Koliko informacija kodira dva moguća stanja. Šta je kodiranje i dekodiranje? Primjeri. Metode za kodiranje i dekodiranje informacija numeričkih, tekstualnih i grafičkih
U informatici se veliki broj informacionih procesa odvija upotrebom kodiranje podataka. Stoga je razumijevanje ovog procesa veoma važno za razumijevanje osnova ove nauke. Pod kodiranjem informacija podrazumijeva se proces pretvaranja znakova napisanih na različitim prirodnim jezicima (ruski, engleski jezik itd.) u numeričku oznaku.

To znači da se prilikom kodiranja teksta svakom znaku dodjeljuje određena vrijednost u obliku nula i jedinica - .
Zašto kodirati informacije?
Prvo, morate odgovoriti na pitanje zašto kodirati informacije? Činjenica je da je kompjuter sposoban da obrađuje i pohranjuje samo jednu vrstu predstavljanja podataka - digitalnu. Stoga, sve informacije uključene u njega moraju biti prevedene digitalni pogled.
Standardi kodiranja teksta
Da bi svi računari nedvosmisleno razumeli određeni tekst, potrebno je koristiti opšteprihvaćeni standardi za kodiranje teksta. U drugim slučajevima će biti potrebno dodatno kodiranje ili nekompatibilnost podataka.
ASCII
Prvi standard za kodiranje kompjuterskih znakova bio je ASCII (pun naziv - američki standardni kod za razmjenu informacija). Samo 7 bitova je korišteno za kodiranje bilo kojeg znaka u njemu. Kao što se sjećate, samo 27 znakova ili 128 znakova može se kodirati pomoću 7 bita. Ovo je dovoljno za kodiranje velikih i malih slova latinične abecede, arapskih brojeva, znakova interpunkcije, kao i određenog skupa posebnih znakova, na primjer, znaka dolara - "$". Međutim, da bi se kodirali simboli abecede drugih naroda (uključujući i simbole ruskog alfabeta), kod je morao biti dopunjen na 8 bita (28=256 simbola). Istovremeno, za svaki jezik korišteno je posebno kodiranje.
UNICODE
Bilo je potrebno spasiti situaciju u smislu kompatibilnosti tablice kodiranja. Stoga su vremenom razvijeni novi ažurirani standardi. Trenutno je najpopularnije kodiranje tzv UNICODE. U njemu je svaki znak kodiran pomoću 2 bajta, što odgovara 216=62536 različitih kodova.
Standardi grafičkog kodiranja
Za kodiranje slike potrebno je mnogo više bajtova nego za kodiranje znakova. Većina kreiranih i obrađenih slika pohranjenih u memoriji računara podijeljena je u dvije glavne grupe:
- Rasterske grafičke slike;
- vektorske grafičke slike.
Rasterska grafika
U rasterskoj grafici, slika je predstavljena skupom obojenih tačaka. Takve tačke se nazivaju pikseli. Kada se slika uveća, takve tačke se pretvaraju u kvadrate.
Za kodiranje crno-bijele slike, svaki piksel je kodiran jednim bitom. Na primjer, crna je 0, a bijela 1)
Naša prošla slika se može kodirati ovako:
Kod kodiranja slika koje nisu u boji najčešće se koristi paleta od 256 nijansi sive, u rasponu od bijele do crne. Stoga je jedan bajt (28=256) dovoljan za kodiranje takve gradacije.
U kodiranju slika u boji koristi se nekoliko shema boja.
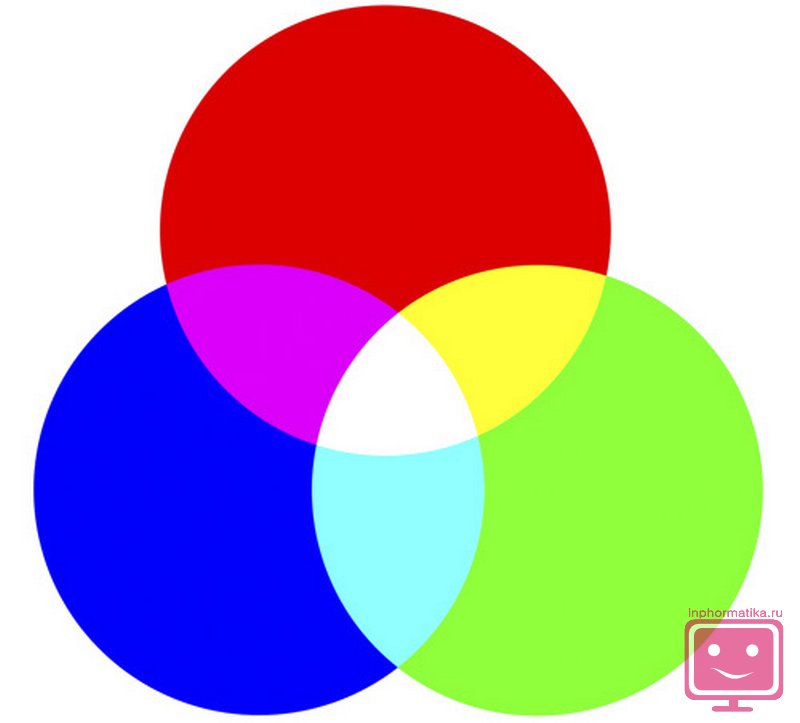
U praksi, češće RGB model boja, gdje se koriste tri osnovne boje: crvena, zelena i plava. Preostale nijanse se dobijaju mešanjem ovih primarnih boja.
Dakle, za kodiranje modela iz tri boje u 256 tonova dobija se preko 16,5 miliona različitih nijansi boja. Odnosno, 3⋅8=24 bita se koristi za kodiranje, što odgovara 3 bajta.
Naravno, možete koristiti minimalni iznos bit za kodiranje slika u boji, ali tada se može formirati manji broj tonova boja, zbog čega će se kvalitet slike značajno smanjiti.
Da biste odredili veličinu slike, potrebno je da pomnožite broj piksela u širini sa dužinom broja piksela i ponovo pomnožite sa veličinom samog piksela u bajtovima.
- A- broj piksela širine;
- b- broj piksela u dužini;
- I– veličina jednog piksela u bajtovima.
Na primjer, slika u boji od 800⋅600 piksela je 60.000 bajtova.
Vektorska grafika
Vektorski grafički objekti su kodirani na potpuno drugačiji način. Ovdje se slika sastoji od linija, koje mogu imati svoje koeficijente zakrivljenosti.

Standardi audio kodiranja
Zvukovi koje osoba čuje su vibracije zraka. Zvučne vibracije su proces širenja talasa.
Zvuk ima dvije glavne karakteristike:
- amplituda oscilacije - određuje jačinu zvuka;
- frekvencija oscilacije - određuje ton zvuka.
Zvuk se pomoću mikrofona može pretvoriti u električni signal. Zvuk je kodiran sa određenim, unaprijed određenim vremenskim intervalom. U tom slučaju se mjeri veličina električnog signala i dodjeljuje se binarna vrijednost. Što se ova mjerenja češće vrše, to je kvalitet zvuka veći.

CD od 700 MB sadrži oko 80 minuta zvuka CD kvaliteta.
Standardi video kodiranja
Kao što znate, video sekvenca se sastoji od fragmenata koji se brzo mijenjaju. Kadrovi se mijenjaju brzinom u rasponu od 24-60 sličica u sekundi.
Veličina snimka u bajtovima određena je veličinom okvira (broj piksela po ekranu po visini i širini), brojem korištenih boja i brojem kadrova u sekundi. Ali uz ovo može postojati i audio zapis.
Upoznali smo se sa brojevnim sistemima – načinima kodiranja brojeva. Brojevi daju informaciju o broju stavki. Ove informacije moraju biti kodirane, predstavljene u nekom brojevnom sistemu. Koju od poznatih metoda izabrati zavisi od problema koji se rešava.
Računari su donedavno uglavnom obrađivali numeričke i tekstualne informacije. Ali većinu informacija o vanjskom svijetu osoba prima u obliku slika i zvukova. U ovom slučaju, slika je važnija. Zapamtite poslovicu: „Bolje je jednom vidjeti nego sto puta čuti“. Stoga danas računari počinju sve aktivnije raditi sa slikom i zvukom. Mi ćemo nužno razmotriti načine kodiranja takvih informacija.
Binarno kodiranje numeričko i tekstualne informacije.
Bilo koja informacija je kodirana u računaru pomoću sekvenci od dvije cifre - 0 i 1. Računar pohranjuje i obrađuje informacije u obliku kombinacije električnih signala: napon od 0,4V-0,6V odgovara logičkoj nuli, a napon od 2.4V-2.7V odgovara logičkoj jedinici. Pozivaju se sekvence od 0 i 1 binarni kodovi
, a brojevi 0 i 1 - bits
(binarne cifre). Ovo kodiranje informacija na računaru se zove binarno kodiranje
. Dakle, binarno kodiranje je kodiranje sa najmanjim mogućim brojem elementarnih znakova, kodiranje na najjednostavniji način. To je ono što ga čini izuzetnim sa teorijske tačke gledišta.
Inženjere privlači binarno kodiranje informacija činjenicom da ga je tehnički lako implementirati. Elektronska kola za obradu binarnih kodova mora biti samo u jednom od dva stanja: postoji signal / nema signala
ili visoki napon/niski napon
.
Računari u svom radu rade sa realnim i cijelim brojevima, predstavljenim kao dva, četiri, osam pa čak i deset bajtova. Dodatni simbol se koristi za predstavljanje predznaka broja prilikom brojanja. sign bit
, koji se obično stavlja ispred brojčanih cifara. Za pozitivne brojeve, vrijednost bita predznaka je 0, a za negativne brojeve je 1. Da biste napisali internu reprezentaciju negativnog cijelog broja (-N), morate:
1) dobiti dodatni kod broja N zamenom 0 sa 1 i 1 sa 0;
2) rezultirajućem broju dodati 1.
Pošto jedan bajt nije dovoljan za predstavljanje ovog broja, on je predstavljen kao 2 bajta ili 16 bita, njegov komplementarni kod je 1111101111000101, dakle -1082=1111101111000110.
Kada bi računar mogao da rukuje samo jednim bajtovima, to bi bilo od male koristi. U stvarnosti, PC radi sa brojevima koji su napisani u dva, četiri, osam, pa čak i deset bajtova.
Od kasnih 60-ih, kompjuteri se sve više koriste za obradu tekstualnih informacija. Za predstavljanje tekstualnih informacija obično se koristi 256 različitih znakova, na primjer, velika i mala slova latinice, brojevi, znakovi interpunkcije itd. U većini modernih računara, svaki znak odgovara nizu od osam nula i jedinica, tzv bajt
.
Bajt je osmobitna kombinacija nula i jedinica.
Prilikom kodiranja informacija u ovim elektronskim računarima koristi se 256 različitih sekvenci od 8 nula i jedinica, što omogućava kodiranje 256 karaktera. Na primjer, veliko rusko slovo "M" ima šifru 11101101, slovo "I" - šifru 11101001, slovo "R" - šifru 11110010. Dakle, riječ "MIR" je kodirana nizom od 24 bita ili 3 bajta: 111011011110100111110010.
Broj bitova u poruci naziva se veličina informacije poruke.
Ovo je zanimljivo!
U početku se u kompjuterima koristila samo latinica. Ima 26 slova. Dakle, pet impulsa (bitova) bi bilo dovoljno za označavanje svakog. Ali tekst sadrži znakove interpunkcije, decimalne cifre itd. Stoga je u prvim kompjuterima na engleskom jeziku bajt - mašinski slog - uključivao šest bitova. Zatim sedam - ne samo za razlikovanje velikih slova od malih, već i za povećanje broja kontrolnih kodova za štampače, signalna svjetla i drugu opremu. Godine 1964. pojavio se moćni IBM-360, u kojem je bajt konačno postao jednak osam bita. Posljednji osmi bit je bio potreban za pseudografske znakove.
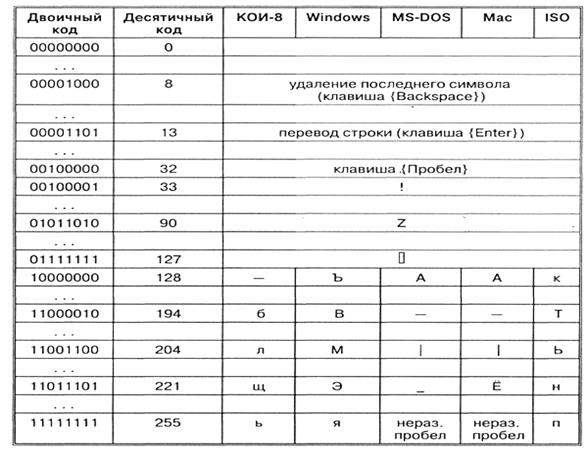
Dodjeljivanje određenog binarnog koda simbolu je stvar dogovora, što je fiksirano u tablici kodova. Nažalost, postoji pet različitih kodiranja ruskih slova, tako da se tekstovi kreirani u jednom kodiranju neće ispravno odražavati u drugom.
Hronološki, jedan od prvih standarda za kodiranje ruskih slova na računarima bio je KOI8 („Kod za razmenu informacija, 8 bita“). Najčešći kodiranje je standardno Microsoft Windows ćirilično kodiranje, skraćeno kao SR1251 („SR“ je skraćenica za „Code Page“ ili „code page“). Apple je razvio vlastito kodiranje ruskih slova (Mac) za Macintosh računare. Međunarodna organizacija za standardizaciju (ISO) je odobrila ISO 8859-5 kodiranje kao standard za ruski jezik. Konačno se pojavio novi međunarodni Unicode standard, koji svakom karakteru dodjeljuje ne jedan bajt, već dva, pa se može koristiti za kodiranje ne 256 znakova, već čak 65536.
Sva ova kodiranja su nastavak ASCII (American Standard Code for Information Interchange) tablice kodova, koja kodira 128 znakova.
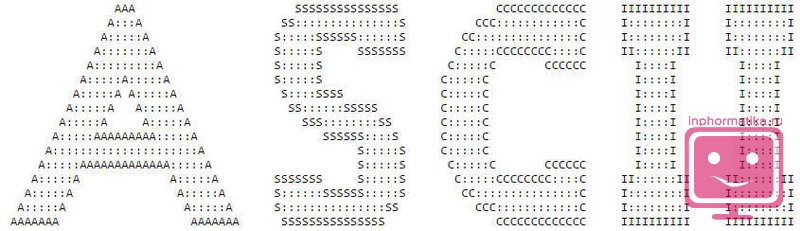
ASCII tabela znakova:
| kod | simbol | kod | simbol | kod | simbol | kod | simbol | kod | simbol | kod | simbol |
| 32 | Prostor | 48 | . | 64 | @ | 80 | P | 96 | " | 112 | str |
| 33 | ! | 49 | 0 | 65 | A | 81 | Q | 97 | a | 113 | q |
| 34 | " | 50 | 1 | 66 | B | 82 | R | 98 | b | 114 | r |
| 35 | # | 51 | 2 | 67 | C | 83 | S | 99 | c | 115 | s |
| 36 | $ | 52 | 3 | 68 | D | 84 | T | 100 | d | 116 | t |
| 37 | % | 53 | 4 | 69 | E | 85 | U | 101 | e | 117 | u |
| 38 | & | 54 | 5 | 70 | F | 86 | V | 102 | f | 118 | v |
| 39 | " | 55 | 6 | 71 | G | 87 | W | 103 | g | 119 | w |
| 40 | ( | 56 | 7 | 72 | H | 88 | X | 104 | h | 120 | x |
| 41 | ) | 57 | 8 | 73 | I | 89 | Y | 105 | i | 121 | y |
| 42 | * | 58 | 9 | 74 | J | 90 | Z | 106 | j | 122 | z |
| 43 | + | 59 | : | 75 | K | 91 | [ | 107 | k | 123 | { |
| 44 | , | 60 | ; | 76 | L | 92 | \ | 108 | l | 124 | | |
| 45 | - | 61 | < | 77 | M | 93 | ] | 109 | m | 125 | } |
| 46 | . | 62 | > | 78 | N | 94 | ^ | 110 | n | 126 | ~ |
| 47 | / | 63 | ? | 79 | O | 95 | _ | 111 | o | 127 | DEL |
Binarno kodiranje teksta se dešava na sledeći način: kada se pritisne taster, određeni niz električnih impulsa se prenosi na računar, a svaki znak ima svoj niz električnih impulsa (nule i jedinice u mašinskom jeziku). Program tastature i drajvera ekrana određuje simbol iz tabele kodova i kreira njegovu sliku na ekranu. Tako se tekstovi i brojevi pohranjuju u memoriju računara u binarnom kodu i programski se pretvaraju u slike na ekranu.
Binarno kodiranje grafičke informacije.Od 80-ih godina, tehnologija obrade grafičkih informacija na računaru ubrzano se razvija. Kompjuterska grafika se široko koristi u kompjuterskim simulacijama u naučnim istraživanjima, kompjuterskim simulatorima, kompjuterskoj animaciji, poslovnoj grafiki, igrama itd.
Grafičke informacije na ekranu prikazane su u obliku slike, koja se formira od tačaka (piksela). Pogledajte pažljivo novinsku fotografiju i vidjet ćete da se i ona sastoji od sitne tačke. Ako su to samo crne i bijele tačke, onda se svaka od njih može kodirati sa 1 bit. Ali ako na fotografiji postoje nijanse, tada vam dva bita omogućavaju kodiranje 4 nijanse tačaka: 00 - Bijela boja, 01 - svijetlo siva, 10 - tamno siva, 11 - crna. Tri bita vam omogućavaju da kodirate 8 nijansi, itd.
Broj bitova potrebnih za kodiranje jedne nijanse boje naziva se dubina boje.
U savremenim računarima rezoluciju
(broj tačaka na ekranu), kao i broj boja zavisi od video adaptera i može se programski promeniti.
Slike u boji mogu imati različite modove: 16 boja, 256 boja, 65536 boja ( visoka boja), 16777216 boja ( prava boja). Jedan bod za mod visoka boja Potrebno je 16 bita ili 2 bajta.
Najčešća rezolucija ekrana je 800 x 600 piksela, tj. 480000 bodova. Izračunajmo količinu video memorije potrebne za režim visoke boje: 2 bajta *480000=960000 bajtova.
Veće jedinice se također koriste za mjerenje količine informacija:
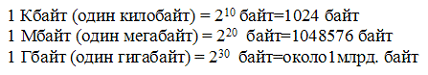
Dakle, 960000 bajtova je približno jednako 937,5 KB. Ako osoba priča osam sati dnevno bez pauze, onda će za 70 godina života reći oko 10 gigabajta informacija (to je 5 miliona stranica - hrpa papira visoka 500 metara).
Brzina prijenosa informacija je broj bitova koji se prenose u 1 sekundi. Brzina prijenosa od 1 bita u sekundi naziva se 1 baud.
Video memorija računara pohranjuje bitmapu, koja je binarni kod slike, odakle je čita procesor (najmanje 50 puta u sekundi) i prikazuje na ekranu.
Binarno kodiranje zvučnih informacija.
Od početka 90-ih, personalni računari su mogli da rade sa zvučnim informacijama. Svaki računar sa zvučnom karticom može sačuvati kao fajlove ( datoteka je određena količina informacija pohranjena na disku i ima ime
) i reprodukujte audio informacije. Uz pomoć posebnih softverskih alata (uređivača audio datoteka) otvaraju se velike mogućnosti za kreiranje, uređivanje i slušanje zvučnih datoteka. Kreiraju se programi za prepoznavanje govora i postaje moguće upravljati računarom glasom.
To je zvučna kartica (kartica) koja pretvara analogni signal u diskretni fonogram i obrnuto, "digitalizovani" zvuk u analogni (kontinuirani) signal koji se dovodi na ulaz zvučnika.

Kod binarnog kodiranja analognog audio signala uzorkuje se kontinuirani signal, tj. je zamijenjen nizom njegovih pojedinačnih uzoraka - očitavanja. Kvaliteta binarno kodiranje zavisi od dva parametra: broja diskretnih nivoa signala i broja uzoraka u sekundi. Broj uzoraka ili brzina uzorkovanja u audio adapterima varira: 11 kHz, 22 kHz, 44,1 kHz, itd. Ako je broj nivoa 65536, tada se za jedan audio signal izračunava 16 bita (216). 16-bitni audio adapter kodira i reprodukuje zvuk preciznije od 8-bitnog.
Broj bitova potrebnih za kodiranje jednog nivoa zvuka naziva se audio dubina.
Jačina zvuka mono audio datoteke (u bajtovima) određena je formulom:

Sa stereofonskim zvukom, jačina audio datoteke se udvostručuje, sa kvadrafonskim zvukom, učetvorostručena.
Kako programi postaju složeniji i njihove funkcije se povećavaju, kao i pojava multimedijalnih aplikacija, raste i funkcionalni volumen programa i podataka. Ako je sredinom 80-ih uobičajeni volumen programa i podataka bio desetine, a samo ponekad stotine kilobajta, onda je sredinom 90-ih počeo iznositi desetine megabajta. Shodno tome, količina RAM-a se povećava.
Rad elektronskih računara za obradu podataka postao je važan korak u procesu unapređenja sistema upravljanja i planiranja. Ali ovaj način prikupljanja i obrade informacija je nešto drugačiji od uobičajenog, stoga zahtijeva transformaciju u sistem simbola razumljiv kompjuteru.
Šta je kodiranje informacija?
Kodiranje podataka je obavezan korak u procesu prikupljanja i obrade informacija.
Kod po pravilu se podrazumijeva kombinacija znakova koja odgovara prenesenim podacima ili nekim njihovim kvalitativnim karakteristikama. A kodiranje je proces sastavljanja šifrirane kombinacije u obliku liste skraćenica ili posebnih znakova koji u potpunosti prenose izvorno značenje poruke. Šifriranje se ponekad naziva i šifriranjem, ali vrijedi znati da potonji postupak uključuje zaštitu podataka od hakovanja i čitanja trećih strana.
Svrha kodiranja je predstavljanje informacija u prikladnom i sažetom formatu kako bi se olakšao njihov prijenos i obrada na računarskim uređajima. Računari rade samo na određenim oblicima informacija, pa je važno to imati na umu kako biste izbjegli probleme. Koncept obrade podataka uključuje pretraživanje, sortiranje i sređivanje, a kodiranje se u njemu događa u fazi unosa informacije u obliku koda.
Šta je dekodiranje informacija?
Pitanje šta je kodiranje i dekodiranje može se pojaviti kod korisnika PC-ja iz različitih razloga, ali u svakom slučaju važno je prenijeti ispravne informacije koje će korisniku omogućiti da uspješno krene naprijed u toku informacione tehnologije. Kao što razumijete, nakon procesa obrade podataka, dobiva se izlazni kod. Ako se takav fragment dešifrira, tada se formira originalna informacija. To jest, dekodiranje je proces obrnut od šifriranja. 
Ako tokom kodiranja podaci poprime oblik simboličkih signala koji u potpunosti odgovaraju prenesenom objektu, tada se tokom dekodiranja prenesena informacija ili neke njene karakteristike uklanjaju iz koda.
Može postojati nekoliko primalaca kodiranih poruka, ali je vrlo važno da informacije dođu u njihove ruke i da ih treća lica prethodno ne otkriju. Stoga je vrijedno proučavati procese kodiranja i dekodiranja informacija. Oni pomažu u razmjeni povjerljivih informacija između grupe sagovornika.
Kodiranje i dekodiranje tekstualnih informacija
Kada pritisnete taster na tastaturi, računar prima signal u obliku binarni broj, čije se dekodiranje može pronaći u tablici kodova - interni prikaz znakova u PC-u. ASCII tabela se smatra svjetskim standardom. 
Međutim, nije dovoljno znati šta su kodiranje i dekodiranje, potrebno je i razumjeti kako se podaci nalaze u računaru. Na primjer, da bi pohranio jedan simbol binarnog koda, elektronički računar dodjeljuje 1 bajt, odnosno 8 bitova. Ova ćelija može imati samo dvije vrijednosti: 0 i 1. Ispostavilo se da vam jedan bajt omogućava šifriranje 256 različitih znakova, jer je to broj kombinacija koje se mogu napraviti. Ove kombinacije su ključ ASCII tabele. Na primjer, slovo S je kodirano kao 01010011. Kada ga pritisnete na tastaturi, podaci se kodiraju i dekodiraju, a na ekranu dobijamo očekivani rezultat.
Polovina tabele ASCII standarda sadrži kodove za cifre, kontrolne znakove i latinična slova. Drugi dio je ispunjen nacionalnim znakovima, pseudografskim znakovima i simbolima koji nisu vezani za matematiku. Jasno je da će se u različitim zemljama ovaj dio tabele razlikovati. Cifre se takođe konvertuju u binarni način kako se unose, prema standardnom sažetku. 
Kodiranje brojeva
Sličan metod kodiranja tačaka slike se takođe koristi u štamparskoj industriji. Samo ovdje je uobičajeno koristiti četvrtu boju - crnu. Iz tog razloga, sistem konverzijskog štampanja je skraćeno CMYK. Ovaj sistem koristi čak trideset dva bita za predstavljanje slika.

Metode za kodiranje i dekodiranje informacija uključuju korištenje različitih tehnologija, ovisno o vrsti ulaznih podataka. Na primjer, metoda šifriranja grafičkih slika sa šesnaest-bitnim binarnim kodovima naziva se High Color. Ova tehnologija omogućava prenošenje čak dvjesto pedeset i šest nijansi na ekran. Smanjenjem broja uključenih bitova koji se koriste za šifriranje tačaka grafička slika, automatski smanjujete količinu prostora potrebnog za privremeno skladištenje informacija. Ova metoda kodiranja podataka naziva se indeks.
Audio kodiranje
Sada kada smo pogledali šta su kodiranje i dekodiranje, i metode koje su u osnovi ovog procesa, vrijedi se zadržati na takvom pitanju kao što je kodiranje audio podataka.
Zvučne informacije mogu biti predstavljene kao elementarne jedinice i pauze između svakog od njihovih para. Svaki signal se konvertuje i pohranjuje u memoriju računara. Zvukovi se emituju korišćenjem šifrovanih kombinacija pohranjenih u memoriji računara.
Što se tiče ljudskog govora, mnogo ga je teže kodirati, jer ima niz nijansi, a kompjuter mora svaku frazu uporediti sa standardom koji mu je prethodno ušao u memoriju. Prepoznavanje će se dogoditi samo kada se izgovorena riječ nađe u rječniku.
Kodiranje informacija u binarnom kodu
Postoje različite metode za implementaciju takve procedure kao što je kodiranje numeričkih, tekstualnih i grafičkih informacija. Dekodiranje podataka se obično odvija u obrnutoj tehnologiji.
Prilikom kodiranja brojeva uzima se u obzir čak i svrha zbog koje je broj unesen u sistem: za aritmetička izračunavanja ili jednostavno za izlaz. Svi podaci kodirani u binarnom sistemu su šifrirani pomoću jedinica i nula. Ovi znakovi se također nazivaju bitovima. Ova metoda kodiranja je najpopularnija, jer ju je najlakše organizirati u smislu tehnologije: prisutnost signala je 1, odsustvo je 0. Binarno šifriranje ima samo jedan nedostatak - ovo je dužina kombinacija znakova. Ali sa tehničke tačke gledišta, lakše je upravljati gomilom jednostavnih, uniformnih komponenti nego malim brojem složenijih.
Prednosti binarnog kodiranja
- Ovo je pogodno za razne vrste.
- Prilikom prijenosa podataka nema grešaka.
- Za PC je mnogo lakše obraditi podatke koji su kodirani na ovaj način.
- Zahtijeva uređaje sa dvostrukim stanjem.
Nedostaci binarnog kodiranja
- Velika dužina kodova, što donekle usporava njihovu obradu.
- Složenost percepcije binarnih kombinacija od strane osobe bez posebnog obrazovanja ili obuke.

Zaključak
Nakon što ste pročitali ovaj članak, mogli ste saznati što je kodiranje i dekodiranje i za što se koristi. Može se zaključiti da korištene tehnike konverzije podataka u potpunosti zavise od vrste informacije. To može biti ne samo tekst, već i brojevi, slike i zvuk.
Kodiranje različitih informacija omogućava vam da objedinite formu njihove prezentacije, odnosno učinite je istom vrstom, što značajno ubrzava obradu i automatizaciju podataka za dalju upotrebu.
U elektronskim računarima najčešće se koriste principi standardnog binarnog kodiranja, koje pretvara izvorni oblik predstavljanja informacija u format koji je pogodniji za skladištenje i dalju obradu. Prilikom dekodiranja svi se procesi odvijaju obrnutim redoslijedom.
Sadržaj
I. Istorija kodiranja informacija……………………………………………..3
II. Informacije o kodiranju…………………………………………4
III. Kodiranje tekstualnih informacija……………………………….4
IV. Vrste tablica kodiranja…………………………………………………………...6
V. Proračun količine tekstualnih informacija…………………………………14
Spisak korištene literature……………………………………………..16
I . Istorija kodiranja informacija
Čovječanstvo koristi šifriranje (kodiranje) teksta od samog trenutka kada su se pojavile prve tajne informacije. Evo nekoliko tehnika kodiranja teksta koje su izmišljene u različitim fazama razvoja ljudske misli:
Kriptografija je kriptografija, sistem mijenjanja pisanja kako bi se tekst učinio nerazumljivim neupućenim osobama;
Morzeov kod ili neuniformni telegrafski kod, u kojem je svako slovo ili znak predstavljeno svojom kombinacijom kratkih elementarnih parcela električna struja(tačke) i elementarne parcele trostrukog trajanja (crtice);
Znakovni jezik je znakovni jezik koji koriste osobe sa oštećenjem sluha.
Jedna od najranijih poznatih metoda šifriranja nosi ime rimskog cara Julija Cezara (1. vijek prije nove ere). Ova metoda se zasniva na zamjeni svakog slova šifriranog teksta drugim pomicanjem abecede od originalnog slova za fiksni broj znakova, a abeceda se čita u krug, odnosno nakon slova i, razmatra se a. Dakle, riječ "bajt" kada se pomakne dva znaka udesno je kodirana riječju "gvlf". Obrnuti proces dešifriranja date riječi je da se svako šifrirano slovo zamijeni drugim lijevo od njega.
II. Kodiranje informacija
Kod je skup konvencija (ili signala) za snimanje (ili prijenos) nekih unaprijed definiranih koncepata.
Kodiranje informacija je proces formiranja određene reprezentacije informacije. U užem smislu, termin "kodiranje" se često shvata kao prelazak sa jednog oblika prezentacije informacija na drugi, pogodniji za skladištenje, prenos ili obradu.
Obično je svaka slika, kada je kodirana (ponekad kažu - šifrirana), predstavljena posebnim znakom.
Znak je element konačnog skupa različitih elemenata.
U užem smislu, termin "kodiranje" se često shvata kao prelazak sa jednog oblika prezentacije informacija na drugi, pogodniji za skladištenje, prenos ili obradu.
Računar može obraditi tekstualne informacije. Kada se unese u kompjuter, svako slovo je kodirano određenim brojem, a kada se iznese na eksterne uređaje (ekran ili print), za ljudsku percepciju, slike slova se grade pomoću ovih brojeva. Korespondencija između skupa slova i brojeva naziva se kodiranjem znakova.
Po pravilu, svi brojevi u računaru su predstavljeni pomoću nula i jedinica (a ne deset cifara, kao što je uobičajeno za ljude). Drugim riječima, računari obično rade u binarnom sistemu, jer su uređaji za njihovu obradu mnogo jednostavniji. Unošenje brojeva u računar i njihovo ispisivanje za ljudsko čitanje može se obaviti u uobičajenom decimalnom obliku, a sve potrebne konverzije izvode programi koji rade na računaru.
III. Kodiranje tekstualnih informacija
Ista informacija se može predstaviti (kodirati) u nekoliko oblika. Pojavom kompjutera postalo je neophodno kodirati sve vrste informacija sa kojima se suočavaju i pojedinac i čovječanstvo u cjelini. Ali čovječanstvo je počelo rješavati problem kodiranja informacija mnogo prije pojave kompjutera. Grandiozna dostignuća čovječanstva - pisanje i aritmetika - nisu ništa više od sistema za kodiranje govora i numeričkih informacija. Informacije se nikada ne pojavljuju čista forma, uvijek je nekako predstavljen, nekako kodiran.
Binarno kodiranje je jedan od najčešćih načina predstavljanja informacija. U računalima, robotima i alatnim strojevima s numeričkom kontrolom, po pravilu, sve informacije s kojima se uređaj bavi kodirane su u obliku riječi binarnog alfabeta.
Od kasnih 1960-ih, kompjuteri se sve više koriste za obradu teksta, a sada većina svjetskih personalnih računara (i večina vrijeme) je zauzet obradom tekstualnih informacija. Sve ove vrste informacija u računaru su predstavljene u binarnom kodu, odnosno koristi se abeceda sa stepenom dva (samo dva znaka 0 i 1). To je zbog činjenice da je zgodno predstaviti informacije u obliku niza električnih impulsa: nema impulsa (0), postoji impuls (1).
Takvo kodiranje se obično naziva binarnim, a sami logički nizovi nula i jedinica nazivaju se mašinskim jezikom.
Sa stanovišta računara, tekst se sastoji od pojedinačnih znakova. Znakovi ne uključuju samo slova (velika ili mala, latinična ili ruska), već i brojeve, znakove interpunkcije, specijalne znakove poput "=", "(", "&", itd., pa čak (obratite posebnu pažnju!) razmake između riječi. .
Tekstovi se unose u memoriju računara pomoću tastature. Tasteri su ispisani poznatim slovima, brojevima, interpunkcijskim znacima i drugim simbolima. Oni ulaze u RAM u binarnom kodu. To znači da je svaki znak predstavljen 8-bitnim binarnim kodom.
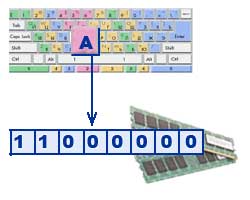 Tradicionalno, za kodiranje jednog znaka koristi se količina informacija jednaka 1 bajtu, tj. I = 1 bajt = 8 bita. Koristeći formulu koja povezuje broj mogućih događaja K i količinu informacija I, možete izračunati koliko različitih znakova može biti kodirano (pod pretpostavkom da su znakovi mogući događaji): K = 2 I = 2 8 = 256, tj. za prikaz tekstualnih informacija, možete koristiti abecedu sa kapacitetom od 256 znakova.
Tradicionalno, za kodiranje jednog znaka koristi se količina informacija jednaka 1 bajtu, tj. I = 1 bajt = 8 bita. Koristeći formulu koja povezuje broj mogućih događaja K i količinu informacija I, možete izračunati koliko različitih znakova može biti kodirano (pod pretpostavkom da su znakovi mogući događaji): K = 2 I = 2 8 = 256, tj. za prikaz tekstualnih informacija, možete koristiti abecedu sa kapacitetom od 256 znakova.
Ovaj broj znakova sasvim je dovoljan za predstavljanje tekstualnih informacija, uključujući velika i mala slova ruske i latinične abecede, brojeve, znakove, grafičke simbole itd.
Kodiranje je da se svakom karakteru dodijeli jedinstven decimalni kod od 0 do 255 ili odgovarajući binarni kod od 00000000 do 11111111. Dakle, osoba razlikuje likove po stilu, a kompjuter po kodu.
Pogodnost bajt-po-bajt kodiranja znakova je očigledna, budući da je bajt najmanji adresabilni dio memorije i stoga procesor može pristupiti svakom karakteru posebno kada obavlja obradu teksta. S druge strane, 256 znakova je sasvim dovoljno za predstavljanje širokog spektra informacija o znakovima.
U procesu prikazivanja znaka na ekranu računara vrši se obrnuti proces - dekodiranje, odnosno pretvaranje koda znaka u njegovu sliku. Važno je da je dodjela specifičnog koda simbolu stvar dogovora, što je fiksirano u tablici kodova.
Sada se postavlja pitanje koji osmobitni binarni kod staviti u korespondenciju sa svakim karakterom. Jasno je da je ovo uslovna stvar, možete smisliti mnogo načina za kodiranje.
Svi znakovi kompjuterske abecede su numerisani od 0 do 255. Svaki broj odgovara osmobitnom binarnom kodu od 00000000 do 11111111. Ovaj kod je jednostavno redni broj znaka u binarnom brojevnom sistemu.
IV . Vrste tablica kodiranja
Tabela u kojoj su svim znakovima kompjuterske abecede dodijeljeni serijski brojevi naziva se tabela kodiranja.
Za različite vrste Računar koristi različite tablice kodiranja.
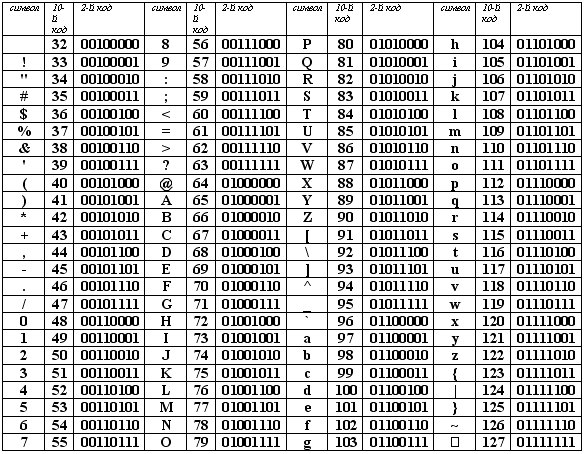
ASCII (American Standard Code for Information Interchange) tablica kodova je usvojena kao međunarodni standard, kodiranje prve polovine znakova numeričkim kodovima od 0 do 127 (kodovi od 0 do 32 nisu dodijeljeni znakovima, već funkcijskim tipkama).
Tabela ASCII kodova podijeljena je na dva dijela.
Samo prva polovina tabele je međunarodni standard, tj. znakova sa brojevima od 0 (00000000) do 127 (01111111).
Struktura ASCII tablice kodiranja
| Serijski broj | Kod | Simbol |
| 0 - 31 | 00000000 - 00011111 | Znakovi sa brojevima od 0 do 31 nazivaju se kontrolni znakovi. Njihova funkcija je kontrola procesa prikazivanja teksta na ekranu ili štampanja, davanja zvučnog signala, označavanja teksta itd. |
| 32 - 127 | 0100000 - 01111111 | Standardni dio tabele (engleski). Ovo uključuje mala i velika slova latinice, decimalne cifre, znakove interpunkcije, sve vrste zagrada, komercijalne i druge simbole. Znak 32 je razmak, tj. prazna pozicija u tekstu. Sve ostalo odražavaju se određenim znacima. |
| 128 - 255 | 10000000 - 11111111 | Alternativni dio tabele (ruski). Druga polovina tabele kodova ASCII, nazvana kodna stranica (128 kodova, počevši sa 10000000 i završavajući sa 11111111), može imati različite opcije, svaka opcija ima svoj broj. Kodna stranica se prvenstveno koristi za smještaj nacionalnih pisama osim latinice. U ruskim nacionalnim kodovima, znakovi ruskog alfabeta nalaze se u ovom dijelu tabele. |
Prva polovina tabele ASCII kodova
Skreće se pažnja na činjenicu da su u tablici kodiranja slova (velika i mala) raspoređena abecednim redom, a brojevi rastućim redoslijedom. Ovo poštovanje leksikografskog reda u rasporedu znakova naziva se princip sekvencijalnog kodiranja abecede.
Za slova ruske abecede također se poštuje princip sekvencijalnog kodiranja.
Druga polovina tabele ASCII kodova
Nažalost, trenutno postoji pet različitih ćiriličkih kodiranja (KOI8-R, Windows. MS-DOS, Macintosh i ISO). Zbog toga često nastaju problemi sa prenosom ruskog teksta sa jednog računara na drugi, iz jednog softverskog sistema u drugi.
Hronološki, jedan od prvih standarda za kodiranje ruskih slova na računarima bio je KOI8 („Kod za razmenu informacija, 8-bitni“). Ovo kodiranje je korišćeno još 70-ih godina na računarima serije računara EC, a od sredine 80-ih počelo je da se koristi u prvim rusifikovanim verzijama UNIX operativnog sistema.
Od početka 90-ih, vremena dominacije operativnog sistema MS DOS, kodiranje ostaje CP866 („CP“ znači „Code Page“, „code page“).
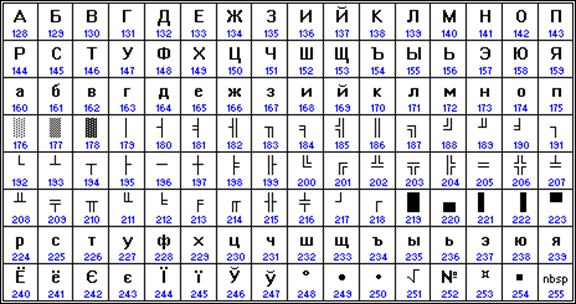
Apple računari koji koriste Mac OS operativni sistem koriste vlastito Mac kodiranje.

Pored toga, Međunarodna organizacija za standardizaciju (International Standards Organization, ISO) odobrila je još jedno kodiranje pod nazivom ISO 8859-5 kao standard za ruski jezik.
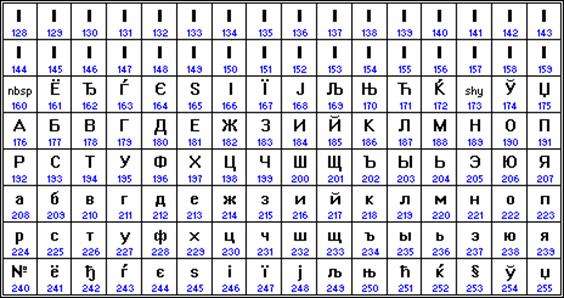
Najčešći kodiranje koje se trenutno koristi je Microsoft Windows, skraćeno CP1251. Uveo Microsoft; uzimajući u obzir rasprostranjena operativni sistemi(OS) i drugih softverskih proizvoda ove kompanije u Ruska Federacija postalo je široko rasprostranjeno.
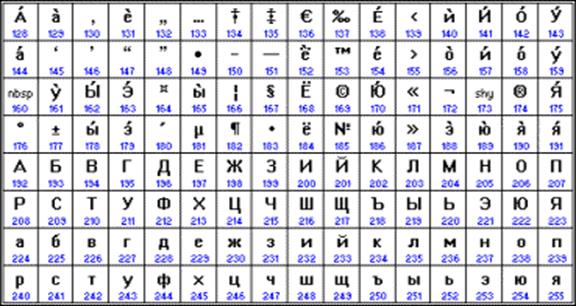
Od kasnih 90-ih, problem standardizacije kodiranja znakova riješen je uvođenjem novog međunarodnog standarda pod nazivom Unicode.
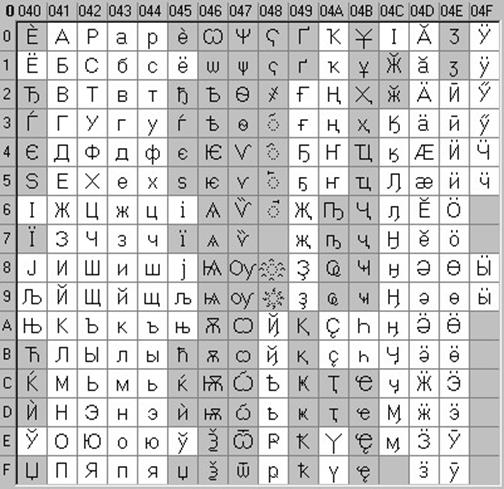
Ovo je 16-bitno kodiranje, tj. ima 2 bajta memorije po karakteru. Naravno, u ovom slučaju, količina zauzete memorije se povećava za 2 puta. Ali takva kodna tabela omogućava uključivanje do 65536 znakova. Kompletna specifikacija Unicode standarda uključuje sve postojeće, izumrle i umjetno stvorene alfabete svijeta, kao i mnoge matematičke, muzičke, hemijske i druge simbole.
Interno predstavljanje riječi u memoriji računara
koristeći ASCII tablicu
Ponekad se dešava da se tekst, koji se sastoji od slova ruske abecede, primljen sa drugog računara, ne može pročitati - na ekranu monitora je vidljiva neka vrsta "abrakadabre". To je zbog činjenice da računari koriste različita kodiranja znakova ruskog jezika.
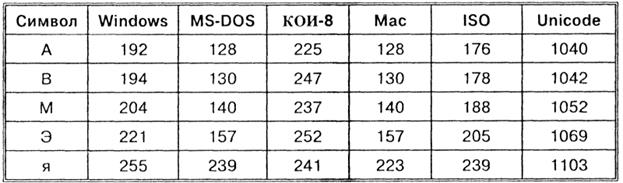
Dakle, svako kodiranje je specificirano svojom vlastitom tablicom kodova. Kao što se može vidjeti iz tabele, isti binarni kod u razna kodiranja dodijeljeni su različiti simboli.
 Na primjer, niz numeričkih kodova 221, 194, 204 u CP1251 kodiranju formira riječ "kompjuter", dok će u drugim kodovima to biti besmislen skup znakova.
Na primjer, niz numeričkih kodova 221, 194, 204 u CP1251 kodiranju formira riječ "kompjuter", dok će u drugim kodovima to biti besmislen skup znakova.
Na sreću, u većini slučajeva korisnik ne mora da brine o transkodiranju tekstualnih dokumenata, jer se to radi pomoću posebnih programa konvertera ugrađenih u aplikacije.
V . Proračun količine tekstualnih informacija
Zadatak 1: Kodirajte riječ "Rim" pomoću tablica kodiranja KOI8-R i CP1251.
Rješenje:

Zadatak 2: Uz pretpostavku da je svaki znak kodiran jednim bajtom, procijenite količinu informacija sljedeće rečenice:
“Moj ujak najpoštenijih pravila,
Kad sam se ozbiljno razbolio,
Natjerao je sebe da poštuje
I nisam mogao smisliti bolji."
Rješenje: U ovoj frazi ima 108 znakova, uključujući znakove interpunkcije, navodnike i razmake. Ovaj broj množimo sa 8 bita. Dobijamo 108*8=864 bita.
Zadatak 3: Dva teksta sadrže isti broj znakova. Prvi tekst je napisan na ruskom, a drugi na jeziku plemena Naguri, čija se abeceda sastoji od 16 znakova. Čiji tekst nosi više informacija?
Rješenje:
1) I \u003d K * a (obim informacija teksta jednak je proizvodu broja znakova i težine informacija jednog znaka).
2) Jer oba teksta imaju isti broj znakova (K), tada razlika zavisi od informativnog sadržaja jednog znaka abecede (a).
3) 2 a1 = 32, tj. a 1 = 5 bita, 2 a2 = 16, tj. i 2 = 4 bita.
4) I 1 = K * 5 bita, I 2 = K * 4 bita.
5) To znači da tekst napisan na ruskom jeziku nosi 5/4 puta više informacija.
Zadatak 4: Obim poruke, koja je sadržavala 2048 karaktera, iznosila je 1/512 MB. Odredite snagu abecede.
Rješenje:
1) I = 1/512 * 1024 * 1024 * 8 = 16384 bita - količina informacija poruke je pretvorena u bitove.
2) \u003d I / K \u003d 16384 / 1024 \u003d 16 bita - pada na jedan znak abecede.
3) 2*16*2048 = 65536 znakova - snaga korišćene abecede.
Zadatak 5: Canon LBP laserski štampač štampa prosečnom brzinom od 6,3 Kbps. Koliko će vremena biti potrebno za štampanje dokumenta od 8 stranica ako se zna da na jednoj stranici ima u prosjeku 45 redova, 70 znakova po redu (1 karakter - 1 bajt)?
Rješenje:
1) Pronađite količinu informacija sadržanih na 1 stranici: 45 * 70 * 8 bita = 25200 bita
2) Pronađite količinu informacija na 8 stranica: 25200 * 8 = 201600 bita
3) Dovodimo do uniformnih mjernih jedinica. Da bismo to učinili, prevodimo Mbps u bitove: 6,3 * 1024 = 6451,2 bps.
4) Pronađite vrijeme ispisa: 201600: 6451,2 = 31 sekunda.
Bibliografija
1. Ageev V.M. Teorija informacija i kodiranja: diskretizacija i kodiranje mjernih informacija. - M.: MAI, 1977.
2. Kuzmin I.V., Kedrus V.A. Osnove teorije informacija i kodiranja. - Kijev, škola Vishcha, 1986.
3. Najjednostavniji načini šifriranja teksta / D.M. Zlatopolsky. - M.: Chistye Prudy, 2007 - 32 str.
4. Ugrinovich N.D. Informatika i informacione tehnologije. Udžbenik za 10-11 razred / N.D. Ugrinovich. – M.: BINOM. Laboratorij znanja, 2003. - 512 str.
5. http://school497.spb.edu.ru/uchint002/les10/les.html#n
KODIRANJE INFORMACIJA
KODIRANJE INFORMACIJA
Uspostavljanje korespondencije između elemenata poruke i signala, uz pomoć kojih se oni mogu popraviti.
Neka IN, ,
- mnogo elemenata poruke, a abeceda sa simbolima , Neka se zove konačan niz simbola. riječ na ovoj abecedi. Mnogo reči u abecedi A pozvao kod ako se stavlja u korespondenciju jedan-na-jedan sa skupom IN. Svaka riječ uključena u kod, zove se. kodna riječ. Poziva se broj znakova u kodnoj riječi. dužina reči. Kodne riječi mogu biti iste ili različite. dužina. U skladu sa ovim kodom se zove. ujednačena ili neujednačena.
Ciljevi K. i .: prezentacija ulaznih informacija u, koordinacija izvora informacija sa kanalom za prenos, otkrivanje i ispravljanje grešaka u prenosu i obradi podataka, skrivanje značenja poruke (kriptografija) itd. svojstva objekta su po pravilu takva da se kod može predstaviti na najekonomičniji način. Izvorni koder rješava ovaj problem uklanjanjem suvišnosti iz poruka. Dalje faze prolaska podataka - prijenos preko kanala za prijenos i (ili) pohranjivanje u memorijske uređaje - zahtijevaju otkrivanje i (ili) ispravljanje grešaka koje se u njima javljaju zbog smetnji. Ovi ciljevi se postižu korektivnim kodiranjem koje izvodi autor kanala. Konačno, informacije od izobličenja tokom obrade u računaru se izvode pomoću aritmetike. kodovi.
Value Encoding. Prirodni broj N predstavljeno u pozicionom težinskom brojevnom sistemu, ako se relacija odvija

gdje je digitalna abeceda sa P cifre, " - težine cifara, - brojevi cifara. Termin "pozicioni" znači da je u kodnom prikazu (ili samo kod) broja izražen uslovnom jednakošću
kvantitativni ekvivalent povezan sa slikom a l, ovisi o njegovoj lokaciji u kodu. Izraz "značajan" znači da svaka znamenka ima pl. Mala težina narudžbe p 0 u digitalnoj mjernoj tehnologiji poistovjećuje se sa rezolucijom analogno-digitalne konverzije. Izbor abecede A i sistemi za vaganje R specificira klasifikaciju pozicionih brojevnih sistema (kodiranje vrijednosti). U prirodnim sistemima
i ako n- osnova brojevnog sistema - prirodan broj, bilo koji broj X može se predstaviti kao
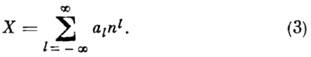
Odabir abecede pomaknut: A= (0, 1, . . ., P-1), A=(-n- 1, . . ., 1, 0), ili simetrično: A = (-p- 1, . . ., -1, 0, 1, . . ., P- 1) omogućava vam predstavljanje pozitivnih, negativnih ili bilo kojih brojeva. Simetrični sistem mora imati neparnu bazu.
Računar skoro isključivo koristi pozicioni binarni offset sistem (n = 2) sa brojevima (0, 1) i prirodnim omjerom težina koji predstavlja niz brojeva
Na primjer, moguće je koristiti drugačiji skup brojeva. (-1, 1), dajući neke specifične prednosti.
Razvijaju se binarni sistemi čije težine cifara nisu u prirodnom (2), već u složenijem omjeru, formirajući, na primjer, Fibonačijev niz (ili "zlatni omjer"). Broj N u Fibonačijevom kodu je predstavljen omjerom
gdje su Fibonačijevi brojevi povezani relacijom
Broj dekompozicije (4). N dvosmisleno. Za bilo koga N postoji kod u kojem se ne pojavljuju dvije uzastopne nule, kao i kod u kojem jedinice ne postoje. Ove, kao i druge strukturne karakteristike Fibonačijevih kodova i "zlatnih" kodova, čine ih pogodnim za izgradnju samoispravljajućih pretvarača koji pohranjuju i izračunavaju. uređaji, digitalno upravljani servo pogoni, itd.
Ternarni sistemi brojeva naib. su ekonomični u smislu da je u ternarnom kodu def. Broj znakova može izraziti najveću raznolikost brojeva. Postoji razlog za vjerovanje da će u budućnosti, upravo zbog ovog svojstva, ternarni simetrični sistem kodiranja s brojevima (-1, 0, 1) uzeti u obzir. tehnologija dominira. Problem ostaje stvaranje elemenata koji implementiraju osnovne funkcije u ternarnoj logici: ternarni pretvarač i ternarni NAND ili ternarni NOR (vidi. Logika),
Nepozicioni kodovi se koriste u specijalizovanim merenjima. i izračunaj. uređaji. Najjednostavniji od nepozicionih - unitarni kod se može dobiti unošenjem (2) n=1 i p 0=1. Ima broj N pojavljuje se kao N=n+l - sekvencijalno zbrojene jedinice. Ovako, na primjer, rade brojači impulsa.
Među nepozicionim sistemima kodiranja ističe se sistem brojeva u rezidualnim klasama (RNS). Broj N u RNS je predstavljen kao uređeni skup ostataka (ostataka) na koprimenim bazama p1, . . ., r p;, gdje je najmanji ostatak N modulo R. Sistem temelja p 1, p 2, . . ., r p definira opseg reprezentacije brojeva P=p 1 , p 2 , . . ., r p U aritmetici ZSK. operacije se izvode nezavisno za svaku osnovu, a to vam omogućava da značajno povećate njihov učinak. U RNS-u je zgodno kontrolisati operacije, jer su greške lokalizovane unutar baza. Specifičan proračun. Uređaji koji rade u SOC-u je upotreba tabelarne aritmetike: vrijednosti funkcije koje treba izračunati se unose u tablicu unaprijed, a zatim se preuzimaju kada stignu vrijednosti operanada.
Efikasno kodiranje izvora informacija ima za cilj da uskladi svojstva informacija izvora informacija (IS) sa kanalom za prijenos. AI bi trebao isporučiti , koji se sastoji od slova m-slovna abeceda
štaviše, izgled slova je statistički nezavisan i podložan distribuciji
Izvor karakterizira entropija po simbolu
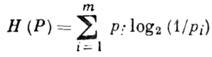
Entropija ![]() ima značenje nesigurnosti u pogledu pojave sljedećeg karaktera na AI izlazu. Jednakost H(P)=0 postiže se degeneriranom distribucijom R, jer poruka
ima značenje nesigurnosti u pogledu pojave sljedećeg karaktera na AI izlazu. Jednakost H(P)=0 postiže se degeneriranom distribucijom R, jer poruka
dok je deterministički; jednakost ![]() postiže se ravnovjerovatnim pojavljivanjem - situacija najveće neizvjesnosti. Sa m=2 i ujednačenim izgledom slova a 1 I a 2 entropija je maksimalna i H(P) = 1. Ova vrijednost - nesigurnost sa jednako vjerovatnim izborom dvije alternative - koristi se kao jedinica entropije - 1.
postiže se ravnovjerovatnim pojavljivanjem - situacija najveće neizvjesnosti. Sa m=2 i ujednačenim izgledom slova a 1 I a 2 entropija je maksimalna i H(P) = 1. Ova vrijednost - nesigurnost sa jednako vjerovatnim izborom dvije alternative - koristi se kao jedinica entropije - 1.
Svaki metod kodiranja karakterizira cf. broj L(P) slova izlazne abecede po jednom slovu ulazne abecede I t. Za alfabetsko kodiranje ![]() - dužina riječi u abecedi U r. Ako je kodiranje jedan prema jedan, onda
- dužina riječi u abecedi U r. Ako je kodiranje jedan prema jedan, onda
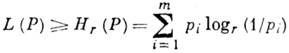
Vrijednost I (P) = L(P)-H r (P) pozvao redundantnost kodiranja u distribuciji R. Problem je pronaći, u datoj klasi kodiranja jedan-na-jedan, kodiranje koje ima min. magnitude I(P). Postojanje minimuma i njegova vrijednost utvrđeni su Šenonovom teoremom za kanal bez šuma, koji kaže da je za izvor sa konačnim alfabetom A t sa entropijom H(P) može se dodijeliti kodne riječi slovima izvora na način da up. dužina kodne riječi L (P) će zadovoljiti uslove
Optimalni kod je takav da nijedan drugi kod neće dati manju vrijednost L(P).
Konstruktivni postupak za pronalaženje optimalnog. D. R. Huffman je 1952. predložio kod za kodiranje datog skupa poruka. Ideja je da slova abecede A t su poredane po i kraće kodne riječi su dodijeljene vjerovatnijim. Huffman kod ima . svojstva: riječ koja odgovara najmanje vjerovatnoj poruci ima najveću dužinu; dvije najmanje vjerovatne poruke su kodirane riječima iste dužine, od kojih se jedna završava na nulu, a druga na jednu (r=2).
Optimalno uniformno kodiranje. Neka izvor bude sa abecedom od dva slova i generira riječi dužine l. S obzirom na ceo set od 2 l riječi (izvorni rječnik) postoji izjava koja je za i dovoljno velika l izvorni rečnik je podeljen na dva podskupa: grupu podjednako verovatnih reči (radni izvorni rečnik) i grupu reči sa ukupnom verovatnoćom bliskom nuli ("atipične" sekvence). Evo H(R) - entropija po izvornom simbolu. Udio riječi u radnom rječniku je vrlo mali i raste l teži nuli. Ideja ujednačenog ili blokovnog kodiranja je da koder, primajući izvorne riječi kao ulaz, uparuje kodne riječi samo s riječima iz radnog rječnika, a sve ostalo kodira jednom riječju koja ima značenje greške. Vjerovatnoća greške može se proizvoljno smanjiti povećanjem dužine izvorne riječi. U ovom slučaju, volumen kodiranih riječi zahtijeva simbole kodne riječi. Budući da su riječi radnog rječnika gotovo jednako vjerovatne, kodne riječi će biti jednako vjerovatne, a entropija po simbolu kodne riječi će biti blizu 1 bit. Koder, dakle, proizvodi riječi dužine, štedeći zbog činjenice da "učitava" svaki znak do maksimalnog mogućeg informacionog opterećenja od 1 bita.
Izvorno kodiranje dobija novo značenje zbog potrebe da se "komprimiraju" informacijski nizovi podataka u bazama podataka i bankama podataka. Nizovi organizacionih, ekonomskih, mjernih. informacije imaju tako veliku redundantnost da dozvoljavaju i do 80-85%. Razvijeni sistemi za upravljanje bazama podataka (DBMS) imaju posebne. programi (uslužni programi) za analizu, kompresiju i vraćanje teksta, koji rade na principima koji su gore navedeni.
Korektivno kodiranje informacija. Njegova svrha je da otkrije i (ili) ispravi greške u kodnim riječima koje su nastale tokom prijenosa informacija preko bučnog kanala. Korekcija izobličenja je moguća uvođenjem redundancije u prenosni sistem. U ovom slučaju, iz cijelog skupa riječi kodera kanala N0 samo Nće odgovarati poslanim porukama (dozvoljene riječi). Teoretski, u ovom slučaju, udio otkrivenih grešaka neće premašiti 1-N/N 0 .
Pretpostavlja se da je informativna riječ U= (u 1, . . ., u n), gdje u j=0, 1 se dovodi na ulaz kanalnog enkodera (u daljem tekstu enkoder), koji mu dodeljuje kodnu reč X (x 1 , . .., xl), ,
Koder, dakle, dodaje po definiciji. pravilo za riječ U grupa od k=l-n redundantni (korektivni) bitovi. Šifra X ulazi u kanal sa šumom, gdje smetnje iskrivljuju neke od simbola x i . Riječ primljena na izlazu kanala Y= (u 1 , . . ., y 2) ulazi u dekoder, koji vraća (sa aproksimacijom visine tona) riječ x. Kodnim riječima se operiše kao vektori u linearnom vektorskom prostoru s Hamingovom metrikom koja određuje udaljenost između vektora
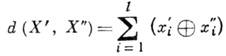
Šenonova teorema za bučne kanale, koja kaže da je uz pomoć odgovarajućih kodova moguće prenijeti informacije tako da je vjerovatnoća greške nakon dekodiranja proizvoljno mala, pod uslovom da brzina prijenosa ne prelazi širinu propusnog opsega komunikacijskog kanala, nije konstruktivna: ne ukazuje na način da se napravi kod. Prilikom konstruisanja koda od presudnog je značaja izbor modela za pojavu grešaka u prenošenoj reči.
Naib. široko je rasprostranjen model simetričnog kanala sa jednako vjerovatnim dekompcijom grešaka. vrste - prijelazi, na primjer, znak 0 do 1 i 1 do 0.
Model kanala "sa brisanjem" je specifičan. Izlazna abeceda takvog kanala sadrži posebne. simbol za brisanje, u koji se znakovi ulazne abecede prenose kada se pojavi greška ovog tipa.
Prošireni dif. pretpostavke o distribuciji grešaka u prenesenom nizu simbola (kodna riječ). Model nezavisnih grešaka (kanal bez memorije), model grupisanih grešaka (napadi grešaka), greške locirane na određenom udaljenosti jedna od druge, itd. Postoje široko rasprostranjene pretpostavke o ograničenju brojnosti grešaka u kodnim riječima.
Pod posljednjom pretpostavkom, korektivna sposobnost koda se procjenjuje brojem otkrivenih i (ili) ispravljenih grešaka uz pomoć kodnih riječi. Pretpostavlja se da u kanalu sa X zbirni (mod 2) vektor šuma simbol po simbol Z, formiranje reči. Višestrukost rezultirajuće greške je ista kao i broj jedinica (Hamming težina) u Z. U vektoru iz l elemenata ne više od r jedinice se mogu postaviti na načine.
Ovo je niz grešaka koje se mogu pojaviti tokom prijenosa.
Glavna karakteristika koda, koja određuje njegovu korektivnu sposobnost u odnosu na nezavisne greške, je kodna udaljenost. Udaljenost koda je najmanja Hamingova udaljenost između svih mogućih riječi = ( , . . ., ) i koda. Kako bi kod otkrio sve kombinacije s greške i ispravljene sve kombinacije t greške, potrebno je i dovoljno da kodna udaljenost bude jednaka s+t+1.
Široka klasa kodova za simetrični kanal su linearni (grupni) kodovi, na primjer, Hamingovi kodovi, koji se široko koriste za zaštitu informacija u glavnoj memoriji računara. Hamingov kod ima kodnu udaljenost d=3, ispravlja pojedinačne greške i otkriva dvostruke greške. Ima kontrolne cifre smještene na pozicijama označenim brojevima 2°, 2, 2 2 , . . . Linearni kod je dat parom matrica: generiranje , , i provjera . Redovi generirajuće matrice su linearno nezavisni vektori koji čine osnovu prostora koji sadrži 2 n elemenata - kodnih riječi. Svaki od redova matrice za provjeru je ortogonan na redove , , i
Linijski koder generira kodne riječi prema pravilu X T = U T G. Model distorzije pretpostavlja da je u kanalu sa X sumirani vektor šuma simbol po simbol Z, formiranje reči Y=X+Z.
Ideja dekodiranja je formiranje proizvoda S T \u003d Y T H T, zove sindrom. Jednakost S= 0 znači da Z=0, ili je greška neotkrivena. Sindrom ima 2 k -1 nenulte realizacije, od kojih se svaka može koristiti da ukaže na grešku koja se dogodila.
Cyclic. kodovi su uključeni kao podklasa u grupnim kodovima. U njima, zajedno sa riječju X i sav njegov ciklus-lich ulazi. permutacije. Kodne riječi se formiraju kao proizvod dva polinoma: U (E) stepen P- 1, koeficijent to-rogo čine informativnu riječ u, i generativno g (E) stepen l-p, nesvodljiv i djeljiv bez binoma ostatka (1+ E l). Dekodiranje se sastoji u dijeljenju primljene riječi (polinoma). g(E). Prisustvo ostatka različitog od nule ukazuje na prisustvo greške. Cyclic. kodovi su obično nesistematski.
Specijalista. ciklično kodovi su dizajnirani za otkrivanje i ispravljanje nizova grešaka, na primjer, kodovi požara, definirani generiranjem polinoma oblika g(E) = =p(E)(E c +1), Gdje p(E) - nesvodljivi polinom i količina With određuje se dužinom ispravljenih i otkrivenih nizova grešaka.
Hrpe grešaka su tipične za magnetne uređaje za skladištenje. nosači, posebno za magnetne pogone. diskovi (NMD) moderni. kompjuter (vidi memorija uređaja). Za zaštitu podataka u NMD, dakle, K. se i široko koristi. ciklično kodovi implementirani hardverom.
Aritmetički kodovi dizajniran za otkrivanje grešaka koje su se dogodile tokom izvršavanja aritmetike. kompjuterske operacije. U teoriji aritmetike. kodiranja, uvode se koncepti težine, udaljenosti i greške, koji se razlikuju od Hamingovih. Aritmetika težina broja je definirana kao min. broj pojmova u predstavljanju broja u obliku , ![]() . Greške, zbog kojih se veličina broja mijenja za, r "= 0, 1, 2, . . ., nazivaju se aritmetički. Aritmetička udaljenost između N 1 I N 2 - aritmetika težina razlike jednaka je višestrukosti greške koja prevodi broj N 1 V N2, i određuje aritmetiku korektivnih sposobnosti. kod je sličan Hamingovoj udaljenosti.
. Greške, zbog kojih se veličina broja mijenja za, r "= 0, 1, 2, . . ., nazivaju se aritmetički. Aritmetička udaljenost između N 1 I N 2 - aritmetika težina razlike jednaka je višestrukosti greške koja prevodi broj N 1 V N2, i određuje aritmetiku korektivnih sposobnosti. kod je sličan Hamingovoj udaljenosti.
Zajedničko AN- kodiranje brojeva N- operand - izvodi se množenjem sa posebno odabranim faktorom A. Dakle, 3A kod, koji ima kodnu udaljenost od 2, detektuje pojedinačne greške dijeljenjem sume sa 3. Greške se detektuju sa ostatkom koji nije nula: aritmetičkom vrijednošću. greške 2 i nije ni deljiv sa 3. Osim pojedinačnih grešaka, kod A=3 se nalazi i dio dvostrukih grešaka - onih za koje tačan i pogrešan rezultat ima neusklađene ostatke nakon dijeljenja sa 3.
Kriptografija se vrši zamjenom, kada se svakom slovu šifrirane poruke dodjeljuje određeno. znak (npr. drugo slovo), bilo permutacijom, kada se slova unutar vještačkih blokova teksta zamjenjuju, ili kombinacijom ovih metoda. Shannon je pokazao da su mogući kriptogrami koji se ne mogu dešifrirati za prihvatljivu .
Lit.: 1) Stakhov A.P., Uvod u algoritamsku teoriju merenja, M., 1977; svoje, Kodovi zlatnog omjera, M., 1984; 2) Akushsky I., Yuditsky D., Mašinska aritmetika u rezidualnim klasama, Moskva, 1968; 3) Gal-lager R., Teorija informacija i pouzdane komunikacije, trans. sa engleskog, M., 1974; 4) Dadaev Yu.G., Teorija aritmetičkih kodova, M., 1981; 5) Aršinov M. N., Sadovski L. E., Kodovi i matematika, Moskva, 1983. L. N. Efimov.
Fizička enciklopedija. U 5 tomova. - M.: Sovjetska enciklopedija. Glavni i odgovorni urednik A. M. Prokhorov. 1988 .
Pogledajte šta je "KODIRANJE INFORMACIJA" u drugim rječnicima:
kodiranje informacija- Proces transformacije i (ili) predstavljanja podataka. [GOST 7.0 99] Teme aktivnosti biblioteke informacija EN kodiranje informacija FR codage de l'information ... Priručnik tehničkog prevodioca