Kodiranje tekstualnih informacija. Kompletne lekcije - Hipermarket znanja
Predmet
- Kodiranje tekstualne informacije.
Target
- Uvesti metode kodiranja tekstova u memoriji računara.
Tokom nastave
U polju računara, tekst je niz bilo kog karaktera. Danas mašine koriste skup takvih znakova koji sadrži do 256 znakova.
Štaviše, svaki ima svoj osmobitni binarni kod. Dakle, u memoriji računara, bilo koji karakter teksta zauzima 8 bita ili 1 bajt.
Imajući ovo na umu, čini se da je moguće izmjeriti količinu memorije potrebne za pohranjivanje bilo kojeg tekstualnog dokumenta.
1 bit (binarna cifra) ima dva značenja, dodavanjem svakog bita kodu udvostručuje se broj dobijenih kombinacija: 2 bita - četiri opcije, 3 bita - osam, 4 bita - šesnaest itd.
Na primjer, A4 pisana stranica sadrži otprilike 55 redova. Svaki od njih sadrži oko 60 znakova.
Sa ovim informacijama možemo izbrojati količinu tekstualnih informacija na datoj stranici.
Svaki znak je 1 bajt informacije, a ukupan broj znakova je 3300 (60 puta 55). Ispostavilo se da je količina informacija na stranici oko 3 KB.
Binarni kodovi i njihovi odgovarajući znakovi povezani su tablicom kodiranja. Sve tabele koje se koriste na računaru su bazirane na američkom ASCII4 standardu. Definira prvih 128 kodova ( pisma, brojevi, znakovi). Preostalih 128 se koristi za posebne znakove i slova nacionalnih abeceda (ruskog, kineskog, arapskog). A pošto za to nije bilo zajedničkih standarda, pojavila su se mnoga kodiranja, uključujući i ćirilicu.
Zbog toga se ponekad može vidjeti nečiji tekst u obliku skupa "šverca".
Da bi se takvi tekstovi mogli čitati, postoje programi za pretvaranje. Oni zamjenjuju binarni kod svakog znaka kodom drugačijeg kodiranja. I, često, korisnik mora odrediti iz kojeg kodiranja ide konverzija.
Međutim, već postoje programi koji mogu automatski odrediti kodiranje izvornog teksta.
Dakle, tabela u kojoj su svim simbolima mašinske abecede dodeljeni odgovarajući serijski brojevi naziva se tabela kodiranja.
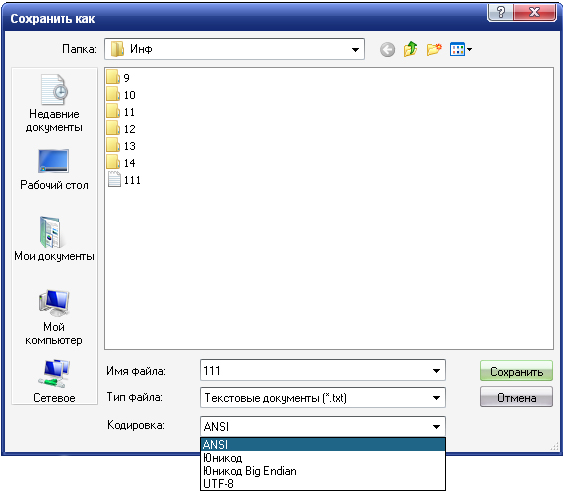
ASCII tabela kodova
Kao što je već pomenuto, ASCII tabela (Američki standardni kod za razmenu informacija) postala je međunarodni standard za računare.
Takođe možete pronaći još jednu tabelu - KOI-8 (Information Exchange Code), koja se koristi u računarskim mrežama.
Tablica ASCII kodova je podijeljena na dva dela.
U međunarodnoj praksi standard je samo prvi deo tabele, odnosno znakova sa brojevima od 0 (00000000) do 127 (01111111). To su mala i velika slova latinice, brojevi, znaci interpunkcije, različite vrste zagrade, komercijalni i drugi simboli.
Numerisanje znakova od 0 do 31 obično se naziva kontrolnim znakovima. Oni kontrolišu proces prikazivanja teksta na ekranu ili štampanja, zvučni signal do zvučnika i označavanje teksta.
Znak 32 je razmak ili prazna pozicija u tekstu.
Skrećem vam pažnju da su u tablici kodiranja slova (velika i mala slova) raspoređena abecednim redom, a brojevi po rastućem redoslijedu vrijednosti. Ovo poštovanje leksikografskog reda u rasporedu znakova naziva se princip sekvencijalnog kodiranja abecede.
Druga polovina ASCII tabele zove se kodna stranica. Ovo je preostalih 128 kodova od 10000000 do 11111111, koji imaju različite opcije, a svaka (!) opcija ima svoj broj.
Prije svega, kodna stranica se koristi za smještaj nacionalnih alfabeta koje se razlikuju od latinice. U ruskim nacionalnim kodovima, znakovi ruskog alfabeta nalaze se u ovom dijelu tabele. Dakle, za svaki jezik posebno.
Unicode kodiranje
Ovo je 16-bitno kodiranje - ima 2 bajta memorije za svaki znak.
U skladu s tim, količina zauzete memorije se povećava za 2 puta. Ali takva kodna tabela može sadržati do 65536 znakova.
Puna verzija Unicode-a uključuje sve postojeće i izumrle alfabete svijeta i mnoge matematičke, muzičke, hemijske simbole.
Programi za rad sa tekstom
Želja za pojednostavljenjem rada s tekstom dovela je do stvaranja mnogih programa posebno dizajniranih za to - uređivača teksta.
Procesor teksta nije samo zamjena za pisaću mašinu, već i univerzalni alat za rad s tekstovima.
Oni pružaju vrlo široke mogućnosti za manipulaciju tekstualnim dokumentima.
U takvim programima možete raditi ne samo sa pojedinačnim likovima, već i sa njima riječi, redovi, paragrafi, grafike. Pored takvih operacija kao što su kucanje, kopiranje, spremanje, premještanje i brisanje fragmenata, promjena fonta, boje i veličine, slanje teksta na disk i ispis.
Obrađeni tekst je predstavljen kao u obliku listova papira određenog formata, koji se pomiču po ekranu.
Prednosti arhiviranja tekstova:
1) ušteda papira
2) kompaktan smještaj
3) mogućnost trenutnog kopiranja na druge medije
4) mogućnost prenosa teksta preko linija mreže ili Interneta
Pitanja
1. Šta je tabela kodiranja?
2. Koje je kodiranje postalo međunarodni standard?
3. Šta se zove uređivač teksta?
Spisak korištenih izvora
1. Lekcija na temu: „Proces kodiranja teksta“, Pavlov M. S., Čerkasi
2. Eremin E.A. Kako radi bafer tastature / Informatika #45, 2004
3. Semakin I.G.
P Prvih 128 znakova je standardizirano. Oni su isti u apsolutno svim kodovima širom svijeta. Ako govorimo o simbolima, onda je ovo cijela engleska abeceda, brojevi i osnovni znakovi. Preostalih 128 pozicija dato je "na milost i nemilost" nacionalnim pismima i dodatnim znakovima. Tako je to u velikoj većini zemalja. Međutim, u Rusiji ne postoji jedno ili čak dva nacionalna kodiranja. Tačno ih je pet. Dakle, ako je tekst napisan na ruskom u jednom kodiranju, onda će u drugom izgledati kao apsolutno nasumični skup različitih znakova.
M Mnogi čitaoci ovog Wiki članka će se vjerovatno zapitati: "Ali zašto u Rusiji postoji toliko različitih kodiranja?". Da biste odgovorili na ovo pitanje, moraćete da napravite kratku digresiju u istoriju. Sve je počelo 70-ih godina prošlog veka. Tada se na našim računarima pojavio UNIX operativni sistem (ne ličnim - tada ih nije bilo). Naravno, prilagođena je ruskom jeziku. Tada se pojavilo prvo kodiranje pod nazivom KOI-8. Od tada je postao "de facto" standard za sve slične UNIX-u operativni sistemi- na primjer za Linux.
H nešto kasnije, počeo je pobednički marš personalnih računara. A zajedno sa njima, MS-DOS operativni sistem je postao veoma raširen. Njegov programer, Microsoft, nije koristio KOI-8 tokom rusifikacije, već je smislio sopstveno kodiranje, nazvano DOS (kodna stranica 866). U ovoj tabeli, među dodatnim likovima, pojavili su se elementi okvira, što je uvelike olakšalo crtanje tabela u raznim uređivačima teksta. Ovo je takođe doprinelo širenju DOS kodiranja. Inače, otprilike u isto vrijeme ili nešto kasnije Rusko tržište Izašli su Macintosh računari. Naravno, tokom rusifikacije operativnog sistema instaliranog na njima, stvorena je još jedna tablica simbola - MAC. Istina, treba napomenuti da se gotovo nikada nije koristio zbog male distribucije samih Mac-ova.
IN 1990. Microsoft je objavio novi operativni sistem Windows verzija 3.0. U njega je ugrađena podrška za nacionalne jezike. Ali evo šta je zanimljivo - iz nekog razloga, stručnjaci Microsofta nisu koristili već postojeće rusko DOS kodiranje, već su opet izmislili novi - Win (kodna stranica 1251). Najvjerovatnije je to učinjeno zbog uvođenja drugih dodatnih znakova u tablicu umjesto okvira i sličnih znakova. Ali najvjerovatnije nećemo sa sigurnošću znati razloge za pojavu Win kodiranja. I kasnije je međunarodna organizacija Međunarodna organizacija za standardizaciju, koja se bavi pitanjima standardizacije, skrenula pažnju na problem prisustva nekoliko nacionalnih kodiranja u Rusiji i nekim drugim zemljama. I opet, umjesto da uzmu najčešće kodiranje kao osnovu (u to vrijeme to je bila Win tablica), predstavnici ISO-a su izmislili svoje (ISO 8859-5). Ali praktična primjena nije primila. I iako je ISO kodiranje podržano u svim pretraživačima, vjerovatno ne postoji nijedna stranica koja ga koristi.
TO Osim toga, pokušaji da se "gura" univerzalno Unicode kodiranje primjećuju se dosta dugo. Njegovi tvorci su predložili korištenje ne jednog, već dva bajta za svaki znak. Ovo vam omogućava da povećate broj mogućih vrijednosti do 65535 i da u tabelu uklopite sve znakove postojećih abeceda. Istina, svi ovi pokušaji ostaju apsolutno bezuspješni.
Stoga ističemo nekoliko zajedničkih karakteristika razlika kodiranja:
1) Ukupno ima 256 karaktera.
2) Prvih 128 znakova je standardizirano, isti su u cijelom svijetu, a sastoje se od engleskog alfabeta, brojeva i znakova.
3) Preostalih 128 dato je "na milost i nemilost" nacionalnih pisama i dodatnih znakova.
4) U Rusiji postoji 5 različitih kodiranja!
5) Tekst napisan u jednom kodiranju na ruskom, u drugom kodiranju, izgledat će kao različiti nasumični znakovi, stoga je svako kodiranje individualno i ne podržava blisku "saradnju" s drugim kodiranjem.
6) Svako kodiranje je specificirano svojom vlastitom tablicom kodova. Na isto binarni kod V razna kodiranja dodijeljeni su različiti simboli.
7) Zajednička karakteristika u većini kodiranja se koristi za 1 znak tačno 1 bajt. Postoji Unicode kodiranje, gdje su njegovi tvorci predložili korištenje ne jednog, već dva bajta za svaki znak. Ovo vam omogućava da povećate broj mogućih vrijednosti do 65535 i da u tabelu uklopite sve znakove postojećih abeceda. Istina, svi ovi pokušaji ostaju apsolutno bezuspješni.
Razlika između tekstualnih datoteka kreiranih u različitim kodovima
TO Kada je tekstualna datoteka kodirana, ona se pohranjuje prema standardu kodiranja, specifičnom skupu pravila koja dodjeljuje numeričku vrijednost svakom tekstualnom karakteru. Postoji mnogo različitih standarda kodiranja koji predstavljaju skupove znakova koji se koriste u različitim jezicima, a neki od ovih standarda podržavaju samo znakove iz jednog jezika. Dakle, za kineski tekst se može koristiti standard kodiranja GB2312-80 u slučaju pojednostavljenog pisanja i standard kodiranja Big5 u slučaju tradicionalnog pisanja.
P Budući da Microsoft Word koristi standard za kodiranje Unicode (Unicode. Standard za kodiranje znakova koji je razvio Unicode konzorcij. Koristeći više od jednog bajta za predstavljanje svakog znaka, Unicode vam omogućava da predstavite gotovo sve svjetske jezike u jednom skupu znakova.) , možete otvoriti i spremiti u Microsoft Word datoteke koristeći standarde kodiranja za različite jezike. Na primjer, kada radite s operativnim sistemom koji koristi sučelje na engleski jezik, možete otvoriti tekstualnu datoteku u programu Microsoft Word koja je kreirana korištenjem standarda kodiranja za grčki ili japanski.
Sadržaj
I. Istorija kodiranja informacija……………………………………………..3
II. Informacije o kodiranju…………………………………………4
III. Kodiranje tekstualnih informacija……………………………….4
IV. Vrste tablica kodiranja…………………………………………………………...6
V. Proračun količine tekstualnih informacija…………………………………14
Spisak korištene literature……………………………………………..16
I
.
Istorija kodiranja informacija
Čovječanstvo koristi šifriranje (kodiranje) teksta od samog trenutka kada su se pojavile prve tajne informacije. Evo nekoliko tehnika kodiranja teksta koje su izmišljene u različitim fazama razvoja ljudske misli:
Kriptografija je kriptografija, sistem mijenjanja pisanja kako bi se tekst učinio nerazumljivim neupućenim osobama;
Morzeov kod ili neuniformni telegrafski kod, u kojem je svako slovo ili znak predstavljeno svojom kombinacijom kratkih elementarnih parcela električna struja(tačke) i elementarne parcele trostrukog trajanja (crtice);
Znakovni jezik je znakovni jezik koji koriste osobe sa oštećenjem sluha.
Jedna od najranijih poznatih metoda šifriranja nosi ime rimskog cara Julija Cezara (1. vijek prije nove ere). Ova metoda se zasniva na zamjeni svakog slova šifriranog teksta drugim pomicanjem abecede od originalnog slova za fiksni broj znakova, a abeceda se čita u krug, odnosno nakon slova i, razmatra se a. Dakle, riječ "bajt" kada se pomakne dva znaka udesno je kodirana riječju "gvlf". Obrnuti proces dešifriranja date riječi je da se svako šifrirano slovo zamijeni drugim lijevo od njega.
II.
Kodiranje informacija
Kod je skup konvencija (ili signala) za snimanje (ili prijenos) nekih unaprijed definiranih koncepata.
Kodiranje informacija je proces formiranja određene reprezentacije informacije. U užem smislu, termin "kodiranje" se često shvata kao prelazak sa jednog oblika prezentacije informacija na drugi, pogodniji za skladištenje, prenos ili obradu.
Obično je svaka slika, kada je kodirana (ponekad kažu - šifrirana), predstavljena posebnim znakom.
Znak je element konačnog skupa različitih elemenata.
U užem smislu, termin "kodiranje" se često shvata kao prelazak sa jednog oblika prezentacije informacija na drugi, pogodniji za skladištenje, prenos ili obradu.
Računar može obraditi tekstualne informacije. Kada se unese u kompjuter, svako slovo je kodirano određenim brojem, a kada se iznese na eksterne uređaje (ekran ili print), za ljudsku percepciju, slike slova se grade pomoću ovih brojeva. Korespondencija između skupa slova i brojeva naziva se kodiranjem znakova.
Po pravilu, svi brojevi u računaru su predstavljeni pomoću nula i jedinica (a ne deset cifara, kao što je uobičajeno za ljude). Drugim riječima, računari obično rade u binarnom sistemu, jer su uređaji za njihovu obradu mnogo jednostavniji. Unošenje brojeva u računar i njihovo ispisivanje za ljudsko čitanje može se obaviti u uobičajenom decimalnom obliku, a sve potrebne konverzije izvode programi koji rade na računaru.
III.
Kodiranje tekstualnih informacija
Ista informacija se može predstaviti (kodirati) u nekoliko oblika. Pojavom kompjutera postalo je neophodno kodirati sve vrste informacija sa kojima se suočavaju i pojedinac i čovječanstvo u cjelini. Ali čovječanstvo je počelo rješavati problem kodiranja informacija mnogo prije pojave kompjutera. Grandiozna dostignuća čovječanstva - pisanje i aritmetika - nisu ništa drugo do sistem kodiranja govora i numeričke informacije. Informacije se nikada ne pojavljuju čista forma, uvijek je nekako predstavljen, nekako kodiran.
Binarno kodiranje je jedan od najčešćih načina predstavljanja informacija. U računalima, robotima i alatnim strojevima s numeričkom kontrolom, po pravilu, sve informacije s kojima se uređaj bavi kodirane su u obliku riječi binarnog alfabeta.
Od kasnih 1960-ih, kompjuteri se sve više koriste za obradu teksta, a sada većina svjetskih personalnih računara (i večina vrijeme) je zauzet obradom tekstualnih informacija. Sve ove vrste informacija u računaru su predstavljene u binarnom kodu, odnosno koristi se abeceda sa stepenom dva (samo dva znaka 0 i 1). To je zbog činjenice da je zgodno predstaviti informacije u obliku niza električnih impulsa: nema impulsa (0), postoji impuls (1).
Takvo kodiranje se obično naziva binarnim, a sami logički nizovi nula i jedinica nazivaju se mašinskim jezikom.
Sa stanovišta računara, tekst se sastoji od pojedinačnih znakova. Znakovi ne uključuju samo slova (velika ili mala, latinična ili ruska), već i brojeve, znakove interpunkcije, specijalne znakove poput "=", "(", "&", itd., pa čak (obratite posebnu pažnju!) razmake između riječi. .
Tekstovi se unose u memoriju računara pomoću tastature. Tasteri su ispisani poznatim slovima, brojevima, interpunkcijskim znacima i drugim simbolima. Oni ulaze u RAM u binarnom kodu. To znači da je svaki znak predstavljen 8-bitnim binarnim kodom.
Tradicionalno, za kodiranje jednog znaka koristi se količina informacija jednaka 1 bajtu, tj. I = 1 bajt = 8 bita. Koristeći formulu koja povezuje broj mogućih događaja K i količinu informacija I, možete izračunati koliko različitih znakova može biti kodirano (pod pretpostavkom da su znakovi mogući događaji): K \u003d 2 I
= 2 8
= 256, tj. abeceda kapaciteta 256 znakova može se koristiti za predstavljanje tekstualnih informacija.
Ovaj broj znakova sasvim je dovoljan za predstavljanje tekstualnih informacija, uključujući velika i mala slova ruske i latinične abecede, brojeve, znakove, grafičke simbole itd.
Kodiranje je da se svakom karakteru dodijeli jedinstven decimalni kod od 0 do 255 ili odgovarajući binarni kod od 00000000 do 11111111. Dakle, osoba razlikuje likove po stilu, a kompjuter po kodu.
Pogodnost bajt-po-bajt kodiranja znakova je očigledna, budući da je bajt najmanji adresabilni dio memorije i stoga procesor može pristupiti svakom karakteru posebno kada obavlja obradu teksta. S druge strane, 256 znakova je sasvim dovoljno za predstavljanje širokog spektra informacija o znakovima.
U procesu prikazivanja znaka na ekranu računara vrši se obrnuti proces - dekodiranje, odnosno pretvaranje koda znaka u njegovu sliku. Važno je da je dodjela specifičnog koda simbolu stvar dogovora, što je fiksirano u tablici kodova.
Sada se postavlja pitanje koji osmobitni binarni kod staviti u korespondenciju sa svakim karakterom. Jasno je da je ovo uslovna stvar, možete smisliti mnogo načina za kodiranje.
Svi znakovi kompjuterske abecede su numerisani od 0 do 255. Svaki broj odgovara osmobitnom binarnom kodu od 00000000 do 11111111. Ovaj kod je jednostavno redni broj znaka u binarnom brojevnom sistemu.
IV
. Vrste tablica kodiranja
Tabela u kojoj su svim znakovima kompjuterske abecede dodijeljeni serijski brojevi naziva se tabela kodiranja.
Za različite vrste Računar koristi različite tablice kodiranja.
ASCII (American Standard Code for Information Interchange) tablica kodova je usvojena kao međunarodni standard, kodiranje prve polovine znakova numeričkim kodovima od 0 do 127 (kodovi od 0 do 32 nisu dodijeljeni znakovima, već funkcijskim tipkama).
Tabela ASCII kodova podijeljena je na dva dijela.
Samo prva polovina tabele je međunarodni standard, tj. znakova sa brojevima od 0 (00000000) do 127 (01111111).
Struktura ASCII tablice kodiranja
| Serijski broj | Kod | Simbol |
| 0 - 31 | 00000000 - 00011111 | Znakovi sa brojevima od 0 do 31 nazivaju se kontrolni znakovi. Njihova funkcija je kontrola procesa prikazivanja teksta na ekranu ili štampanja, davanja zvučnog signala, označavanja teksta itd. |
| 32 - 127 | 0100000 - 01111111 | Standardni dio tabele (engleski). Ovo uključuje mala i velika slova latinice, decimalne cifre, znakove interpunkcije, sve vrste zagrada, komercijalne i druge simbole. Znak 32 je razmak, tj. prazna pozicija u tekstu. Sve ostalo odražavaju se određenim znacima. |
| 128 - 255 | 10000000 - 11111111 | Alternativni dio tabele (ruski). Druga polovina tabele kodova ASCII, nazvana kodna stranica (128 kodova, počevši sa 10000000 i završavajući sa 11111111), može imati različite opcije, svaka opcija ima svoj broj. Kodna stranica se prvenstveno koristi za smještaj nacionalnih pisama osim latinice. U ruskim nacionalnim kodovima, znakovi ruskog alfabeta nalaze se u ovom dijelu tabele. |
Prva polovina tabele ASCII kodova
Skreće se pažnja na činjenicu da su u tablici kodiranja slova (velika i mala) raspoređena abecednim redom, a brojevi rastućim redoslijedom. Ovo poštovanje leksikografskog reda u rasporedu znakova naziva se princip sekvencijalnog kodiranja abecede.
Za slova ruske abecede također se poštuje princip sekvencijalnog kodiranja.
Druga polovina tabele ASCII kodova
Nažalost, trenutno postoji pet različitih ćiriličkih kodiranja (KOI8-R, Windows. MS-DOS, Macintosh i ISO). Zbog toga često nastaju problemi sa prenosom ruskog teksta sa jednog računara na drugi, iz jednog softverskog sistema u drugi.
Hronološki, jedan od prvih standarda za kodiranje ruskih slova na računarima bio je KOI8 („Kod za razmenu informacija, 8-bitni“). Ovo kodiranje je korišćeno još 70-ih godina na računarima serije računara EC, a od sredine 80-ih počelo je da se koristi u prvim rusifikovanim verzijama UNIX operativnog sistema.
Od početka 90-ih, vremena dominacije operativnog sistema MS DOS, kodiranje ostaje CP866 („CP“ znači „Code Page“, „code page“).
Apple računari koji koriste Mac OS operativni sistem koriste vlastito Mac kodiranje.
Pored toga, Međunarodna organizacija za standardizaciju (International Standards Organization, ISO) odobrila je još jedno kodiranje pod nazivom ISO 8859-5 kao standard za ruski jezik.
Najčešći kodiranje koje se trenutno koristi je Microsoft Windows, skraćeno CP1251. Uveo Microsoft; uzimajući u obzir rasprostranjena operativnim sistemima (OS) i drugim softverskim proizvodima ove kompanije u Ruska Federacija postalo je široko rasprostranjeno.
Od kasnih 90-ih, problem standardizacije kodiranja znakova riješen je uvođenjem novog međunarodnog standarda pod nazivom Unicode.
Ovo je 16-bitno kodiranje, tj. ima 2 bajta memorije po karakteru. Naravno, u ovom slučaju, količina zauzete memorije se povećava za 2 puta. Ali takva kodna tabela omogućava uključivanje do 65536 znakova. Kompletna specifikacija Unicode standarda uključuje sve postojeće, izumrle i umjetno stvorene alfabete svijeta, kao i mnoge matematičke, muzičke, hemijske i druge simbole.
Interno predstavljanje riječi u memoriji računara
koristeći ASCII tablicu
Ponekad se dešava da se tekst, koji se sastoji od slova ruske abecede, primljen sa drugog računara, ne može pročitati - na ekranu monitora je vidljiva neka vrsta "abrakadabre". To je zbog činjenice da računari koriste različita kodiranja znakova ruskog jezika.
Dakle, svako kodiranje je specificirano svojom vlastitom tablicom kodova. Kao što se vidi iz tabele, istom binarnom kodu se dodeljuju različiti znakovi u različitim kodovima.
Na primjer, niz numeričkih kodova 221, 194, 204 u CP1251 kodiranju formira riječ "kompjuter", dok će u drugim kodovima to biti besmislen skup znakova.
Na sreću, u većini slučajeva korisnik ne mora da brine o transkodiranju tekstualnih dokumenata, jer se to radi pomoću posebnih programa konvertera ugrađenih u aplikacije.
V
. Proračun količine tekstualnih informacija
Zadatak 1:
Kodirajte riječ "Rim" pomoću tablica kodiranja KOI8-R i CP1251.
Rješenje:
Zadatak 2:
Uz pretpostavku da je svaki znak kodiran jednim bajtom, procijenite količinu informacija sljedeće rečenice:
“Moj ujak najpoštenijih pravila,
Kad sam se ozbiljno razbolio,
Natjerao je sebe da poštuje
I nisam mogao smisliti bolji."
Rješenje:
U ovoj frazi ima 108 znakova, uključujući znakove interpunkcije, navodnike i razmake. Ovaj broj množimo sa 8 bita. Dobijamo 108*8=864 bita.
Zadatak 3:
Dva teksta sadrže isti broj znakova. Prvi tekst je napisan na ruskom, a drugi na jeziku plemena Naguri, čija se abeceda sastoji od 16 znakova. Čiji tekst nosi više informacija?
Rješenje:
1) I \u003d K * a (obim informacija teksta jednak je proizvodu broja znakova i težine informacija jednog znaka).
2) Jer oba teksta imaju isti broj znakova (K), tada razlika zavisi od informativnog sadržaja jednog znaka abecede (a).
3) 2 a1
= 32, tj. a 1
= 5 bita, 2 a2
= 16, tj. a 2
= 4 bita.
4) I 1
= K * 5 bita, I 2
= K * 4 bita.
5) To znači da tekst napisan na ruskom jeziku nosi 5/4 puta više informacija.
Zadatak 4:
Obim poruke, koja je sadržavala 2048 karaktera, iznosila je 1/512 MB. Odredite snagu abecede.
Rješenje:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bita - količina informacija poruke je pretvorena u bitove.
2) \u003d I / K \u003d 16384 / 1024 \u003d 16 bita - pada na jedan znak abecede.
3) 2*16*2048 = 65536 znakova - snaga korišćene abecede.
Zadatak 5:
Canon LBP laserski štampač štampa prosečnom brzinom od 6,3 Kbps. Koliko će vremena biti potrebno za štampanje dokumenta od 8 stranica ako se zna da na jednoj stranici ima u prosjeku 45 redova, 70 znakova po redu (1 karakter - 1 bajt)?
Rješenje:
1) Pronađite količinu informacija sadržanih na 1 stranici: 45 * 70 * 8 bita = 25200 bita
2) Pronađite količinu informacija na 8 stranica: 25200 * 8 = 201600 bita
3) Dovodimo do uniformnih mjernih jedinica. Da bismo to učinili, prevodimo Mbps u bitove: 6,3 * 1024 = 6451,2 bps.
4) Pronađite vrijeme ispisa: 201600: 6451,2 = 31 sekunda.
Bibliografija
1. Ageev V.M. Teorija informacija i kodiranja: diskretizacija i kodiranje mjernih informacija. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Osnove teorije informacija i kodiranja. - Kijev, škola Vishcha, 1986.
3. Najjednostavniji načini šifriranja teksta / D.M. Zlatopolsky. - M.: Chistye Prudy, 2007 - 32 str.
4. Ugrinovich N.D. Informatika i informacione tehnologije. Udžbenik za 10-11 razred / N.D. Ugrinovich. – M.: BINOM. Laboratorij znanja, 2003. - 512 str.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n