İki olası durumu ne kadar bilgi kodlar. Kodlama ve kod çözme nedir? Örnekler. Sayısal, metinsel ve grafik bilgileri kodlama ve çözme yöntemleri
Bilgisayar biliminde, çok sayıda bilgi işlemi kullanılarak gerçekleşir. veri kodlama. Bu nedenle, bu süreci anlamak, bu bilimin temellerini anlamak için çok önemlidir. Bilgilerin kodlanması altında, farklı doğal dillerde (Rusça, ingilizce dili vb.) sayısal bir atamaya dönüştürülür.

Bu, metni kodlarken, her karaktere sıfırlar ve birler şeklinde belirli bir değer atandığı anlamına gelir - .
Bilgiyi neden kodlamalı?
Öncelikle soruyu cevaplamanız gerekiyor neden bilgileri kodla? Gerçek şu ki, bir bilgisayar yalnızca bir tür veri sunumunu işleyebilir ve depolayabilir - dijital. Bu nedenle, içerdiği herhangi bir bilgi şu dile çevrilmelidir: dijital görünüm.
Metin kodlama standartları
Tüm bilgisayarların belirli bir metni açık bir şekilde anlaması için, genel kabul görmüş metinleri kullanmak gerekir. metin kodlama standartları. Diğer durumlarda, ek kayıt veya veri uyumsuzluğu gerekli olacaktır.
ASCII
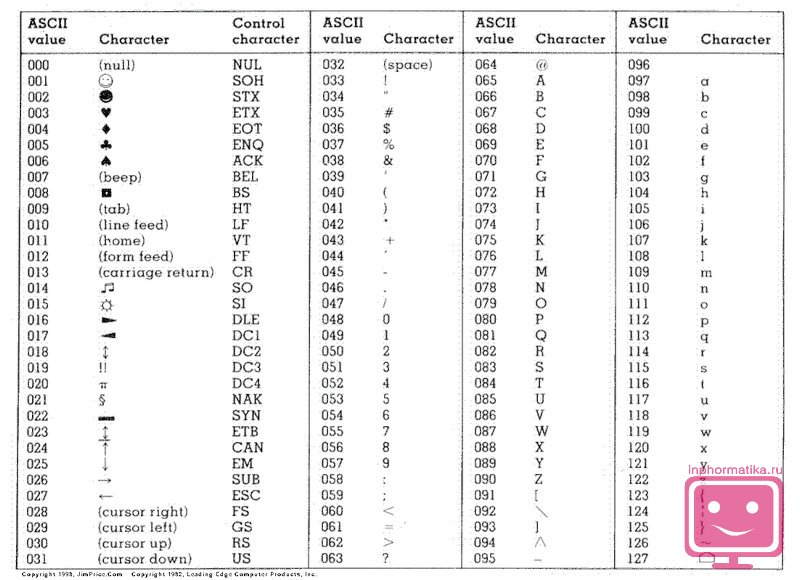
İlk bilgisayar karakter kodlama standardı ASCII idi (tam adı - Bilgi Alışverişi için Amerikan Standart Kodu). İçindeki herhangi bir karakteri kodlamak için yalnızca 7 bit kullanıldı. Hatırlayacağınız üzere 7 bit kullanılarak sadece 27 karakter veya 128 karakter kodlanabilmektedir. Bu, Latin alfabesinin büyük ve küçük harflerini, Arap rakamlarını, noktalama işaretlerini ve ayrıca belirli bir özel karakter kümesini, örneğin dolar işareti - "$" kodlamak için yeterlidir. Ancak, diğer halkların alfabelerinin sembollerini (Rus alfabesinin sembolleri dahil) kodlamak için, kodun 8 bit (28=256 sembol) ile tamamlanması gerekiyordu. Aynı zamanda her dil için ayrı bir kodlama kullanılmıştır.
UNICODE
Uyumluluk açısından durumu kurtarmak gerekiyordu. kodlama tabloları. Bu nedenle, zaman içinde yeni güncellenmiş standartlar geliştirilmiştir. Şu anda, en popüler kodlama denir UNICODE. İçinde her karakter 2 bayt kullanılarak kodlanmıştır, bu da 216=62536 farklı koda karşılık gelir.
Grafik kodlama standartları
Bir görüntüyü kodlamak, karakterleri kodlamaktan çok daha fazla bayt alır. Bilgisayar belleğinde saklanan oluşturulan ve işlenen görüntülerin çoğu iki ana gruba ayrılır:
- raster grafik görüntüleri;
- vektör grafik görüntüleri.
Raster grafikler
Raster grafiklerde, bir görüntü bir dizi renkli nokta ile temsil edilir. Bu tür noktalara piksel denir. Görüntü büyütüldüğünde bu tür noktalar karelere dönüşür.
Siyah beyaz bir görüntüyü kodlamak için her piksel bir bit ile kodlanır. Örneğin, siyah 0 ve beyaz 1'dir)
Geçmiş imajımız şu şekilde kodlanabilir:
Renksiz görüntüleri kodlarken, çoğunlukla beyazdan siyaha değişen 256 gri tondan oluşan bir palet kullanılır. Bu nedenle, böyle bir derecelendirmeyi kodlamak için bir bayt (28=256) yeterlidir.
Renkli görüntülerin kodlanmasında çeşitli renk şemaları kullanılır.
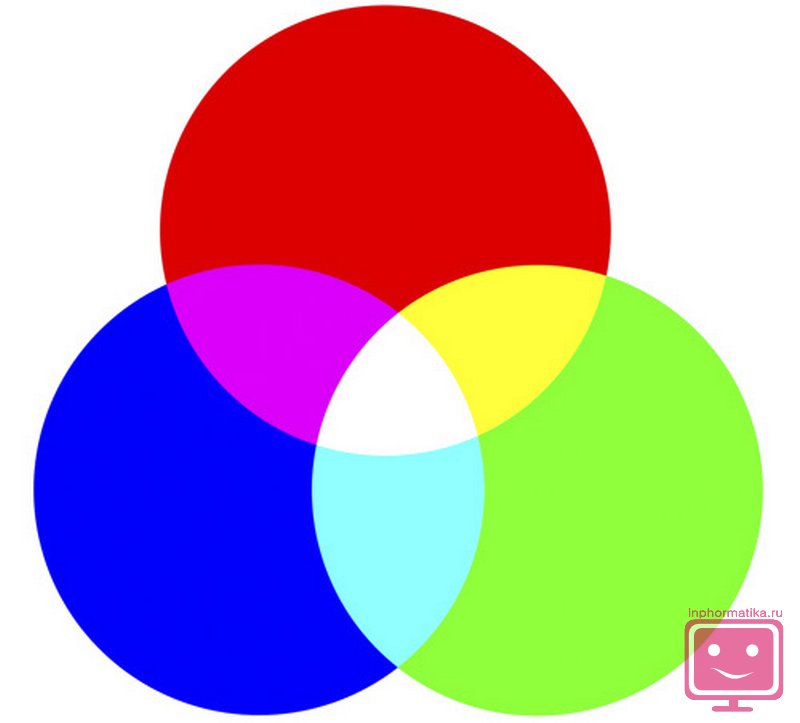
Uygulamada, daha sık RGB renk modeli sırasıyla üç ana rengin kullanıldığı yer: kırmızı, yeşil ve mavi. Kalan renk tonları, bu ana renklerin karıştırılmasıyla elde edilir.
Bu nedenle, bir modeli kodlamak için üç renk 256 tonda, 16,5 milyondan fazla farklı renk tonu elde edilmektedir. Yani kodlama için 3⋅8=24 bit kullanılmaktadır ki bu da 3 bayta karşılık gelmektedir.
Doğal olarak kullanabilirsiniz minimum miktar bit, ancak daha sonra, görüntü kalitesinin önemli ölçüde düşeceği bağlantılı olarak daha az sayıda renk tonu oluşturulabilir.
Bir görüntünün boyutunu belirlemek için, genişlikteki piksel sayısını piksel sayısının uzunluğuyla çarpmanız ve tekrar pikselin bayt cinsinden boyutuyla çarpmanız gerekir.
- A- geniş piksel sayısı;
- B- uzunluk olarak piksel sayısı;
- BEN– bayt cinsinden bir pikselin boyutu.
Örneğin, 800⋅600 piksellik renkli bir görüntü 60.000 bayta eşittir.
Vektör grafikleri
Vektör grafik nesneleri tamamen farklı bir şekilde kodlanmıştır. Burada görüntü, kendi eğrilik katsayılarına sahip olabilen çizgilerden oluşur.

Ses kodlama standartları
Bir kişinin duyduğu sesler hava titreşimleridir. Ses titreşimleri, dalga yayılma sürecidir.
Sesin iki temel özelliği vardır:
- salınım genliği - sesin seviyesini belirler;
- salınım frekansı - sesin tonunu belirler.
Ses, mikrofon kullanılarak elektrik sinyaline dönüştürülebilir. Ses, önceden belirlenmiş belirli bir zaman aralığında kodlanır. Bu durumda, elektrik sinyalinin boyutu ölçülür ve bir ikili değer atanır. Bu ölçümler ne kadar sık yapılırsa ses kalitesi o kadar yüksek olur.

700 MB CD, yaklaşık 80 dakikalık CD kalitesinde ses içerir.
Video kodlama standartları
Bildiğiniz gibi video sekansı hızla değişen fragmanlardan oluşuyor. Çerçeveler saniyede 24-60 kare aralığında bir hızda değişir.
Bayt cinsinden çekim boyutu, çerçeve boyutu (yükseklik ve genişlikte ekran başına piksel sayısı), kullanılan renk sayısı ve saniyedeki çerçeve sayısına göre belirlenir. Ancak bununla birlikte bir ses parçası da olabilir.
Sayı sistemleriyle tanıştık - sayıları kodlamanın yolları. Sayılar, öğelerin sayısı hakkında bilgi verir. Bu bilgi kodlanmalı, bazı sayı sistemlerinde sunulmalıdır. Bilinen yöntemlerden hangisinin seçileceği çözülmekte olan soruna bağlıdır.
Yakın zamana kadar bilgisayarlar çoğunlukla sayısal ve metinsel bilgileri işliyordu. Ancak dış dünya hakkındaki bilgilerin çoğu, bir kişi görüntü ve ses şeklinde alır. Bu durumda, görüntü daha önemlidir. Atasözünü hatırlayın: "Yüz kez duymaktansa bir kez görmek daha iyidir." Bu nedenle günümüzde bilgisayarlar görüntü ve sesle giderek daha aktif bir şekilde çalışmaya başlıyor. Bu tür bilgileri kodlamanın yolları mutlaka tarafımızca değerlendirilecektir.
İkili kodlama sayısal ve metin bilgisi.
Herhangi bir bilgi bilgisayarda iki basamaklı diziler kullanılarak kodlanır - 0 ve 1. Bilgisayar, bilgileri elektrik sinyallerinin bir kombinasyonu biçiminde depolar ve işler: 0,4V-0,6V'luk bir voltaj, mantıksal bir sıfıra karşılık gelir ve bir voltaj 2,4V-2,7V mantıksal birime karşılık gelir. 0 ve 1 dizileri denir ikili kodlar
ve 0 ve 1 sayıları - bit
(ikili rakamlar). Bir bilgisayardaki bilgilerin bu şekilde kodlanmasına denir. ikili kodlama
. Bu nedenle, ikili kodlama, mümkün olan en küçük sayıda temel karakterle kodlamadır ve en basit yolla kodlamadır. Onu teorik açıdan dikkate değer kılan da budur.
Mühendisler, teknik olarak uygulanması kolay olduğu için ikili bilgi kodlamasına ilgi duyarlar. Elektronik devreler ikili kodları işlemek için iki durumdan yalnızca birinde olmalıdır: sinyal var / sinyal yok
veya yüksek voltaj/düşük voltaj
.
Bilgisayarlar işlerinde iki, dört, sekiz ve hatta on bayt olarak temsil edilen gerçek ve tam sayılarla çalışırlar. Sayarken bir sayının işaretini temsil etmek için ek bir sembol kullanılır. işaret biti
, genellikle sayısal basamaklardan önce yerleştirilir. Pozitif sayılar için işaret bitinin değeri 0'dır ve negatif sayılar için 1'dir. Negatif bir tam sayının (-N) dahili temsilini yazmak için yapmanız gerekenler:
1) 0'ı 1 ve 1'i 0 ile değiştirerek N sayısının ek bir kodunu alın;
2) çıkan sayıya 1 ekleyin.
Bir bayt bu sayıyı temsil etmek için yeterli olmadığından, 2 bayt veya 16 bit olarak temsil edilir, tümleyen kodu 1111101111000101'dir, dolayısıyla -1082=1111101111000110.
Bir bilgisayar yalnızca tek baytları işleyebilseydi, çok az işe yarardı. Gerçekte, bir PC iki, dört, sekiz ve hatta on bayt olarak yazılan sayılarla çalışır.
60'ların sonlarından bu yana, bilgisayarlar metinsel bilgileri işlemek için giderek daha fazla kullanılmaktadır. Metin bilgilerini temsil etmek için genellikle 256 farklı karakter kullanılır, örneğin Latin alfabesinin büyük ve küçük harfleri, sayılar, noktalama işaretleri vb. Çoğu modern bilgisayarda, her karakter sekiz sıfır ve birden oluşan bir diziye karşılık gelir. bayt
.
Bir bayt, sıfırların ve birlerin sekiz bitlik bir birleşimidir.
Bu elektronik bilgisayarlarda bilgi şifrelenirken 8 sıfır ve birden oluşan 256 farklı dizi kullanılır ki bu da 256 karakterin şifrelenmesini mümkün kılar. Örneğin, büyük Rusça "M" harfi 11101101 koduna sahiptir, "I" harfi 11101001 koduna sahiptir, "R" harfi 11110010 koduna sahiptir. Böylece, "MIR" kelimesi 24 bitlik bir dizi ile kodlanmıştır. veya 3 bayt: 111011011110100111110010.
Bir mesajdaki bit sayısına mesajın bilgi boyutu denir.
Bu ilginç!
Başlangıçta bilgisayarlarda sadece Latin alfabesi kullanılıyordu. 26 harflidir. Bu nedenle, her birini belirtmek için beş darbe (bit) yeterli olacaktır. Ancak metin noktalama işaretleri, ondalık basamaklar vb. içerir. Bu nedenle, ilk İngilizce bilgisayarlarda, bir bayt - bir makine hecesi - altı bit içeriyordu. Sonra yedi - yalnızca büyük harfleri küçük harflerden ayırmak için değil, aynı zamanda yazıcılar, sinyal lambaları ve diğer ekipmanlar için kontrol kodlarının sayısını artırmak için. 1964'te, baytın nihayet sekiz bite eşit olduğu güçlü IBM-360 ortaya çıktı. Son sekizinci bit, sözde karakterler için gerekliydi.
Belirli bir ikili kodun bir sembole atanması, kod tablosunda sabitlenen bir anlaşma konusudur. Ne yazık ki, Rusça harflerin beş farklı kodlaması vardır, bu nedenle bir kodlamada oluşturulan metinler diğerinde doğru şekilde yansıtılmayacaktır.
Kronolojik olarak, bilgisayarlarda Rus harflerini kodlamak için ilk standartlardan biri KOI8'di (“Bilgi Değişim Kodu, 8 bit”). En yaygın kodlama, СР1251 ("СР", "Kod Sayfası" veya "kod sayfası" anlamına gelir) olarak kısaltılan standart Microsoft Windows Kiril kodlamasıdır. Apple, Macintosh bilgisayarlar için kendi Rusça harf kodlamasını (Mac) geliştirmiştir. Uluslararası Standartlar Örgütü (ISO), ISO 8859-5 kodlamasını Rus dili için standart olarak onayladı. Son olarak, her karaktere bir değil iki bayt atayan yeni bir uluslararası Unicode standardı ortaya çıktı ve bu nedenle 256 karakteri değil, 65536'ya kadar kodlamak için kullanılabilir.
Tüm bu kodlamalar, 128 karakteri kodlayan ASCII (Amerikan Bilgi Değişimi için Standart Kod) kod tablosunun devamıdır.
ASCII karakter tablosu:
| kod | sembol | kod | sembol | kod | sembol | kod | sembol | kod | sembol | kod | sembol |
| 32 | Uzay | 48 | . | 64 | @ | 80 | P | 96 | " | 112 | P |
| 33 | ! | 49 | 0 | 65 | A | 81 | Q | 97 | A | 113 | Q |
| 34 | " | 50 | 1 | 66 | B | 82 | R | 98 | B | 114 | R |
| 35 | # | 51 | 2 | 67 | C | 83 | S | 99 | C | 115 | S |
| 36 | $ | 52 | 3 | 68 | D | 84 | T | 100 | D | 116 | T |
| 37 | % | 53 | 4 | 69 | E | 85 | sen | 101 | e | 117 | sen |
| 38 | & | 54 | 5 | 70 | F | 86 | v | 102 | F | 118 | v |
| 39 | " | 55 | 6 | 71 | G | 87 | W | 103 | G | 119 | w |
| 40 | ( | 56 | 7 | 72 | H | 88 | X | 104 | H | 120 | X |
| 41 | ) | 57 | 8 | 73 | BEN | 89 | Y | 105 | Ben | 121 | y |
| 42 | * | 58 | 9 | 74 | J | 90 | Z | 106 | J | 122 | z |
| 43 | + | 59 | : | 75 | K | 91 | [ | 107 | k | 123 | { |
| 44 | , | 60 | ; | 76 | L | 92 | \ | 108 | ben | 124 | | |
| 45 | - | 61 | < | 77 | M | 93 | ] | 109 | M | 125 | } |
| 46 | . | 62 | > | 78 | N | 94 | ^ | 110 | N | 126 | ~ |
| 47 | / | 63 | ? | 79 | Ö | 95 | _ | 111 | Ö | 127 | SİL |
Metnin ikili kodlaması şu şekilde gerçekleşir: bir tuşa basıldığında, belirli bir elektrik darbe dizisi bilgisayara iletilir ve her karakterin kendi elektrik darbe dizisi vardır (makine dilinde sıfırlar ve birler). Klavye ve ekran sürücü programı kod tablosundan sembolü belirleyerek ekrandaki görüntüsünü oluşturur. Böylece metinler ve sayılar bilgisayarın belleğinde ikili kod olarak saklanır ve programlı olarak ekranda görüntülere dönüştürülür.
İkili kodlama grafik bilgi.80'lerden beri, bir bilgisayarda grafik bilgileri işleme teknolojisi hızla gelişiyor. Bilgisayar grafikleri, bilimsel araştırma, bilgisayar simülatörleri, bilgisayar animasyonu, iş grafikleri, oyunlar vb. bilgisayar simülasyonlarında yaygın olarak kullanılmaktadır.
Görüntü ekranındaki grafik bilgiler, noktalardan (piksellerden) oluşan bir görüntü şeklinde sunulur. Bir gazete fotoğrafına yakından bakın, onun da aşağıdakilerden oluştuğunu göreceksiniz. küçük noktalar. Bunlar sadece siyah ve beyaz noktalarsa, her biri 1 bit ile kodlanabilir. Ancak fotoğrafta gölgeler varsa, iki bit noktanın 4 gölgesini kodlamanıza izin verir: 00 - Beyaz renk, 01 - açık gri, 10 - koyu gri, 11 - siyah. Üç bit, 8 tonu vb. kodlamanıza izin verir.
Bir renk tonunu kodlamak için gereken bit sayısına renk derinliği denir.
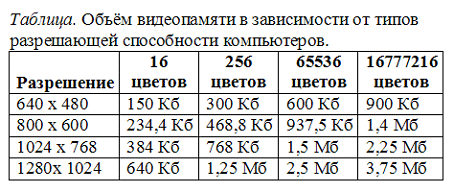
Modern bilgisayarlarda çözünürlük
(ekrandaki nokta sayısı) ve renk sayısı video bağdaştırıcısına bağlıdır ve programlı olarak değiştirilebilir.
Renkli görüntülerin farklı modları olabilir: 16 renk, 256 renk, 65536 renk ( yüksek renk), 16777216 renk ( doğru renk). Mod için bir puan yüksek renk 16 bit veya 2 bayt gereklidir.
En yaygın ekran çözünürlüğü 800 x 600 pikseldir, yani. 480000 puan. Yüksek renk modu için gereken video belleği miktarını hesaplayalım: 2 bayt *480000=960000 bayt.
Bilgi miktarını ölçmek için daha büyük birimler de kullanılır:
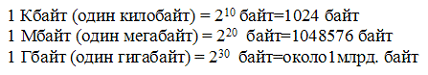
Bu nedenle, 960000 bayt yaklaşık olarak 937,5 KB'ye eşittir. Bir kişi günde sekiz saat ara vermeden konuşursa, o zaman 70 yıllık yaşamında yaklaşık 10 gigabayt bilgi söyleyecektir (bu 5 milyon sayfa - 500 metre yüksekliğinde bir kağıt yığını).
Bilgi aktarım hızı, 1 saniyede iletilen bit sayısıdır. Saniyede 1 bitlik iletim hızına 1 baud denir.
Bilgisayarın video belleği, işlemci tarafından okunduğu (saniyede en az 50 kez) ve ekranda görüntülendiği, görüntünün ikili kodu olan bir bitmap depolar.
Ses bilgilerinin ikili kodlaması.
90'lı yılların başından beri kişisel bilgisayarlar sağlam bilgilerle çalışabilmektedir. Ses kartı olan her bilgisayar dosya olarak kaydedebilir ( dosya, bir diskte depolanan belirli miktarda bilgidir ve bir adı vardır
) ve ses bilgilerini oynatın. Özel yazılım araçlarının (ses dosyası düzenleyicileri) yardımıyla, ses dosyalarını oluşturmak, düzenlemek ve dinlemek için harika fırsatlar açılır. Konuşma tanıma programları oluşturulur ve bilgisayarı sesle kontrol etmek mümkün hale gelir.
Analog sinyali ayrı bir fonograma dönüştüren ve bunun tersini, "sayısallaştırılmış" sesi hoparlör girişine beslenen analog (sürekli) bir sinyale dönüştüren ses kartıdır (kart).

Bir analog ses sinyalinin ikili kodlamasında, sürekli sinyal örneklenir, örn. bir dizi bireysel örneğiyle değiştirilir - okumalar. Kalite ikili kodlama iki parametreye bağlıdır: ayrık sinyal seviyelerinin sayısı ve saniyedeki örnek sayısı. Ses bağdaştırıcılarındaki örnek sayısı veya örnekleme hızı değişir: 11 kHz, 22 kHz, 44,1 kHz, vb. Düzey sayısı 65536 ise, bir ses sinyali için 16 bit (216) hesaplanır. 16 bitlik bir ses bağdaştırıcısı, sesi 8 bitlik bir bağdaştırıcıdan daha doğru şekilde kodlar ve yeniden üretir.
Bir ses seviyesini kodlamak için gereken bit sayısına ses derinliği denir.
Bir mono ses dosyasının hacmi (bayt olarak) aşağıdaki formülle belirlenir:

Stereofonik sesle, ses dosyasının hacmi iki katına çıkar, dörtlü sesle dört katına çıkar.
Programlar daha karmaşık hale geldikçe ve işlevleri arttıkça ve multimedya uygulamalarının görünümü arttıkça, programların ve verilerin işlevsel hacmi büyür. 80'lerin ortasında normal program ve veri hacmi onlarca ve yalnızca bazen yüzlerce kilobayt ise, o zaman 90'ların ortalarında onlarca megabayta ulaşmaya başladı. Buna bağlı olarak RAM miktarı artar.
Elektronik bilgisayarların veri işleme amacıyla çalıştırılması, yönetim ve planlama sistemlerinin iyileştirilmesi sürecinde önemli bir adım haline gelmiştir. Ancak bu bilgi toplama ve işleme yöntemi, normalden biraz farklıdır, bu nedenle, bilgisayarın anlayabileceği bir semboller sistemine dönüştürülmesini gerektirir.
Bilgi kodlama nedir?
Veri kodlama, bilgi toplama ve işleme sürecinde zorunlu bir adımdır.
Kural olarak, bir kod, iletilen verilere veya bunların niteliksel özelliklerinden bazılarına karşılık gelen bir karakter kombinasyonu anlamına gelir. Ve kodlama, şifrelenmiş bir kombinasyonu, mesajın orijinal anlamını tam olarak ileten bir kısaltmalar listesi veya özel karakterler şeklinde derleme işlemidir. Şifreleme bazen şifreleme olarak da adlandırılır, ancak ikinci prosedürün, verileri üçüncü şahıslar tarafından bilgisayar korsanlığına ve okumaya karşı korumayı içerdiğini bilmekte fayda var.
Kodlamanın amacı, bilgi işlem cihazlarında iletimini ve işlenmesini kolaylaştırmak için bilgileri uygun ve özlü bir biçimde sunmaktır. Bilgisayarlar yalnızca belirli bilgi biçimleriyle çalışır, bu nedenle sorunları önlemek için bunu akılda tutmak önemlidir. Veri işleme kavramı, arama, sıralama ve sıralamayı içerir ve kodlama, bilgilerin bir kod biçiminde girilmesi aşamasında gerçekleşir.
Bilgi çözme nedir?
Bir PC kullanıcısı için kodlama ve kod çözmenin ne olduğu sorusu çeşitli nedenlerle ortaya çıkabilir, ancak her durumda kullanıcının bilgi teknolojisi akışında başarılı bir şekilde ilerlemesini sağlayacak doğru bilgileri iletmek önemlidir. Anlayacağınız veri işleme işleminden sonra bir çıktı kodu elde ediliyor. Böyle bir parçanın şifresi çözülürse, orijinal bilgi oluşur. Yani kod çözme, şifrelemenin ters işlemidir. 
Kodlama sırasında veriler, iletilen nesneye tam olarak karşılık gelen sembolik sinyaller biçimini alırsa, kod çözme sırasında iletilen bilgiler veya bazı özellikleri koddan çıkarılır.
Şifreli mesajların birkaç alıcısı olabilir, ancak bilgilerin onların eline geçmesi ve daha önce üçüncü şahıslar tarafından ifşa edilmemiş olması çok önemlidir. Bu nedenle, bilgileri kodlama ve kod çözme süreçlerini incelemeye değer. Bir grup muhatap arasında gizli bilgi alışverişine yardımcı olurlar.
Metin bilgilerinin kodlanması ve kodunun çözülmesi
Bir klavye tuşuna bastığınızda bilgisayar şu şekilde bir sinyal alır: ikili numara, kodu çözme işlemi kod tablosunda bulunabilir - PC'deki karakterlerin dahili gösterimi. ASCII tablosu dünya standardı olarak kabul edilir. 
Ancak kodlama ve kod çözmenin ne olduğunu bilmek yeterli değildir, verilerin bir bilgisayarda nasıl bulunduğunu da anlamanız gerekir. Örneğin, bir ikili kodun bir sembolünü saklamak için bir elektronik bilgisayar 1 bayt, yani 8 bit ayırır. Bu hücre sadece iki değer alabilir: 0 ve 1. Görünüşe göre bir bayt, 256 farklı karakteri şifrelemenize izin veriyor, çünkü bu, yapılabilecek kombinasyonların sayısı. Bu kombinasyonlar anahtardır ASCII tabloları. Örneğin S harfi 01010011 olarak kodlanmıştır. Klavyede buna bastığınızda veriler kodlanır ve çözülür ve ekranda beklenen sonucu alırız.
ASCII standartları tablosunun yarısı rakamlar, kontrol karakterleri ve Latin harfleri. Diğer kısım ise ulusal işaretler, sözde işaretler ve matematikle ilgisi olmayan sembollerle doludur. Açıktır ki, farklı ülkelerde tablonun bu kısmı farklı olacaktır. Basamaklar ayrıca standart özete göre girildikçe ikiliye dönüştürülür. 
Sayı kodlaması
Baskı endüstrisinde de benzer bir görüntü noktalarını kodlama yöntemi kullanılmaktadır. Sadece burada dördüncü rengi kullanmak gelenekseldir - siyah. Bu nedenle dönüşümlü baskı sistemi CMYK olarak kısaltılmıştır. Bu sistem, görüntüleri temsil etmek için otuz iki bit kullanır.

Bilgileri kodlama ve çözme yöntemleri, girdi verilerinin türüne bağlı olarak çeşitli teknolojilerin kullanılmasını içerir. Örneğin, grafik görüntüleri on altı bitlik ikili kodlarla şifreleme yöntemine Yüksek Renk denir. Bu teknoloji, ekrana iki yüz elli altı gölgeyi aktarmayı mümkün kılar. Noktaları şifrelemek için kullanılan ilgili bitlerin sayısını azaltarak grafik görüntü, bilgilerin geçici olarak depolanması için gereken alan miktarını otomatik olarak azaltırsınız. Bu veri kodlama yöntemine dizin denir.
Ses kodlaması
Artık kodlama ve kod çözmenin ne olduğuna ve bu sürecin altında yatan yöntemlere baktığımıza göre, ses verilerinin kodlanması gibi bir soru üzerinde durmaya değer.
Ses bilgisi, temel birimler ve bunların her bir çifti arasındaki duraklamalar olarak temsil edilebilir. Her sinyal dönüştürülür ve bilgisayarın belleğinde saklanır. Sesler, bilgisayarın belleğinde saklanan şifreli kombinasyonlar kullanılarak çıkarılır.
İnsan konuşmasına gelince, kodlamak çok daha zordur, çünkü çeşitli tonlara sahiptir ve bilgisayarın her cümleyi hafızasına önceden girilmiş bir standartla karşılaştırması gerekir. Tanıma, yalnızca konuşulan sözcük sözlükte bulunduğunda gerçekleşir.
İkili kodda bilgi kodlama
Sayısal, metinsel ve grafik bilgileri kodlamak gibi böyle bir prosedürü uygulamak için çeşitli yöntemler vardır. Veri kod çözme genellikle ters teknolojide gerçekleşir.
Sayıları kodlarken, sayının sisteme girilme amacı bile dikkate alınır: aritmetik hesaplamalar için veya sadece çıktı için. İkili sistemde kodlanan tüm veriler, birler ve sıfırlar kullanılarak şifrelenir. Bu karakterlere bit de denir. Bu kodlama yöntemi en popüler olanıdır, çünkü teknoloji açısından düzenlemesi en kolay olanıdır: bir sinyalin varlığı 1, yokluğu 0'dır. İkili şifrelemenin yalnızca bir dezavantajı vardır - bu, karakter kombinasyonlarının uzunluğudur. Ancak teknik açıdan bakıldığında, bir grup basit, tekdüze bileşeni kullanmak, az sayıda daha karmaşık bileşen kullanmaktan daha kolaydır.
Binary Kodlamanın Faydaları
- Bu, çeşitli türleri için uygundur.
- Veri aktarımı sırasında herhangi bir hata oluşmaz.
- Bir PC'nin bu şekilde kodlanmış verileri işlemesi çok daha kolaydır.
- Çift durumlu cihazlar gerektirir.
İkili Kodlamanın Dezavantajları
- İşlemlerini biraz yavaşlatan büyük kod uzunlukları.
- Özel eğitim veya öğretim almamış bir kişi tarafından ikili kombinasyonların algılanmasının karmaşıklığı.

Çözüm
Bu makaleyi okuduktan sonra, kodlama ve kod çözmenin ne olduğunu ve ne için kullanıldığını öğrenebildiniz. Kullanılan veri dönüştürme tekniklerinin tamamen bilgi türüne bağlı olduğu sonucuna varılabilir. Sadece metin değil, aynı zamanda sayılar, resimler ve ses de olabilir.
Çeşitli bilgileri kodlamak, sunum biçimini birleştirmenize, yani daha fazla kullanım için verilerin işlenmesini ve otomasyonunu önemli ölçüde hızlandıran aynı türde yapmanıza olanak tanır.
Elektronik bilgisayarlarda, orijinal bilgi sunum biçimini depolama ve daha fazla işleme için daha uygun bir biçime dönüştüren standart ikili kodlama ilkeleri sıklıkla kullanılır. Kod çözerken, tüm işlemler ters sırada gerçekleşir.
İçerik
I. Bilgi kodlama tarihi………………………………..3
II. Kodlama bilgileri…………………………………………4
III. Metinsel bilgilerin kodlanması………………………….4
IV. Kodlama tablosu türleri…………………………………………...6
V. Metin bilgisi miktarının hesaplanması……………………14
Kullanılan literatür listesi………………………………..16
BEN . Bilgi kodlama geçmişi
İnsanoğlu, ilk gizli bilginin ortaya çıktığı andan itibaren metin şifreleme (kodlama) kullanmaktadır. İşte insan düşüncesinin gelişiminin çeşitli aşamalarında icat edilen birkaç metin kodlama tekniği:
Kriptografi, kriptografidir, metni tecrübesiz kişiler için anlaşılmaz hale getirmek için yazı değiştirme sistemidir;
Her harfin veya karakterin kendi kısa temel parsel kombinasyonuyla temsil edildiği mors kodu veya tekdüze olmayan telgraf kodu elektrik akımı(noktalar) ve üçlü süreli temel parseller (çizgiler);
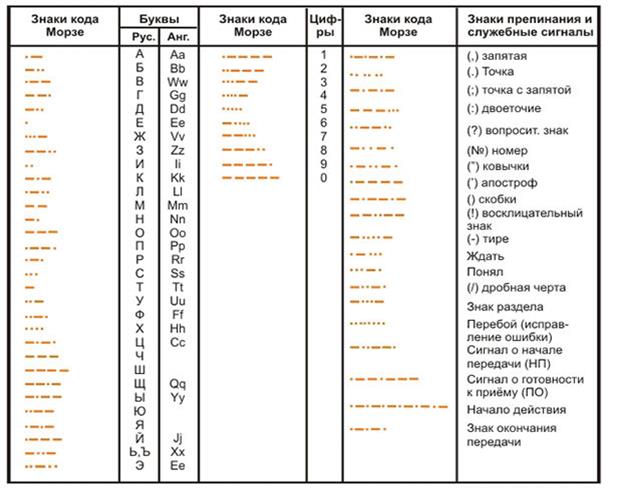
İşaret dili, işitme engellilerin kullandığı bir işaret dilidir.
Bilinen en eski şifreleme yöntemlerinden biri, Roma imparatoru Julius Caesar'ın (MÖ 1. yüzyıl) adını taşır. Bu yöntem, alfabeyi orijinal harften sabit sayıda karakter kaydırarak şifreli metnin her harfinin bir başkasıyla değiştirilmesine dayanır ve alfabe bir daire içinde okunur, yani i harfinden sonra, a dikkate alınır. Yani iki karakter sağa kaydırıldığında "byte" kelimesi "gvlf" kelimesi ile kodlanır. Belirli bir kelimenin şifresini çözmenin ters işlemi, şifrelenmiş her harfi solundaki ikinci harfle değiştirmektir.
II. bilgi kodlama
Bir kod, bazı önceden tanımlanmış kavramları kaydetmek (veya iletmek) için bir kurallar (veya sinyaller) kümesidir.
Bilgiyi kodlama, bilginin belirli bir temsilini oluşturma sürecidir. Daha dar bir anlamda, "kodlama" terimi genellikle bir bilgi sunum biçiminden diğerine geçiş, depolama, iletim veya işleme için daha uygun olarak anlaşılır.
Genellikle, kodlandığında (bazen - şifrelenmiş derler) her görüntü ayrı bir karakterle temsil edilir.
Bir işaret, sonlu bir farklı öğeler kümesinin bir öğesidir.
Daha dar bir anlamda, "kodlama" terimi genellikle bir bilgi sunum biçiminden diğerine geçiş, depolama, iletim veya işleme için daha uygun olarak anlaşılır.
Bilgisayar metin bilgilerini işleyebilir. Bilgisayara girildiğinde her harf belirli bir sayı ile kodlanmakta ve insan algısı için harici cihazlara (ekran veya baskı) çıktı alındığında bu sayılar kullanılarak harflerin görüntüleri oluşturulmaktadır. Bir dizi harf ve rakam arasındaki yazışmaya karakter kodlaması denir.
Kural olarak, bilgisayardaki tüm sayılar sıfırlar ve birler kullanılarak temsil edilir (insanlar için alışılmış olduğu gibi on basamak değil). Başka bir deyişle, bilgisayarlar genellikle ikili sistemde çalışır, çünkü onları işleyen cihazlar çok daha basittir. Sayıların bir bilgisayara girilmesi ve insan okuması için çıktısının alınması olağan ondalık biçimde yapılabilir ve gerekli tüm dönüştürmeler bilgisayarda çalışan programlar tarafından gerçekleştirilir.
III. Metin bilgilerinin kodlanması
Aynı bilgiler birkaç biçimde sunulabilir (kodlanabilir). Bilgisayarların ortaya çıkmasıyla birlikte, hem bireyin hem de bir bütün olarak insanlığın uğraştığı her türlü bilgiyi kodlamak gerekli hale geldi. Ancak insanlık, bilgi kodlama sorununu bilgisayarların ortaya çıkmasından çok önce çözmeye başladı. İnsanlığın görkemli başarıları - yazma ve aritmetik - konuşmayı ve sayısal bilgileri kodlamak için bir sistemden başka bir şey değildir. bilgiler asla görünmez saf formu, her zaman bir şekilde temsil edilir, bir şekilde kodlanır.
İkili kodlama, bilgiyi temsil etmenin en yaygın yollarından biridir. Sayısal kontrollü bilgisayarlarda, robotlarda ve takım tezgahlarında, kural olarak, cihazın ilgilendiği tüm bilgiler ikili alfabenin sözcükleri biçiminde kodlanır.
1960'ların sonlarından bu yana, bilgisayarlar kelime işlem için giderek daha fazla kullanılmaya başlandı ve şimdi dünyadaki kişisel bilgisayarların (ve çoğu saat) metin bilgilerini işlemekle meşgul. Bir bilgisayardaki tüm bu tür bilgiler ikili kodda temsil edilir, yani ikinin üssü olan bir alfabe kullanılır (yalnızca iki karakter 0 ve 1). Bunun nedeni, bilgiyi bir dizi elektriksel darbe şeklinde temsil etmenin uygun olmasıdır: dürtü yoktur (0), bir dürtü vardır (1).
Bu tür kodlamaya genellikle ikili denir ve sıfırların ve birlerin mantıksal dizilerine makine dili denir.
Bilgisayarın bakış açısından, metin tek tek karakterlerden oluşur. Karakterler yalnızca harfleri (büyük veya küçük harf, Latince veya Rusça) değil, sayıları, noktalama işaretlerini, "=", "(", "&" vb. gibi özel karakterleri ve hatta kelimeler arasındaki boşlukları (özellikle dikkat edin!) içerir. .
Metinler klavye kullanılarak bilgisayar belleğine girilir. Anahtarlar bize tanıdık gelen harfler, sayılar, noktalama işaretleri ve diğer sembollerle yazılmıştır. RAM'e ikili kod olarak girerler. Bu, her karakterin 8 bitlik bir ikili kodla temsil edildiği anlamına gelir.
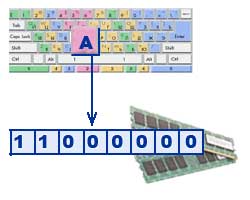 Geleneksel olarak, bir karakteri kodlamak için 1 bayta eşit bilgi miktarı kullanılır, yani. I \u003d 1 bayt \u003d 8 bit. Olası olayların sayısı K ile bilgi miktarı I arasında ilişki kuran bir formül kullanarak, kaç farklı karakterin kodlanabileceğini hesaplayabilirsiniz (karakterlerin olası olaylar olduğunu varsayarak): K = 2 I = 2 8 = 256, yani metinsel bilgilerin temsili, 256 karakter kapasiteli alfabeyi kullanabilirsiniz.
Geleneksel olarak, bir karakteri kodlamak için 1 bayta eşit bilgi miktarı kullanılır, yani. I \u003d 1 bayt \u003d 8 bit. Olası olayların sayısı K ile bilgi miktarı I arasında ilişki kuran bir formül kullanarak, kaç farklı karakterin kodlanabileceğini hesaplayabilirsiniz (karakterlerin olası olaylar olduğunu varsayarak): K = 2 I = 2 8 = 256, yani metinsel bilgilerin temsili, 256 karakter kapasiteli alfabeyi kullanabilirsiniz.
Bu karakter sayısı, Rus ve Latin alfabelerinin büyük ve küçük harfleri, sayılar, işaretler, grafik semboller vb. dahil olmak üzere metin bilgilerini temsil etmek için yeterlidir.
Kodlama, her karaktere benzersiz bir karakter atanmasıdır. ondalık kod 0'dan 255'e veya 00000000'den 11111111'e karşılık gelen ikili kod. Böylece, bir kişi karakterleri stillerine göre ve bir bilgisayarı kodlarına göre ayırır.
Karakterlerin bayt bayt kodlamasının rahatlığı açıktır, çünkü bir bayt belleğin adreslenebilir en küçük kısmıdır ve bu nedenle işlemci, metin işlemeyi gerçekleştirirken her karaktere ayrı ayrı erişebilir. Öte yandan, 256 karakter, çok çeşitli karakter bilgilerini temsil etmek için oldukça yeterlidir.
Bir karakterin bilgisayar ekranında görüntülenmesi sürecinde, ters işlem gerçekleştirilir - kod çözme, yani karakter kodunu görüntüsüne dönüştürme. Belirli bir kodun bir sembole atanmasının, kod tablosunda sabitlenen bir anlaşma konusu olması önemlidir.
Şimdi soru, her karaktere hangi sekiz bitlik ikili kodun yazılacağı sorusu ortaya çıkıyor. Bunun şartlı bir mesele olduğu açıktır, kodlamanın birçok yolunu bulabilirsiniz.
Bilgisayar alfabesindeki tüm karakterler 0'dan 255'e kadar numaralandırılmıştır. Her sayı, 00000000'den 11111111'e kadar sekiz bitlik bir ikili koda karşılık gelir. Bu kod, ikili sayı sistemindeki karakterin sıra numarasıdır.
IV . Kodlama tablosu türleri
Bilgisayar alfabesindeki tüm karakterlere seri numaraları atanan bir tabloya kodlama tablosu denir.
İçin farklı şekiller Bilgisayar çeşitli kodlama tabloları kullanır.
ASCII (Bilgi Değişimi İçin Amerikan Standart Kodu) kod tablosu, karakterlerin ilk yarısını 0'dan 127'ye kadar sayısal kodlarla kodlayan uluslararası bir standart olarak benimsenmiştir (0'dan 32'ye kadar olan kodlar karakterlere değil işlev tuşlarına atanır).
ASCII kod tablosu iki bölüme ayrılmıştır.
Tablonun sadece ilk yarısı uluslararası bir standarttır, yani; 0 (00000000) ile 127 (01111111) arasındaki sayılara sahip karakterler.
ASCII kodlama tablosunun yapısı
| Seri numarası | kod | Sembol |
| 0 - 31 | 00000000 - 00011111 | 0'dan 31'e kadar sayıları olan karakterlere kontrol karakterleri denir. İşlevleri, ekranda metin görüntüleme veya yazdırma, ses sinyali verme, metni işaretleme vb. İşlemlerini kontrol etmektir. |
| 32 - 127 | 0100000 - 01111111 | Tablonun standart kısmı (İngilizce). Buna Latin alfabesinin küçük ve büyük harfleri, ondalık basamaklar, noktalama işaretleri, her türlü parantez, ticari ve diğer semboller dahildir. Karakter 32 bir boşluktur, yani metinde boş konum. Geri kalan her şey belirli işaretlerle yansıtılır. |
| 128 - 255 | 10000000 - 11111111 | Tablonun alternatif kısmı (Rusça). ASCII kod tablosunun kod sayfası olarak adlandırılan ikinci yarısı (10000000 ile başlayan ve 11111111 ile biten 128 kod) farklı seçeneklere sahip olabilir, her seçeneğin kendi numarası vardır. Kod sayfası, öncelikle Latince dışındaki ulusal yazıları barındırmak için kullanılır. Rus ulusal kodlamalarında, Rus alfabesinin karakterleri tablonun bu bölümüne yerleştirilir. |
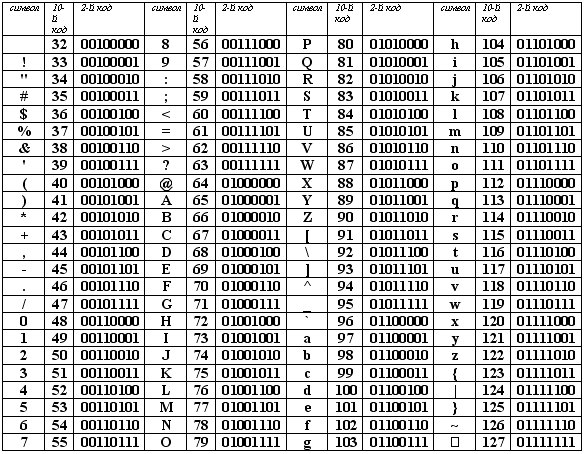
ASCII kod tablosunun ilk yarısı
Kodlama tablosunda harflerin (büyük ve küçük) alfabetik sıraya, sayıların ise artan düzende sıralanmış olmasına dikkat çekilmektedir. Karakterlerin düzenlenmesinde sözlükbilimsel düzenin bu şekilde gözetilmesine alfabenin sıralı kodlama ilkesi denir.
Rus alfabesinin harfleri için sıralı kodlama ilkesi de gözetilir.
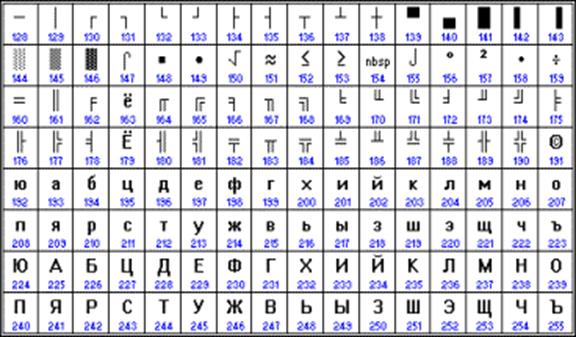
ASCII kod tablosunun ikinci yarısı
Ne yazık ki, şu anda beş farklı Kiril kodlaması var (KOI8-R, Windows. MS-DOS, Macintosh ve ISO). Bu nedenle, Rusça metnin bir bilgisayardan diğerine, bir yazılım sisteminden diğerine aktarılmasıyla ilgili sorunlar sıklıkla ortaya çıkar.
Kronolojik olarak, bilgisayarlarda Rus harflerini kodlamak için ilk standartlardan biri KOI8 ("Bilgi Değişim Kodu, 8 bit") idi. Bu kodlama 70'lerde EC serisi bilgisayarların bilgisayarlarında kullanıldı ve 80'lerin ortalarından itibaren UNIX işletim sisteminin ilk Ruslaştırılmış sürümlerinde kullanılmaya başlandı.
90'lı yılların başından itibaren, MS DOS işletim sisteminin hakimiyet zamanı, kodlama CP866 olarak kalır ("CP", "Kod Sayfası", "kod sayfası" anlamına gelir).
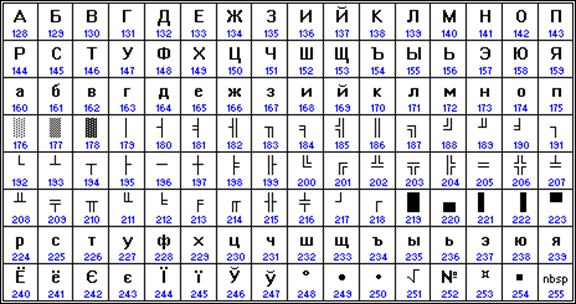
Mac OS işletim sistemini çalıştıran Apple bilgisayarlar kendi Mac kodlamalarını kullanır.

Ayrıca Uluslararası Standardizasyon Örgütü (Uluslararası Standartlar Örgütü, ISO), ISO 8859-5 adlı başka bir kodlamayı Rus dili için bir standart olarak onayladı.
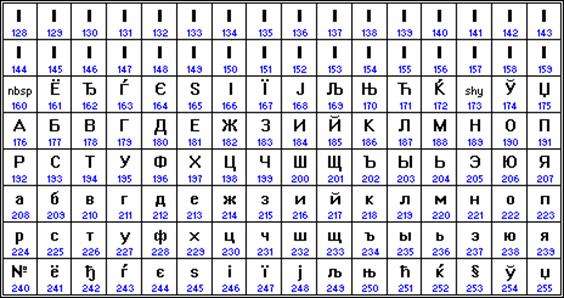
Şu anda kullanılan en yaygın kodlama, CP1251 olarak kısaltılan Microsoft Windows'tur. Microsoft tarafından tanıtılan; hesaba katarak yaygın işletim sistemleri(OS) ve bu şirketin diğer yazılım ürünleri Rusya Federasyonu yaygınlaştı.
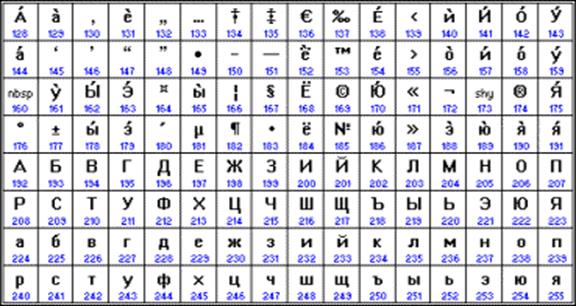
90'ların sonlarından bu yana, karakter kodlama standardizasyonu sorunu, Unicode adlı yeni bir uluslararası standardın getirilmesiyle çözüldü.
Bu 16 bitlik bir kodlamadır, yani karakter başına 2 bayt belleğe sahiptir. Tabii bu durumda kullanılan hafıza miktarı 2 kat artıyor. Ancak böyle bir kod tablosu, 65536 karaktere kadar dahil edilmesine izin verir. Unicode standardının eksiksiz belirtimi, dünyadaki tüm mevcut, tükenmiş ve yapay olarak oluşturulmuş alfabelerin yanı sıra birçok matematiksel, müzikal, kimyasal ve diğer sembolleri içerir.
Bilgisayar belleğindeki sözcüklerin dahili gösterimi
bir ASCII tablosu kullanarak
Bazen, başka bir bilgisayardan alınan Rus alfabesinin harflerinden oluşan metin okunamaz - monitör ekranında bir tür "abracadabra" görünür. Bunun nedeni, bilgisayarların Rus dilinin farklı karakter kodlamalarını kullanmasıdır.
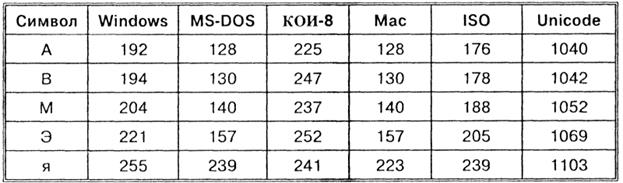
Böylece her kodlama kendi kod tablosu ile belirtilir. Tablodan da görülebileceği gibi, aynı ikili kod çeşitli kodlamalar farklı semboller atanır.
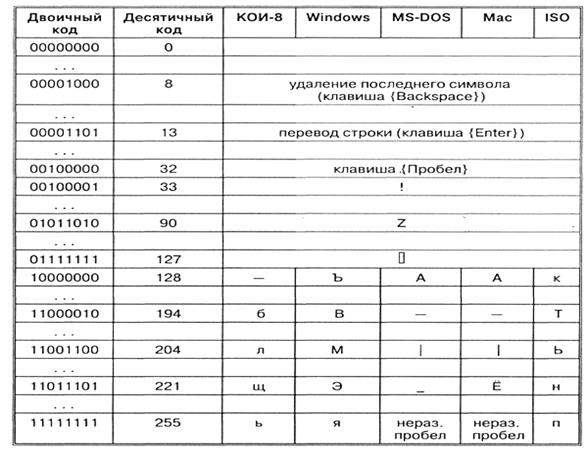 Örneğin CP1251 kodlamasında sayısal kodların 221, 194, 204 dizisi "bilgisayar" kelimesini oluştururken, diğer kodlamalarda anlamsız bir karakter kümesi olacaktır.
Örneğin CP1251 kodlamasında sayısal kodların 221, 194, 204 dizisi "bilgisayar" kelimesini oluştururken, diğer kodlamalarda anlamsız bir karakter kümesi olacaktır.
Neyse ki, çoğu durumda, bu, uygulamalara yerleşik özel dönüştürücü programları tarafından yapıldığından, kullanıcının metin belgelerinin kodunu dönüştürme konusunda endişelenmesine gerek yoktur.
v . Metin bilgisi miktarının hesaplanması
Görev 1: KOI8-R ve CP1251 kodlama tablolarını kullanarak "Roma" kelimesini kodlayın.
Çözüm:

Görev 2: Her karakterin bir bayt tarafından kodlandığını varsayarak, aşağıdaki cümlenin bilgi hacmini tahmin edin:
“En dürüst kuralların amcam,
Ciddi anlamda hastalandığımda,
Kendini saygı duymaya zorladı
Ve daha iyisini düşünemedim."
Çözüm: Bu cümlede noktalama işaretleri, tırnak işaretleri ve boşluklar dahil 108 karakter vardır. Bu sayıyı 8 bit ile çarpıyoruz. 108*8=864 bit elde ederiz.
Görev 3:İki metin aynı sayıda karakter içerir. İlk metin Rusça, ikincisi ise alfabesi 16 karakterden oluşan Naguri kabilesinin dilinde yazılmıştır. Kimin metni daha fazla bilgi taşır?
Çözüm:
1) I \u003d K * a (metnin bilgi hacmi, karakter sayısı ile bir karakterin bilgi ağırlığının çarpımına eşittir).
2) Çünkü her iki metin de aynı sayıda karaktere sahiptir (K), bu durumda fark, alfabenin bir karakterinin (a) bilgi içeriğine bağlıdır.
3) 2 a1 = 32, yani a 1 = 5 bit, 2 a2 = 16, yani ve 2 = 4 bit.
4) I 1 = K * 5 bit, I 2 = K * 4 bit.
5) Rusça yazılan metnin 5/4 kat daha fazla bilgi taşıdığı anlamına gelir.
Görev 4: 2048 karakter içeren mesajın hacmi MB'nin 1/512'si kadardı. Alfabenin gücünü belirleyin.
Çözüm:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bit - mesajın bilgi hacmi bit'e dönüştürüldü.
2) a \u003d I / K \u003d 16384 / 1024 \u003d 16 bit - alfabenin bir karakterine düşer.
3) 2*16*2048 = 65536 karakter - kullanılan alfabenin gücü.
Görev 5: Canon LBP lazer yazıcı ortalama 6,3 Kbps hızında yazdırır. Bir sayfada ortalama 45 satır, her satırda 70 karakter (1 karakter - 1 byte) olduğu biliniyorsa 8 sayfalık bir belgeyi yazdırmak ne kadar sürer?
Çözüm:
1) 1 sayfada yer alan bilgi miktarını bulun: 45 * 70 * 8 bit = 25200 bit
2) 8 sayfadaki bilgi miktarını bulun: 25200 * 8 = 201600 bit
3) Tek tip ölçü birimlerine getiriyoruz. Bunu yapmak için Mbps'yi bitlere çeviriyoruz: 6.3 * 1024 = 6451.2 bps.
4) Baskı süresini bulun: 201600: 6451.2 = 31 saniye.
Kaynakça
1. Ageev V.M. Bilgi teorisi ve kodlama: ölçüm bilgisinin ayrıklaştırılması ve kodlanması. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Bilgi teorisi ve kodlamanın temelleri. - Kiev, Vishcha okulu, 1986.
3. En basit metin şifreleme yöntemleri / D.M. Zlatopolsky. - M.: Chistye Prudy, 2007 - 32 s.
4. Ugrinovich N.D. Bilişim ve bilgi teknolojileri. 10-11. Sınıflar için ders kitabı / N.D. Ugrinovich. – M.: BİNOM. Bilgi Laboratuvarı, 2003. - 512 s.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n
KODLAMA BİLGİSİ
KODLAMA BİLGİSİ
Mesaj öğeleri ve sinyaller arasında, yardımı ile bunların düzeltilebileceği bir yazışma kurulması.
İzin vermek İÇİNDE, ,
- birçok öğe mesajlar, bir sembollü alfabe , Sonlu bir sembol dizisi çağrılsın. bu alfabedeki kelime Alfabedeki birçok kelime A isminde set ile bire bir karsılastırılırsa kod İÇİNDE. Kodda yer alan her kelime, çağrılır. kod kelime. Kod sözcüğündeki karakter sayısı çağrılır. kelime uzunluğu. Kod sözcükler aynı veya farklı olabilir. uzunluk. Bu koda uygun olarak adlandırılır. tekdüze veya düzensiz.
K. ve.'nin hedefleri: giriş bilgilerinin sunumu, bilgi kaynaklarının bir iletim kanalı ile koordinasyonu, verilerin iletilmesi ve işlenmesindeki hataların tespiti ve düzeltilmesi, bir mesajın anlamının gizlenmesi (kriptografi), vb. bir nesnenin özellikleri, kural olarak, kodun en ekonomik şekilde sunulabileceği şekildedir. Kaynak kodlayıcı, mesajlardan fazlalığı kaldırarak bu sorunu çözer. Veri geçişinin diğer aşamaları - bir iletim kanalı üzerinden iletim ve (veya) bellek cihazlarında depolama - girişim nedeniyle bunlarda meydana gelen hataların tespit edilmesini ve (veya) düzeltilmesini gerektirir. Bu hedeflere, kanal yazarı tarafından gerçekleştirilen düzeltici kodlama ile ulaşılır. Son olarak, bir bilgisayarda işleme sırasındaki bozulmalardan elde edilen bilgiler aritmetik kullanılarak gerçekleştirilir. kodlar.
Değer Kodlaması. Doğal sayı N ilişki gerçekleşirse, konumsal ağırlık değerli bir sayı sisteminde temsil edilir

dijital alfabe nerede P basamaklar, " - basamak ağırlıkları, - basamak sayıları. "Konumsal" terimi, koşullu eşitlikle ifade edilen bir sayının kod temsilinde (veya sadece bir kodda) olduğu anlamına gelir.
a rakamıyla ilişkili kantitatif eşdeğer ben, koddaki konumuna bağlıdır. "Önemli" terimi, her basamağın sahip olduğu anlamına gelir. pl. Düşük sipariş ağırlığı p 0 dijital ölçüm teknolojisinde analogdan dijitale dönüştürmenin çözünürlüğü ile tanımlanır. alfabe seçimi A ve tartı sistemleri R konumsal sayı sistemlerinin sınıflandırılmasını belirtir (değer kodlaması). Doğal sistemlerde
ve eğer N- sayı sisteminin temeli - bir doğal sayı, herhangi bir sayı X olarak sunulabilir
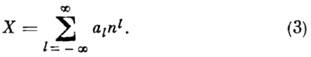
Değiştirilen bir alfabe seçimi: A= (0, 1, . . ., P-1), bir=(-n- 1, . . ., 1, 0) veya simetrik: bir = (-p- 1, . . ., -1, 0, 1, . . ., P- 1) sırasıyla pozitif, negatif veya herhangi bir sayıyı temsil etmenizi sağlar. Simetrik bir sistemin tek bir tabanı olmalıdır.
Bilgisayar neredeyse yalnızca, sayıları (0, 1) ve bir dizi sayıyı temsil eden doğal bir ağırlık oranını içeren bir konumsal ikili ofset sistemi (n = 2) kullanır.
Örneğin, farklı bir sayı dizisi kullanmak mümkündür. (-1, 1), bazı özel avantajlar sağlar.
Basamaklarının ağırlıkları doğal (2) olmayan, ancak daha karmaşık bir oranda olan, örneğin Fibonacci serisini (veya "altın oranı") oluşturan ikili sistemler gelişir. Sayı N Fibonacci kodunda oran ile temsil edilir
ilişki ile ilgili Fibonacci sayıları nerede
Ayrıştırma (4) sayısı N belirsiz bir şekilde. Herkes için N ardışık iki sıfırın olmadığı bir kod olduğu gibi, birlerin bir arada bulunmadığı bir kod vardır. Fibonacci kodlarının ve "altın" kodların diğer yapısal özelliklerinin yanı sıra bunlar, depolayan ve hesaplayan kendi kendini düzelten dönüştürücüler oluşturmak için onları uygun hale getirir. cihazlar, dijital olarak kontrol edilen servo sürücüler vb.
Üçlü sayı sistemleri naib. tanımlı üçlü kodda olması anlamında ekonomiktir. Karakter sayısı, en büyük sayı çeşitliliğini ifade edebilir. Gelecekte, tam da bu özellik nedeniyle, sayıları (-1, 0, 1) olan üçlü simetrik kodlama sisteminin dikkate alınacağına inanmak için sebepler var. teknoloji hakimdir. Sorun, üçlü mantıkta temel işlevleri uygulayan öğelerin oluşturulması olmaya devam ediyor: üçlü evirici ve üçlü NAND veya üçlü NOR (bkz. Mantık),
Konumsal olmayan kodlar, özel ölçümlerde kullanılır. ve hesaplayın. cihazlar Konumsal olmayanların en basiti - (2) koyarak üniter bir kod elde edilebilir N=1 ve p 0= 1. numarası var N olarak görünür N=N+l - sıralı olarak toplanan birimler. Örneğin nabız sayaçları bu şekilde çalışır.
Konumsal olmayan kodlama sistemleri arasında artık sınıflardaki sayı sistemi (RNS) öne çıkmaktadır. Sayı N RNS'de eş asal bazlar üzerinde sıralı bir kalıntılar (kalıntılar) seti olarak temsil edilir p1, . . ., rp;, en küçük kalıntı nerede N modulo R. Temel sistemi s 1, s 2, . . ., rp sayıların temsil aralığını tanımlar P=p1 , p2 , . . ., rp SOK aritmetiğinde. işlemler her baz için bağımsız olarak gerçekleştirilir ve bu, performanslarını önemli ölçüde artırmanıza olanak tanır. RNS'de, hatalar bazlar içinde lokalize olduğundan operasyonları kontrol etmek uygundur. Hesaplamaya özel. SOC'de çalışan cihazlarda tablo aritmetiğinin kullanılmasıdır: hesaplanacak fonksiyonun değerleri önceden tabloya girilir ve ardından işlenenlerin değerleri geldiğinde alınır.
Verimli bilgi kaynağı kodlaması, bilgi kaynağının (IS) bilgi özelliklerini iletim kanalıyla eşleştirmeyi amaçlar. AI'nın harflerden oluşan çıktı vermesi gerekiyor M-harf alfabesi
ayrıca, harflerin görünümü istatistiksel olarak bağımsızdır ve dağılıma tabidir.
Kaynak, sembol başına entropi ile karakterize edilir
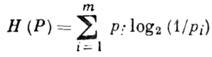
Entropi ![]() AI çıkışında bir sonraki karakterin görünümü hakkında belirsizlik anlamına gelir. eşitlik H(P)=0 dejenere bir dağılımla elde edilir R,çünkü mesaj
AI çıkışında bir sonraki karakterin görünümü hakkında belirsizlik anlamına gelir. eşitlik H(P)=0 dejenere bir dağılımla elde edilir R,çünkü mesaj
deterministik iken; eşitlik ![]() denkleştirilebilir olayla elde edilir - en büyük belirsizliğin durumu. m=2 ve harflerin düzgün görünümü ile bir 1 Ve bir 2 entropi maksimumdur ve H(P) = 1. Bu değer - iki alternatifin denkleştirilebilir seçimi ile belirsizlik - entropi - 1 birimi olarak kullanılır .
denkleştirilebilir olayla elde edilir - en büyük belirsizliğin durumu. m=2 ve harflerin düzgün görünümü ile bir 1 Ve bir 2 entropi maksimumdur ve H(P) = 1. Bu değer - iki alternatifin denkleştirilebilir seçimi ile belirsizlik - entropi - 1 birimi olarak kullanılır .
Her bir kodlama yöntemi, cf ile karakterize edilir. sayı L(P) giriş alfabesinin bir harfi başına çıkış alfabesinin harfleri ve t.İçin alfabetik kodlama ![]() - alfabedeki kelimenin uzunluğu r. Kodlama bire bir ise, o zaman
- alfabedeki kelimenin uzunluğu r. Kodlama bire bir ise, o zaman
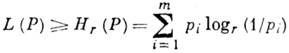
Değer Ben(P) = L(P)-H r (P) isminde dağıtımda kodlama fazlalığı R. Problem, verilen bire bir kodlama sınıfında min. büyüklük Ben(P). Bir minimumun varlığı ve değeri, Shannon'ın gürültüsüz bir kanal için teoremi tarafından belirlenir; bu teorem, sonlu bir alfabeye sahip bir kaynak için olduğunu söyler. bir t entropili H(P) kaynağın harflerine kod sözcükleri öyle bir şekilde atanabilir ki bkz. kod sözcüğü uzunluğu L (P) koşulları sağlayacak
Optimum kod, başka hiçbir kodun daha küçük bir değer sağlayamayacağı şekildedir. L(P).
Optimal olanı bulmak için yapıcı prosedür. belirli bir mesaj setini kodlamak için bir kod 1952'de D. R. Huffman tarafından önerildi. Buradaki fikir, alfabenin harflerinin bir t göre sıralanır ve daha kısa kod sözcükleri daha olası olanlara atanır. Huffman kodu vardır. özellikler: en az olası mesaja karşılık gelen kelime en büyük uzunluğa sahiptir; olasılığı en az olan iki mesaj, biri sıfır, diğeri bir (r=2) ile biten, aynı uzunlukta sözcüklerle kodlanır.
Optimum tekdüze kodlama. Kaynak iki harfli bir alfabe ile olsun ve uzun kelimeler üretsin l. 2'li setin tamamı ile ilgili olarak ben kelimeler (kaynak sözlük) için ve yeterince büyük bir ifade var ben kaynak sözlük iki alt kümeye bölünmüştür: eşlenebilir sözcüklerden oluşan bir grup (çalışan kaynak sözlüğü) ve toplam olasılığı sıfıra yakın olan bir sözcük grubu ("atipik" diziler). Burada H(R) - kaynak sembolü başına entropi. Çalışan sözlükteki kelimelerin oranı çok küçüktür ve giderek artmaktadır. ben sıfır eğilimindedir. Tekdüze veya blok kodlama fikri, kaynak kelimeleri girdi olarak alan kodlayıcının kod kelimelerini yalnızca çalışan sözlükteki kelimelerle eşleştirmesi, geri kalanını hata anlamına gelen tek bir kelimeyle kodlamasıdır. Hata olasılığı, kaynak kelime uzunluğu artırılarak keyfi olarak azaltılabilir. Bu durumda, kodlanmış kelimelerin hacmi, kod kelimenin sembollerini gerektirir. Çalışan sözlüğün sözcükleri hemen hemen eşit olasılığa sahip olduğu için, kod sözcükleri eşit olasılığa sahip olacak ve kod sözcüğün sembol başına düşen entropisi 1 bite yakın olacaktır. Bu nedenle kodlayıcı, her karakteri 1 bitlik olası maksimum bilgi yüküne kadar "yüklemesi" nedeniyle tasarruf ederek, uzunlukta sözcükler üretir.
Kaynak kodlama, veritabanları ve veri bankalarındaki veri dizilerini "sıkıştırma" ihtiyacı nedeniyle yeni bir anlam kazanır. Örgütsel, ekonomik, ölçüm dizileri. bilgiler o kadar büyük bir fazlalığa sahiptir ki, %80-85'e kadar izin verirler. Gelişmiş veri tabanı yönetim sistemleri (DBMS) özel var. yukarıda belirtilen ilkeler üzerinde çalışan, metni analiz etmek, sıkıştırmak ve geri yüklemek için programlar (yardımcı programlar).
Düzeltici bilgi kodlaması. Amacı, gürültülü bir kanal üzerinden bilgi iletimi sırasında meydana gelen kod sözcüklerindeki hataları tespit etmek ve (veya) düzeltmektir. Bozulma düzeltmesi, iletim sistemine fazlalık getirerek mümkündür. Bu durumda, kanal kodlayıcının tüm sözcük kümesinden N0 sadece N iletilen mesajlarla (izin verilen kelimeler) eşleşir. Teorik olarak, bu durumda tespit edilen hataların oranı 1-N/N 0 .
Bilgi kelimesinin olduğu varsayılmaktadır. sen= (sen 1, . . ., sen n), nerede sen j=0, 1, kendisine bir kod sözcüğü atayan kanal kodlayıcının (bundan sonra kodlayıcı olarak anılacaktır) girişine beslenir X (x 1 , . .., xl), ,
Bu nedenle kodlayıcı tanım gereği ekler. kelime için kural sen bir grup k=l-n fazlalık (düzeltici) bitler. Bir kod sözcüğü X parazitin bazı sembolleri bozduğu gürültülü bir kanala girer x ben . Kanal çıkışında alınan kelime Y= (1'de , . . ., y 2) kelimeyi geri yükleyen (bir perde yaklaşımıyla) kod çözücüye girer X. Kod sözcükleri, vektörler arasındaki mesafeyi belirten bir Hamming metriği ile doğrusal bir vektör uzayında vektörler olarak çalıştırılır.
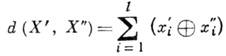
Shannon'ın gürültülü kanallar için teoremi, uygun kodların yardımıyla, iletim hızının iletişim kanalının bant genişliğini aşmaması koşuluyla, kod çözme işleminden sonraki hata olasılığının keyfi olarak küçük olacak şekilde bilgi iletmenin mümkün olduğunu belirten yapıcı değildir: bir kod oluşturmanın bir yolunu göstermez. Bir kod oluştururken, iletilen kelimedeki hataların oluşumu için model seçimi belirleyici bir öneme sahiptir.
Naib. eşit derecede olası hata çözümlemesine sahip simetrik bir kanal modeli yaygındır. türleri - geçişler, örneğin, karakter 0'dan 1'e ve 1'den 0'a.
"Silinmeli" kanal modeli özeldir. Böyle bir kanalın çıkış alfabesi özel içerir. bu tür bir hata oluştuğunda giriş alfabesindeki karakterlerin aktarıldığı silme simgesi.
Genişletilmiş fark iletilen sembol dizisindeki (kod sözcüğü) hataların dağılımına ilişkin varsayımlar. Bağımsız hataların bir modeli (belleği olmayan bir kanal), gruplandırılmış hataların bir modeli (hata patlamaları), belirli bir birbirinden uzaklık vs.
İkinci varsayım altında, kodun düzeltme yeteneği, kod sözcüklerinin yardımıyla tespit edilen ve (veya) düzeltilen hataların sayısı ile tahmin edilir. Kanalda olduğu varsayılmaktadır. X sembol sembol toplamı (mod 2) gürültü vektörü Z, kelime oluşturmak. Ortaya çıkan hatanın çokluğu, birim sayısı (Hamming ağırlığı) ile aynıdır. Z. bir vektörde ben fazla olmayan elementler R birimler bir şekilde yerleştirilebilir.
Bu, iletim sırasında oluşabilecek hataların çeşitliliğidir.
Bağımsız hatalara göre düzeltme yeteneğini belirleyen kodun temel özelliği, kod mesafesidir. Kod mesafesi, tüm olası kelimeler = ( , . . ., ) ve kod arasındaki en küçük Hamming mesafesidir. Kodun tüm kombinasyonları algılaması için S hatalar ve tüm kombinasyonları düzeltildi T hatalar için kod mesafesinin eşit olması gerekli ve yeterlidir. S+T+1.
Simetrik bir kanal için geniş bir kod sınıfı, bir bilgisayarın ana belleğindeki bilgileri korumak için yaygın olarak kullanılan Hamming kodları gibi doğrusal (grup) kodlardır. Hamming kodunun bir kod mesafesi vardır d=3, tek hataları düzeltir ve çift hataları tespit eder. 2°, 2, 2 2 , . . . Doğrusal kod, bir çift matris tarafından verilir: generator , ve check . Üreten matrisin satırları, 2 n eleman - kod sözcükleri içeren bir uzayın temelini oluşturan doğrusal olarak bağımsız vektörlerdir. Kontrol matrisinin satırlarının her biri , ve satırlarına diktir
Satır kodu kodlayıcı, kurala göre kod sözcükleri üretir XT = U T G. Bozulma modeli, kanalda X ile sembol simge toplam gürültü vektörü Z, bir kelime oluşturmak Y=X+Z.
Kod çözme fikri bir ürün oluşturmaktır S T \u003d Y T H T, sendrom denir. eşitlik S= 0 şu anlama gelir Z=0, veya hata tespit edilemez. Sendrom, her biri oluşan bir hatayı belirtmek için kullanılabilen 2 k -1 sıfır olmayan gerçekleştirmeye sahiptir.
döngüsel. kodlar, grup kodlarında bir alt sınıf olarak yer alır. Onlarda, kelime ile birlikte X ve tüm döngüsü-lich'i girer. permütasyonlar. Kod sözcükleri iki polinomun ürünü olarak oluşturulur: U (E) derece P- 1, katsayı to-rogo bilgilendirici bir kelime oluşturur sen, ve üretken gr (E) derece lp, indirgenemez ve kalansız bölme binom (1+ E l). Kod çözme, alınan kelimenin (polinom) şuna bölünmesinden oluşur: g(E). Sıfır olmayan bir kalanın varlığı, bir hatanın varlığını gösterir. döngüsel. kodlar genellikle sistematik değildir.
Uzman döngüsel kodlar, hata patlamalarını algılamak ve düzeltmek için tasarlanmıştır, örneğin, formun polinomlarını üreterek tanımlanan Yangın kodları g(E) = =p(E)(Ec +1), Nerede p(D) - indirgenemez polinom ve miktar İle düzeltilen ve tespit edilen hata patlamalarının uzunluğu ile belirlenir.
Hata yığınları, manyetik depolama aygıtları için tipiktir. taşıyıcılar, özellikle manyetik sürücüler için. diskler (NMD) modern. bilgisayar (bkz. cihaz hafızası). Bu nedenle NMD'deki verileri korumak için K. ve yaygın olarak kullanılmaktadır. döngüsel donanım tarafından uygulanan kodlar.
Aritmetik kodlar aritmetiğin yürütülmesi sırasında oluşan hataları tespit etmek için tasarlanmıştır. bilgisayar işlemleri. Aritmetik teorisinde. kodlamada, Hamming'den farklı olan ağırlık, uzaklık ve hata kavramları tanıtılmaktadır. Aritmetik sayının ağırlığı min olarak tanımlanır. bir sayının formdaki temsilindeki terim sayısı, ![]() . Sayının büyüklüğünün r "= 0, 1, 2, ... ile değiştiği hatalara aritmetik denir. Arasındaki aritmetik mesafe N 1 Ve N 2 - aritmetik farkın ağırlığı, sayıyı çeviren hatanın çokluğuna eşittir N 1 v N2, ve düzeltme yeteneği aritmetiğini belirler. kodu, Hamming mesafesine benzer.
. Sayının büyüklüğünün r "= 0, 1, 2, ... ile değiştiği hatalara aritmetik denir. Arasındaki aritmetik mesafe N 1 Ve N 2 - aritmetik farkın ağırlığı, sayıyı çeviren hatanın çokluğuna eşittir N 1 v N2, ve düzeltme yeteneği aritmetiğini belirler. kodu, Hamming mesafesine benzer.
ortak olarak BİR- sayı kodlaması N- işlenen - özel olarak seçilmiş bir faktörle çarpılarak gerçekleştirilir A. Böylece, 2 kod mesafesine sahip olan 3A kodu, toplamı 3'e bölerek tekli hataları algılar. Hatalar, sıfır olmayan bir kalanla algılanır: aritmetik değer. hatalar 2 ben 3'e bile bölünmez. Tekli hatalara ek olarak, A=3'te çifte hataların bir kısmı da bulunur - doğru ve hatalı sonucun 3'e bölündükten sonra eşleşmeyen kalanlara sahip olduğu hatalar.
Şifreleme, şifrelenmiş mesajın her harfine belirli bir harf atandığında ikame ile gerçekleştirilir. karakter (örneğin, başka bir harf), ya permütasyon yoluyla, yapay metin blokları içindeki harfler yer değiştirdiğinde ya da bu yöntemlerin bir kombinasyonu ile. Shannon, kabul edilebilir bir değer için deşifre edilemeyen kriptogramların mümkün olduğunu gösterdi.
Aydınlatılmış.: 1) Stakhov A.P., Algoritmik ölçüm teorisine giriş, M., 1977; kendisine ait, Altın Oranın Kodları, M., 1984; 2) Akushsky I., Yuditsky D., Kalan sınıflarda makine aritmetiği, Moskova, 1968; 3) Gal-lager R., Bilgi teorisi ve güvenilir iletişim, çev. İngilizceden, M., 1974; 4) Dadaev Yu.G., Aritmetik kodlar teorisi, M., 1981; 5) Arshinov M. N., Sadovsky L. E., Codes and Mathematics, Moskova, 1983. L. N. Efimov.
Fiziksel ansiklopedi. 5 ciltte. - M.: Sovyet Ansiklopedisi. Genel Yayın Yönetmeni A. M. Prokhorov. 1988 .
Diğer sözlüklerde "BİLGİ KODLAMASI" nın ne olduğuna bakın:
bilgi kodlama- Verileri dönüştürme ve (veya) sunma süreci. [GOST 7.0 99] Konular bilgi kitaplığı faaliyetleri EN bilgi kodlama FR codage de l'information ... Teknik Tercümanın El Kitabı







