……………………14
Kullanılan literatür listesi………………………………..16
BEN
.
Bilgi kodlama geçmişi
İnsanoğlu, ilk gizli bilginin ortaya çıktığı andan itibaren metin şifreleme (kodlama) kullanmaktadır. İşte insan düşüncesinin gelişiminin çeşitli aşamalarında icat edilen birkaç metin kodlama tekniği:
Kriptografi, kriptografidir, metni tecrübesiz kişiler için anlaşılmaz hale getirmek için yazı değiştirme sistemidir;
Her harfin veya karakterin kendi kısa temel parsel kombinasyonuyla temsil edildiği mors kodu veya tekdüze olmayan telgraf kodu elektrik akımı(noktalar) ve üçlü süreli temel parseller (çizgiler);
İşaret dili, işitme engellilerin kullandığı bir işaret dilidir.
Bilinen en eski şifreleme yöntemlerinden biri, Roma imparatoru Julius Caesar'ın (MÖ 1. yüzyıl) adını taşır. Bu yöntem, alfabeyi orijinal harften sabit sayıda karakter kaydırarak şifreli metnin her harfinin bir başkasıyla değiştirilmesine dayanır ve alfabe bir daire içinde okunur, yani i harfinden sonra, a dikkate alınır. Yani iki karakter sağa kaydırıldığında "byte" kelimesi "gvlf" kelimesi ile kodlanır. Belirli bir kelimenin şifresini çözmenin ters işlemi, şifrelenmiş her harfi solundaki ikinci harfle değiştirmektir.
II.
bilgi kodlama
Bir kod, bazı önceden tanımlanmış kavramları kaydetmek (veya iletmek) için bir kurallar (veya sinyaller) kümesidir.
Bilgiyi kodlama, bilginin belirli bir temsilini oluşturma sürecidir. Daha dar bir anlamda, "kodlama" terimi genellikle bir bilgi sunum biçiminden diğerine geçiş, depolama, iletim veya işleme için daha uygun olarak anlaşılır.
Genellikle, kodlandığında (bazen - şifrelenmiş derler) her görüntü ayrı bir karakterle temsil edilir.
Bir işaret, sonlu bir farklı öğeler kümesinin bir öğesidir.
Daha dar bir anlamda, "kodlama" terimi genellikle bir bilgi sunum biçiminden diğerine geçiş, depolama, iletim veya işleme için daha uygun olarak anlaşılır.
Bilgisayar metin bilgilerini işleyebilir. Bilgisayara girildiğinde her harf belirli bir sayı ile kodlanmakta ve insan algısı için harici cihazlara (ekran veya baskı) çıktı alındığında bu sayılar kullanılarak harflerin görüntüleri oluşturulmaktadır. Bir dizi harf ve rakam arasındaki yazışmaya karakter kodlaması denir.
Kural olarak, bilgisayardaki tüm sayılar sıfırlar ve birler kullanılarak temsil edilir (insanlar için alışılmış olduğu gibi on basamak değil). Başka bir deyişle, bilgisayarlar genellikle ikili sistemde çalışır, çünkü onları işleyen cihazlar çok daha basittir. Sayıların bir bilgisayara girilmesi ve insan okuması için çıktısının alınması olağan ondalık biçimde yapılabilir ve gerekli tüm dönüştürmeler bilgisayarda çalışan programlar tarafından gerçekleştirilir.
III.
Metin bilgilerinin kodlanması
Aynı bilgiler birkaç biçimde sunulabilir (kodlanabilir). Bilgisayarların ortaya çıkmasıyla birlikte, hem bireyin hem de bir bütün olarak insanlığın uğraştığı her türlü bilgiyi kodlamak gerekli hale geldi. Ancak insanlık, bilgi kodlama sorununu bilgisayarların ortaya çıkmasından çok önce çözmeye başladı. İnsanlığın görkemli başarıları - yazma ve aritmetik - bir konuşma kodlama sisteminden başka bir şey değildir ve sayısal bilgi. bilgiler asla görünmez saf formu, her zaman bir şekilde temsil edilir, bir şekilde kodlanır.
İkili kodlama, bilgiyi temsil etmenin en yaygın yollarından biridir. Sayısal kontrollü bilgisayarlarda, robotlarda ve takım tezgahlarında, kural olarak, cihazın ilgilendiği tüm bilgiler ikili alfabenin sözcükleri biçiminde kodlanır.
1960'ların sonlarından bu yana, bilgisayarlar kelime işlem için giderek daha fazla kullanılmaya başlandı ve şimdi dünyadaki kişisel bilgisayarların (ve çoğu saat) metin bilgilerini işlemekle meşgul. Bir bilgisayardaki tüm bu tür bilgiler ikili kodda temsil edilir, yani ikinin üssü olan bir alfabe kullanılır (yalnızca iki karakter 0 ve 1). Bunun nedeni, bilgiyi bir dizi elektriksel darbe şeklinde temsil etmenin uygun olmasıdır: dürtü yoktur (0), bir dürtü vardır (1).
Bu tür kodlamaya genellikle ikili denir ve sıfırların ve birlerin mantıksal dizilerine makine dili denir.
Bilgisayarın bakış açısından, metin tek tek karakterlerden oluşur. Karakterler yalnızca harfleri (büyük veya küçük harf, Latince veya Rusça) değil, sayıları, noktalama işaretlerini, "=", "(", "&" vb. gibi özel karakterleri ve hatta kelimeler arasındaki boşlukları (özellikle dikkat edin!) içerir. .
Metinler klavye kullanılarak bilgisayar belleğine girilir. Anahtarlar bize tanıdık gelen harfler, sayılar, noktalama işaretleri ve diğer sembollerle yazılmıştır. RAM'e ikili kod olarak girerler. Bu, her karakterin 8 bitlik bir ikili kodla temsil edildiği anlamına gelir.
Geleneksel olarak, bir karakteri kodlamak için 1 bayta eşit bilgi miktarı kullanılır, yani. I \u003d 1 bayt \u003d 8 bit. K olası olayların sayısını ve I bilgi miktarını ilişkilendiren bir formül kullanarak, kaç farklı karakterin kodlanabileceğini hesaplayabilirsiniz (karakterlerin olası olaylar olduğu varsayılarak): K \u003d 2 I
= 2 8
= 256, yani metin bilgisini temsil etmek için 256 karakter kapasiteli bir alfabe kullanılabilir.
Bu karakter sayısı, Rus ve Latin alfabelerinin büyük ve küçük harfleri, sayılar, işaretler, grafik semboller vb. dahil olmak üzere metin bilgilerini temsil etmek için yeterlidir.
Kodlama, her karaktere benzersiz bir karakter atanmasıdır. ondalık kod 0'dan 255'e veya 00000000'den 11111111'e karşılık gelen ikili kod. Böylece, bir kişi karakterleri stillerine göre ve bir bilgisayarı kodlarına göre ayırır.
Karakterlerin bayt bayt kodlamasının rahatlığı açıktır, çünkü bir bayt belleğin adreslenebilir en küçük kısmıdır ve bu nedenle işlemci, metin işlemeyi gerçekleştirirken her karaktere ayrı ayrı erişebilir. Öte yandan, 256 karakter, çok çeşitli karakter bilgilerini temsil etmek için oldukça yeterlidir.
Bir karakterin bilgisayar ekranında görüntülenmesi sürecinde, ters işlem gerçekleştirilir - kod çözme, yani karakter kodunu görüntüsüne dönüştürme. Belirli bir kodun bir sembole atanmasının, kod tablosunda sabitlenen bir anlaşma konusu olması önemlidir.
Şimdi soru, her karaktere hangi sekiz bitlik ikili kodun yazılacağı sorusu ortaya çıkıyor. Bunun şartlı bir mesele olduğu açıktır, kodlamanın birçok yolunu bulabilirsiniz.
Bilgisayar alfabesindeki tüm karakterler 0'dan 255'e kadar numaralandırılmıştır. Her sayı, 00000000'den 11111111'e kadar sekiz bitlik bir ikili koda karşılık gelir. Bu kod, ikili sayı sistemindeki karakterin sıra numarasıdır.
IV
. Kodlama tablosu türleri
Bilgisayar alfabesindeki tüm karakterlere seri numaraları atanan bir tabloya kodlama tablosu denir.
İçin farklı şekiller Bilgisayar çeşitli kodlama tabloları kullanır.
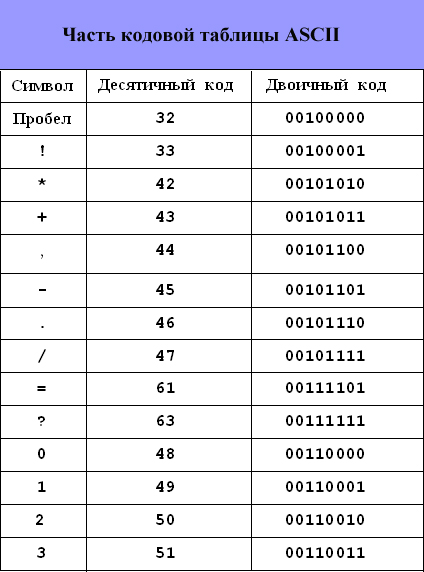
ASCII (Bilgi Değişimi İçin Amerikan Standart Kodu) kod tablosu, karakterlerin ilk yarısını 0'dan 127'ye kadar sayısal kodlarla kodlayan uluslararası bir standart olarak benimsenmiştir (0'dan 32'ye kadar olan kodlar karakterlere değil işlev tuşlarına atanır).
ASCII kod tablosu iki bölüme ayrılmıştır.
Tablonun sadece ilk yarısı uluslararası bir standarttır, yani; 0 (00000000) ile 127 (01111111) arasındaki sayılara sahip karakterler.
ASCII kodlama tablosunun yapısı
| Seri numarası | kod | Sembol |
| 0 - 31 | 00000000 - 00011111 | 0'dan 31'e kadar sayıları olan karakterlere kontrol karakterleri denir. İşlevleri, ekranda metin görüntüleme veya yazdırma, ses sinyali verme, metni işaretleme vb. İşlemlerini kontrol etmektir. |
| 32 - 127 | 0100000 - 01111111 | Tablonun standart kısmı (İngilizce). Buna Latin alfabesinin küçük ve büyük harfleri, ondalık basamaklar, noktalama işaretleri, her türlü parantez, ticari ve diğer semboller dahildir. Karakter 32 bir boşluktur, yani metinde boş konum. Geri kalan her şey belirli işaretlerle yansıtılır. |
| 128 - 255 | 10000000 - 11111111 | Tablonun alternatif kısmı (Rusça). ASCII kod tablosunun kod sayfası olarak adlandırılan ikinci yarısı (10000000 ile başlayan ve 11111111 ile biten 128 kod) farklı seçeneklere sahip olabilir, her seçeneğin kendi numarası vardır. Kod sayfası, öncelikle Latince dışındaki ulusal yazıları barındırmak için kullanılır. Rus ulusal kodlamalarında, Rus alfabesinin karakterleri tablonun bu bölümüne yerleştirilir. |
ASCII kod tablosunun ilk yarısı
Kodlama tablosunda harflerin (büyük ve küçük) alfabetik sıraya, sayıların ise artan düzende sıralanmış olmasına dikkat çekilmektedir. Karakterlerin düzenlenmesinde sözlükbilimsel düzenin bu şekilde gözetilmesine alfabenin sıralı kodlama ilkesi denir.
Rus alfabesinin harfleri için sıralı kodlama ilkesi de gözetilir.
ASCII kod tablosunun ikinci yarısı
Ne yazık ki, şu anda beş farklı Kiril kodlaması var (KOI8-R, Windows. MS-DOS, Macintosh ve ISO). Bu nedenle, Rusça metnin bir bilgisayardan diğerine, bir yazılım sisteminden diğerine aktarılmasıyla ilgili sorunlar sıklıkla ortaya çıkar.
Kronolojik olarak, bilgisayarlarda Rus harflerini kodlamak için ilk standartlardan biri KOI8 ("Bilgi Değişim Kodu, 8 bit") idi. Bu kodlama 70'lerde EC serisi bilgisayarların bilgisayarlarında kullanıldı ve 80'lerin ortalarından itibaren UNIX işletim sisteminin ilk Ruslaştırılmış sürümlerinde kullanılmaya başlandı.
90'lı yılların başından itibaren, MS DOS işletim sisteminin hakimiyet zamanı, kodlama CP866 olarak kalır ("CP", "Kod Sayfası", "kod sayfası" anlamına gelir).
Mac OS işletim sistemini çalıştıran Apple bilgisayarlar kendi Mac kodlamalarını kullanır.
Ayrıca Uluslararası Standardizasyon Örgütü (Uluslararası Standartlar Örgütü, ISO), ISO 8859-5 adlı başka bir kodlamayı Rus dili için bir standart olarak onayladı.
Şu anda kullanılan en yaygın kodlama, CP1251 olarak kısaltılan Microsoft Windows'tur. Microsoft tarafından tanıtılan; hesaba katarak yaygın bu şirketin işletim sistemleri (OS) ve diğer yazılım ürünleri Rusya Federasyonu yaygınlaştı.
90'ların sonlarından bu yana, karakter kodlama standardizasyonu sorunu, Unicode adlı yeni bir uluslararası standardın getirilmesiyle çözüldü.
Bu 16 bitlik bir kodlamadır, yani karakter başına 2 bayt belleğe sahiptir. Tabii bu durumda kullanılan hafıza miktarı 2 kat artıyor. Ancak böyle bir kod tablosu, 65536 karaktere kadar dahil edilmesine izin verir. Unicode standardının eksiksiz belirtimi, dünyadaki tüm mevcut, tükenmiş ve yapay olarak oluşturulmuş alfabelerin yanı sıra birçok matematiksel, müzikal, kimyasal ve diğer sembolleri içerir.
Bilgisayar belleğindeki sözcüklerin dahili gösterimi
bir ASCII tablosu kullanarak
Bazen, başka bir bilgisayardan alınan Rus alfabesinin harflerinden oluşan metin okunamaz - monitör ekranında bir tür "abracadabra" görünür. Bunun nedeni, bilgisayarların Rus dilinin farklı karakter kodlamalarını kullanmasıdır.
Böylece her kodlama kendi kod tablosu ile belirtilir. Tablodan da görülebileceği gibi aynı ikili koda farklı kodlamalarda farklı karakterler atanmaktadır.
Örneğin CP1251 kodlamasında sayısal kodların 221, 194, 204 dizisi "bilgisayar" kelimesini oluştururken, diğer kodlamalarda anlamsız bir karakter kümesi olacaktır.
Neyse ki, çoğu durumda, bu, uygulamalara yerleşik özel dönüştürücü programları tarafından yapıldığından, kullanıcının metin belgelerinin kodunu dönüştürme konusunda endişelenmesine gerek yoktur.
v
. Metin bilgisi miktarının hesaplanması
Görev 1:
KOI8-R ve CP1251 kodlama tablolarını kullanarak "Roma" kelimesini kodlayın.
Çözüm:
Görev 2:
Her karakterin bir bayt tarafından kodlandığını varsayarak, aşağıdaki cümlenin bilgi hacmini tahmin edin:
“En dürüst kuralların amcam,
Ciddi anlamda hastalandığımda,
Kendini saygı duymaya zorladı
Ve daha iyisini düşünemedim."
Çözüm:
Bu cümlede noktalama işaretleri, tırnak işaretleri ve boşluklar dahil 108 karakter vardır. Bu sayıyı 8 bit ile çarpıyoruz. 108*8=864 bit elde ederiz.
Görev 3:
İki metin aynı sayıda karakter içerir. İlk metin Rusça, ikincisi ise alfabesi 16 karakterden oluşan Naguri kabilesinin dilinde yazılmıştır. Kimin metni daha fazla bilgi taşır?
Çözüm:
1) I \u003d K * a (metnin bilgi hacmi, karakter sayısı ile bir karakterin bilgi ağırlığının çarpımına eşittir).
2) Çünkü her iki metin de aynı sayıda karaktere sahiptir (K), bu durumda fark, alfabenin bir karakterinin (a) bilgi içeriğine bağlıdır.
3) 2 a1
= 32, yani bir 1
= 5 bit, 2 a2
= 16, yani bir 2
= 4 bit.
4) ben 1
= K * 5 bit, ben 2
= K * 4 bit.
5) Rusça yazılan metnin 5/4 kat daha fazla bilgi taşıdığı anlamına gelir.
Görev 4:
2048 karakter içeren mesajın hacmi MB'nin 1/512'si kadardı. Alfabenin gücünü belirleyin.
Çözüm:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bit - mesajın bilgi hacmi bit'e dönüştürüldü.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 bit - alfabenin bir karakterine düşer.
3) 2*16*2048 = 65536 karakter - kullanılan alfabenin gücü.
Görev 5:
Canon LBP lazer yazıcı ortalama 6,3 Kbps hızında yazdırır. Bir sayfada ortalama 45 satır, her satırda 70 karakter (1 karakter - 1 byte) olduğu biliniyorsa 8 sayfalık bir belgeyi yazdırmak ne kadar sürer?
Çözüm:
1) 1 sayfada yer alan bilgi miktarını bulun: 45 * 70 * 8 bit = 25200 bit
2) 8 sayfadaki bilgi miktarını bulun: 25200 * 8 = 201600 bit
3) Tek tip ölçü birimlerine getiriyoruz. Bunu yapmak için Mbps'yi bitlere çeviriyoruz: 6.3 * 1024 = 6451.2 bps.
4) Baskı süresini bulun: 201600: 6451.2 = 31 saniye.
Kaynakça
1. Ageev V.M. Bilgi teorisi ve kodlama: ölçüm bilgisinin ayrıklaştırılması ve kodlanması. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Bilgi teorisi ve kodlamanın temelleri. - Kiev, Vishcha okulu, 1986.
3. En basit metin şifreleme yöntemleri / D.M. Zlatopolsky. - M.: Chistye Prudy, 2007 - 32 s.
4. Ugrinovich N.D. Bilişim ve bilgi teknolojileri. 10-11. Sınıflar için ders kitabı / N.D. Ugrinovich. – M.: BİNOM. Bilgi Laboratuvarı, 2003. - 512 s.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n







